强化学习会使模型变谄媚OpenAI技术报告谈GPT变谄媚原因
GPT-4o更新后“变谄媚”?后续技术报告来了。
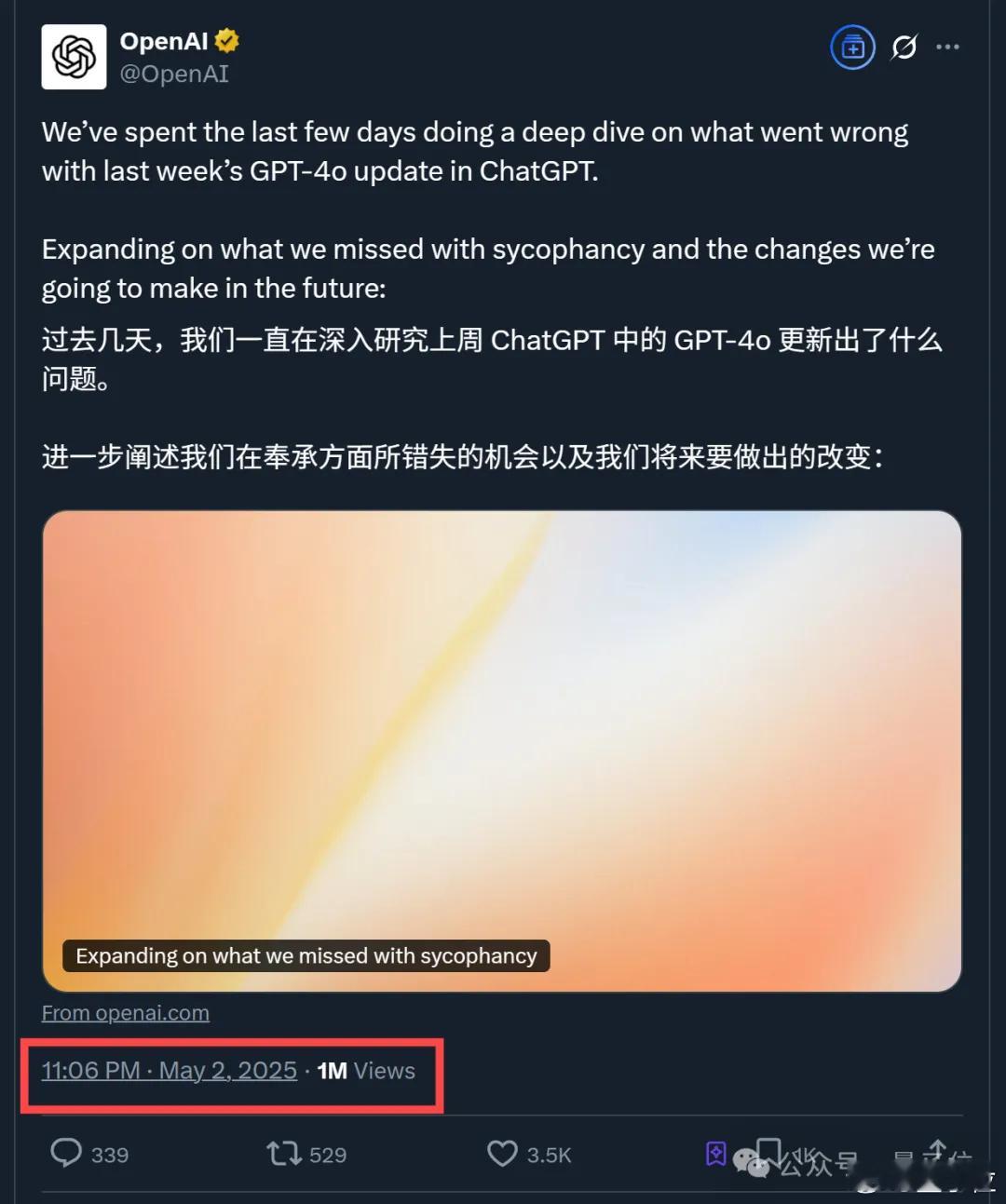
OpenAI一篇新鲜出炉的认错小作文,直接引来上百万网友围观。【图1】
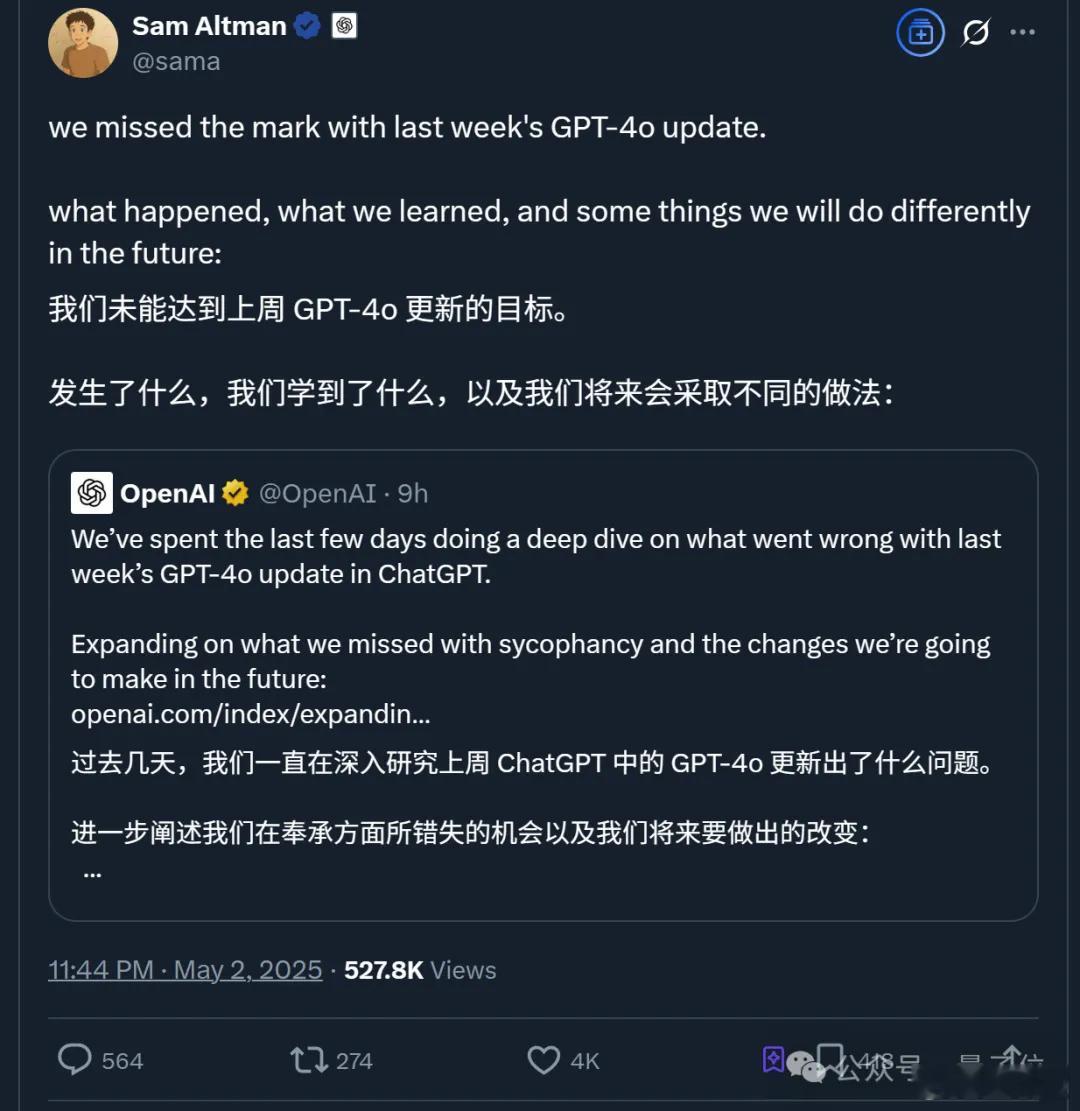
CEO奥特曼也做足姿态,第一时间转发小作文并表示:
(新报告)揭示了GPT-4o更新失败是因为什么,从中OpenAI学到了什么,以及我们将会采取的应对措施是什么。【图2】
概括而言,最新报告提到,大约一周前的bug原来出在了“强化学习”身上——
上次更新引入了一个基于用户反馈的额外奖励信号,即对ChatGPT的点赞或点踩。
虽然这个信号通常很有用,但可能使模型逐渐倾向于做出更令人愉快的回应。
此外,尽管还没有明确证据,但用户记忆在某些情况下也可能加剧奉承行为的影响。
一言以蔽之,OpenAI认为一些单独看可能对改进模型有益的举措,结合起来后却共同导致了模型变得“谄媚”。
而在看到这篇报告后,目前大多数网友的反应be like:
(你小汁)认错态度不错~【图3】
甚至有人表示,这算得上OpenAI过去几年里最详细的报告了。【图4】
具体咋回事儿?接下来一起吃瓜: