现在大模型的基准测试名字花样也越来越多了。scale发布了一个叫“人类的最后一测” Humanity's Last Exam (HLE) 的全新多模态基准测试。(名字似乎不太吉利 [汗] )
搞这个的原因是现有的基准测试(如 MMLU)已经趋于饱和(这话这几年也很耳熟了),LLM 在这些测试中可以达到超过 90% 的准确率,这使得它们无法有效评估最先进的 LLM 能力。所以他们提高了难度,在这个测试里100分的题目前的大模型还没有能得分超过10分的。。
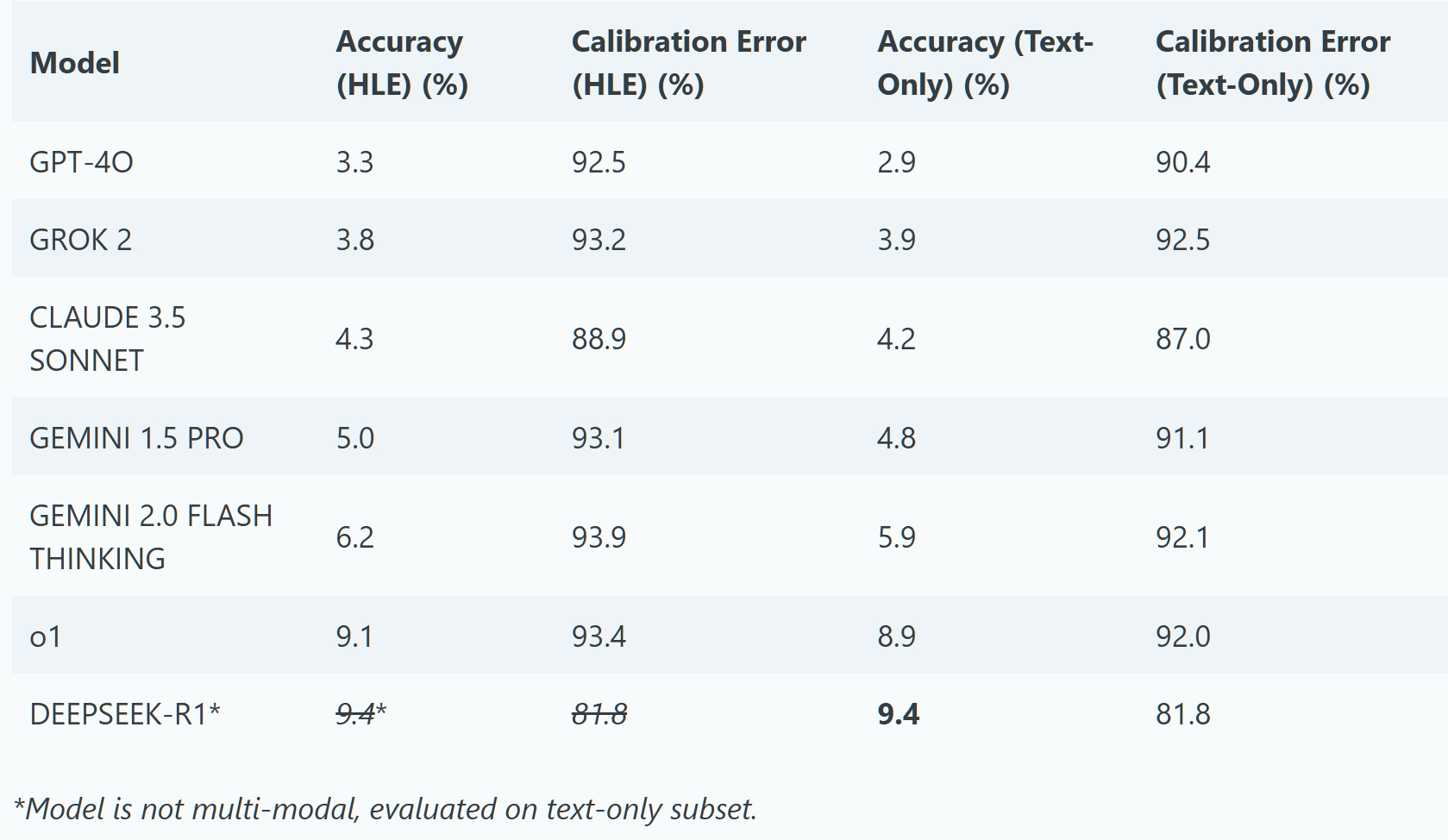
目前得分最高的是DeepSeek-R1,不过因为其不支持多模态,只在文本子集里做了测试。