Kimi也发布了自己的 k1.5 推理模型。目前还没有上线到kimi产品上,不过kimi的论文里细节也比较多,可以先看下论文:
github.com/MoonshotAI/Kimi-k1.5/blob/main/Kimi_k1.5.pdf
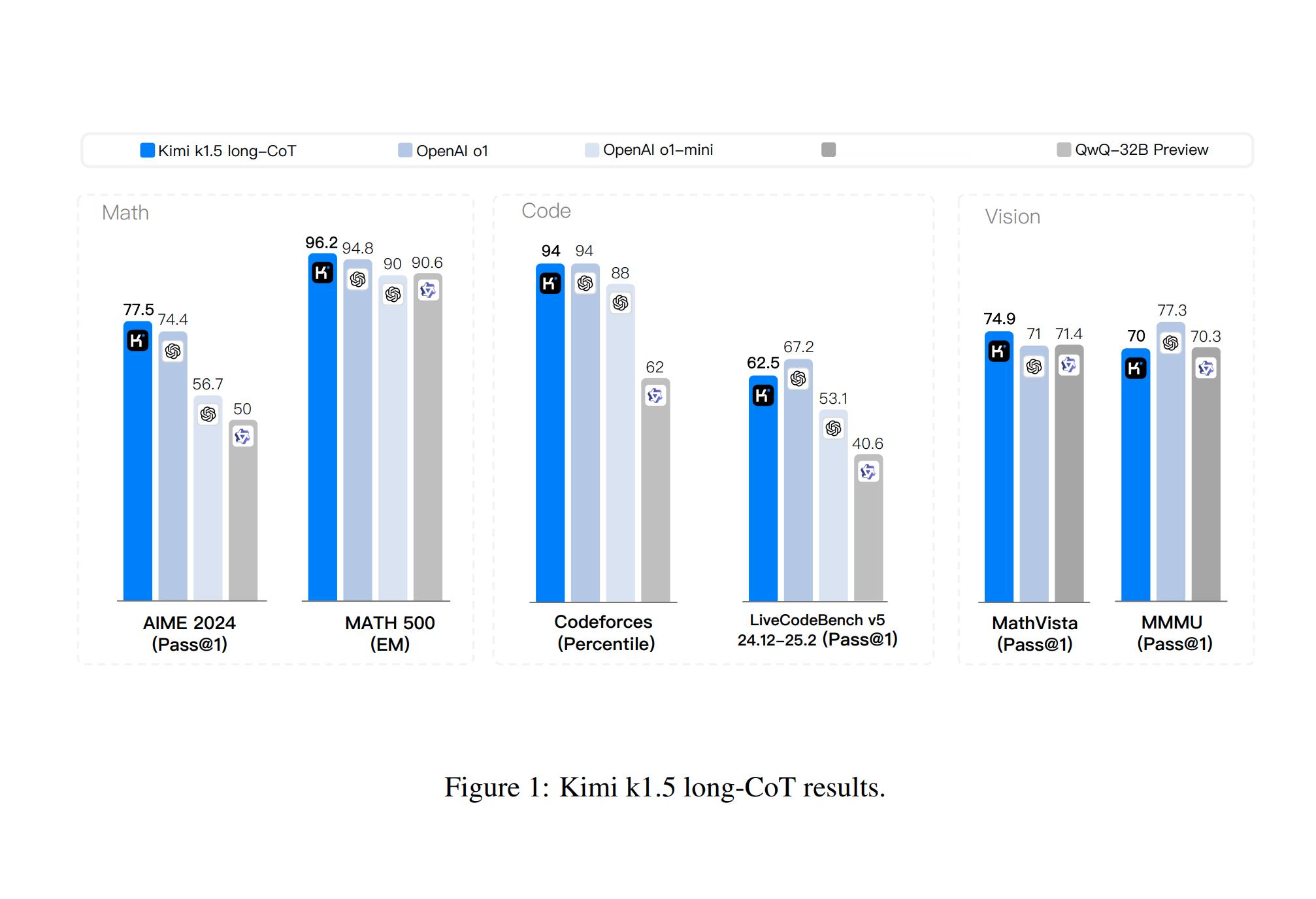
图1为跑分。
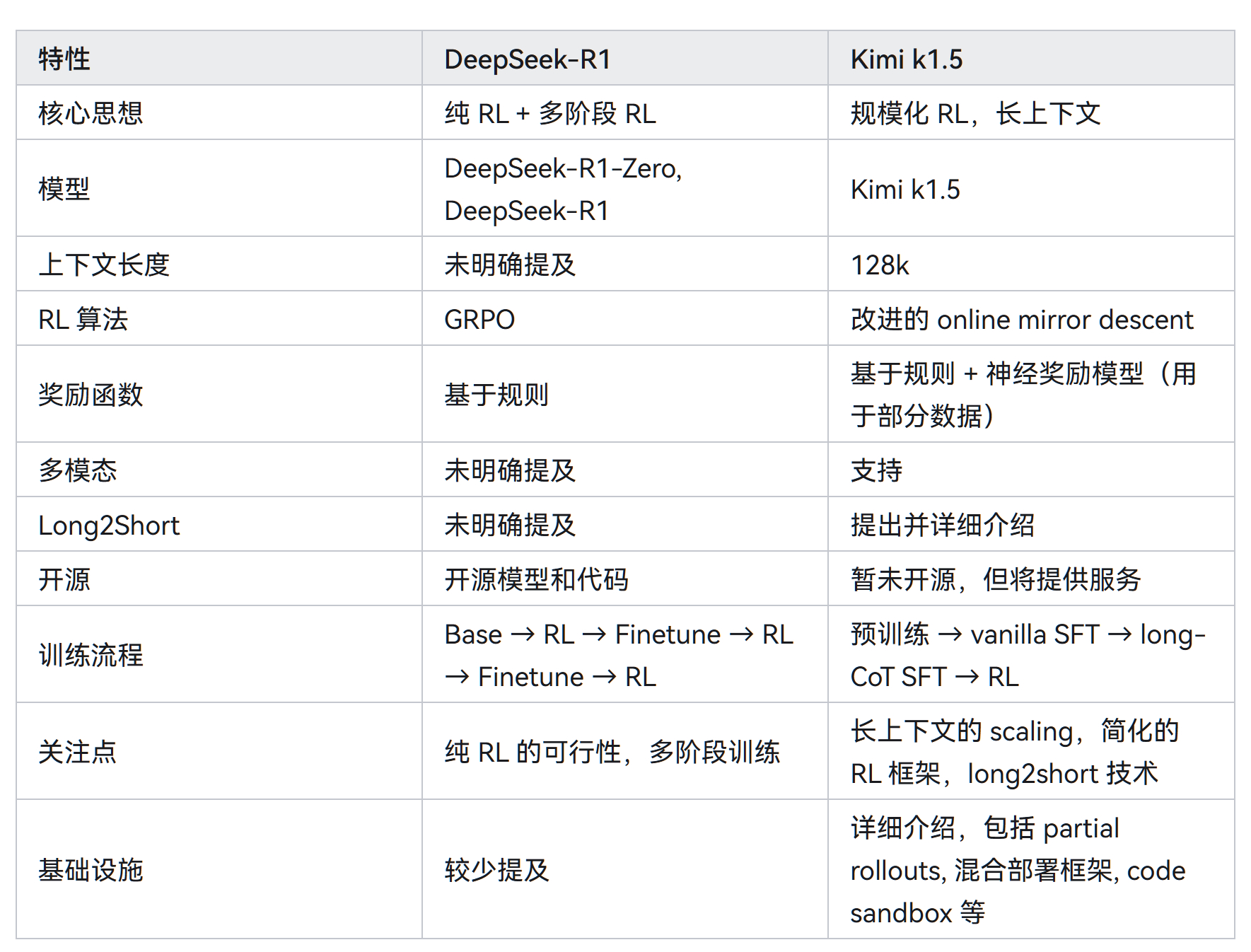
核心点似乎是通过规模化强化学习,特别是长上下文建模和改进的策略优化方法,构建了一个简化的、有效的 RL 框架,用于训练大型多模态语言模型 Kimi k1.5。可以对比下同样是刚刚发布的DeepSeek R1 (图2,AI总结的技术对比)
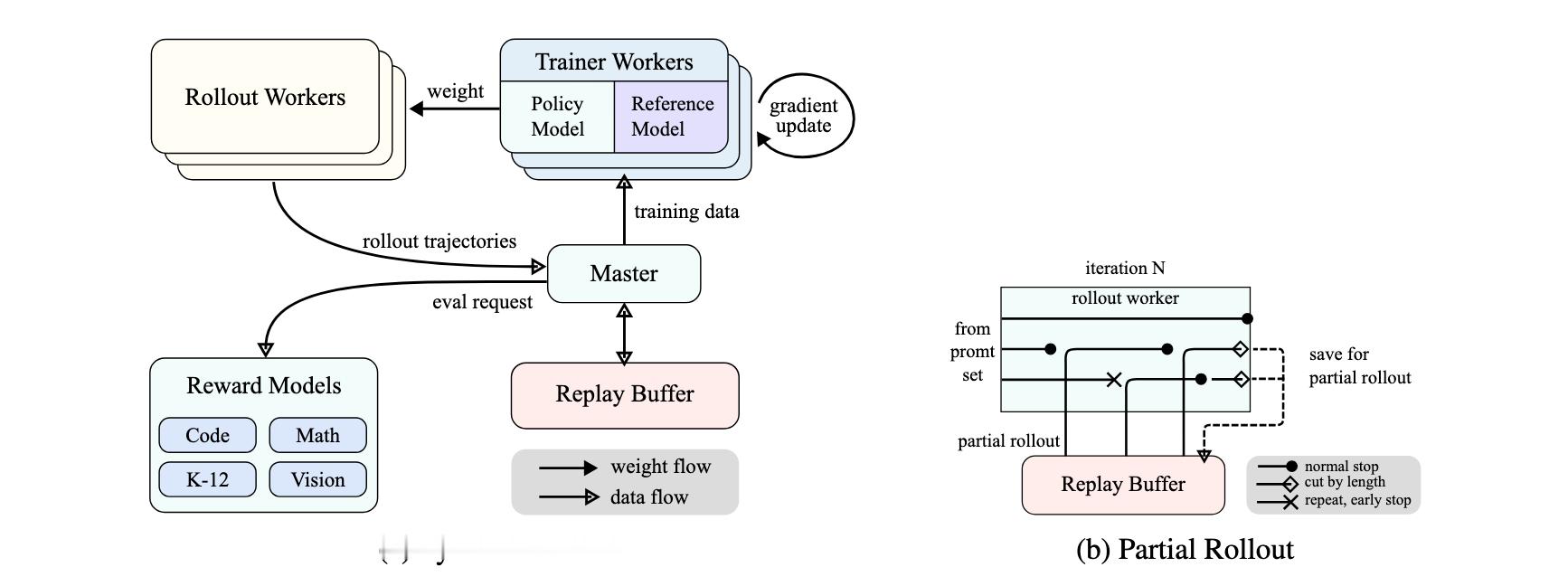
图3为 Kimi k1.5 模型在进行强化学习训练时的系统架构和工作流程。
从论文看,Kimi k1.5 是第一个公开证明长上下文与 RL 结合可以显著提升推理性能的模型。等正式发布后体验下。