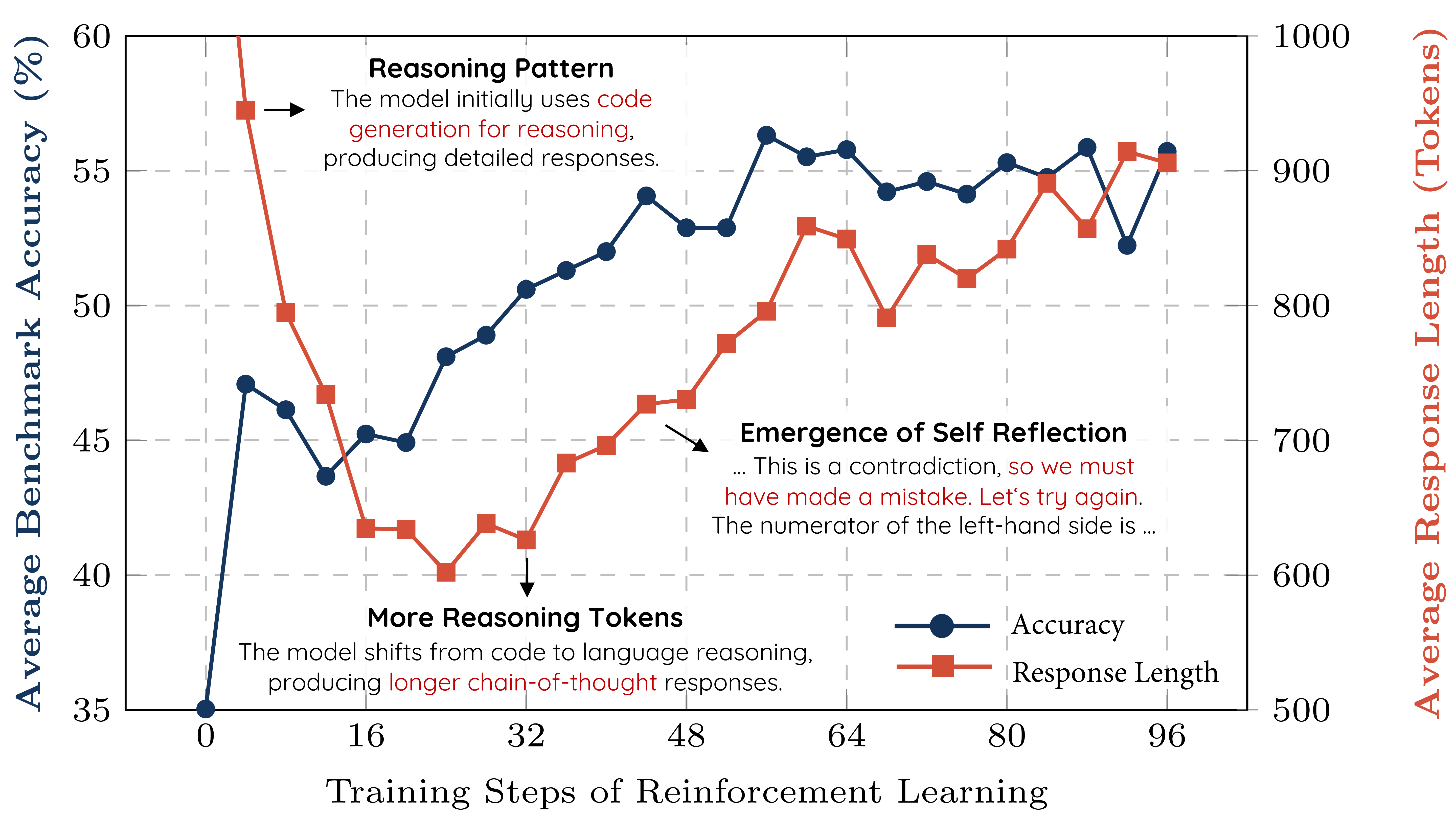
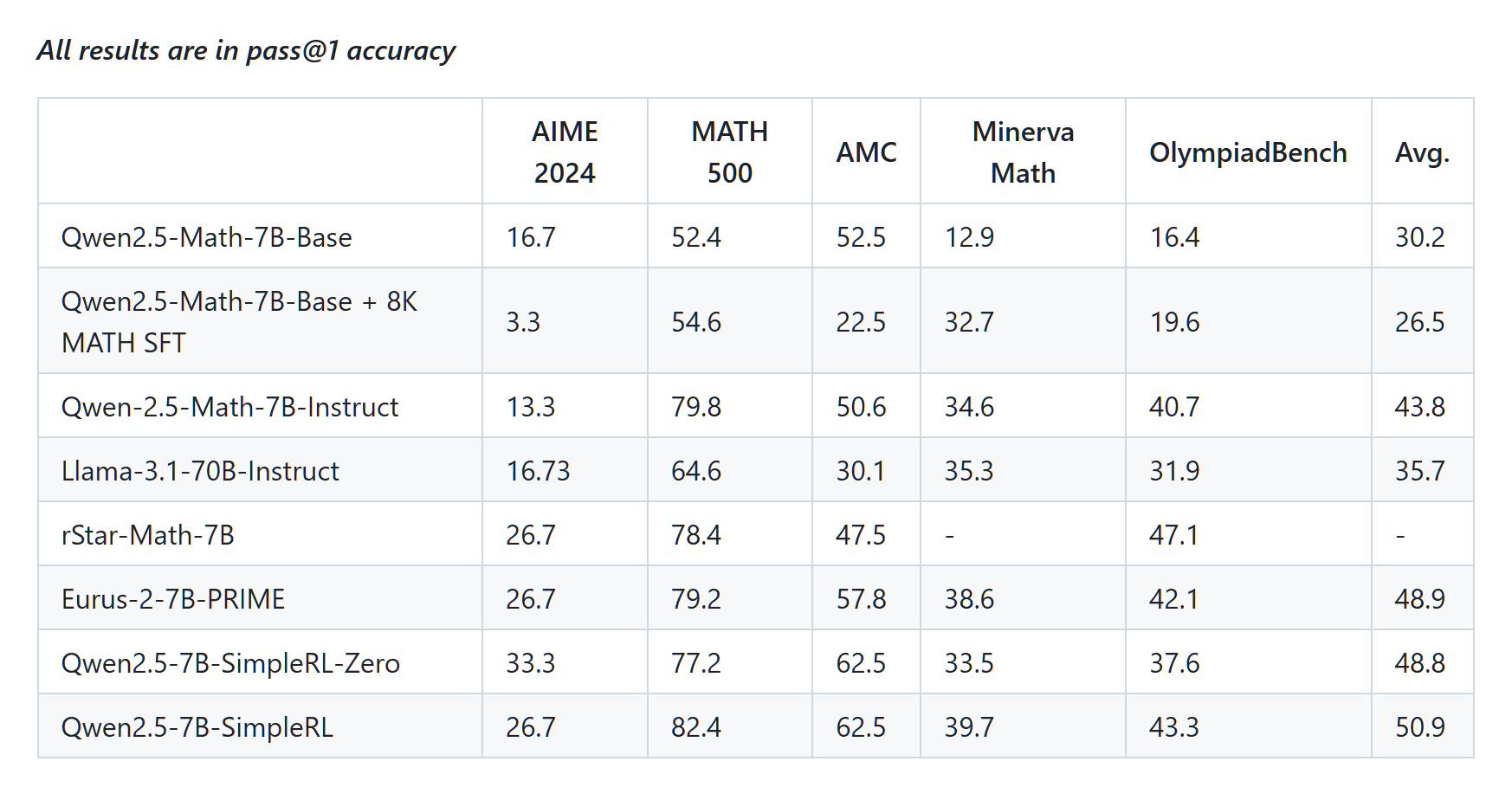
SimpleRL-reason:又是一个复现DeepSeek-R1-Zero 和 DeepSeek-R1的项目,香港科技大学自然语言处理实验室出品。也证明了R1论文披露的训练方法很有效。
github.com/hkust-nlp/simpleRL-reason
“我们尝试复现DeepSeek-R1-Zero和DeepSeek-R1的数学推理训练流程,以Qwen-2.5-Math-7B(基础模型)为起点,仅使用原始MATH数据集中的8,000条(问题,最终答案)样本进行实验。令人惊讶的是,这8,000条样本在无额外信号的情况下显著提升了7B模型的性能”
“Qwen2.5-7B-SimpleRL-Zero(直接在基础模型上使用8K MATH样本进行强化学习)相比基础模型平均提升近20个百分点,甚至超越Qwen-2.5-Math-7B-Instruct,并与最新发布的Eurus-2-7B-PRIME和rStar-Math-7B(均基于Qwen-2.5-Math-7B)性能相当。值得注意的是,这些基线模型使用了更复杂的组件(如奖励模型)和至少50倍以上的数据量”
其他项目参见这条: