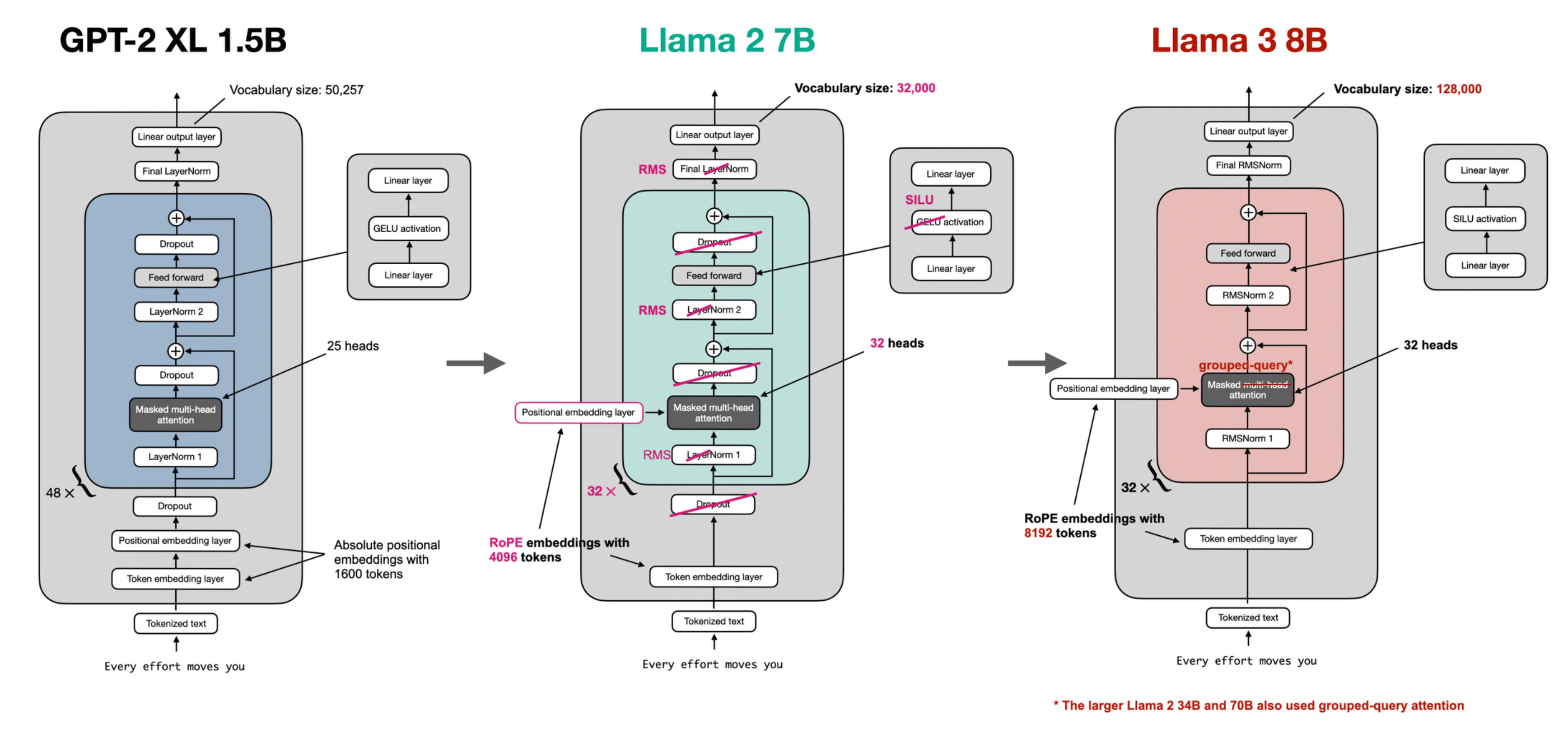
Sebastian Raschka(《从零开始构建大型语言模型》一书的作者) 绘制的GPT-2 XL 1.5B、Llama 2 7B以及Llama 3 8B的架构对比图
🌟GPT-2 XL 1.5B:
Vocabulary大小:50,257
使用了绝对位置嵌入(Absolute Positional Embeddings),最大输入长度为1600个token。
层数:48层,包含LayerNorm、Masked Multi-head Attention、Feed Forward等模块。
注意力头:25个多头注意力(heads)。
采用LayerNorm来正则化。
🌟Llama 2 7B:
Vocabulary大小:32,000
采用了RoPE位置嵌入(Rotary Positional Embeddings),支持最大4096个token的输入长度。
层数:32层,与GPT-2相比少了16层。
注意力头:32个,使用的是RMSNorm来代替LayerNorm,从而提升训练效率和收敛性。
激活函数:使用了SILU(Sigmoid-Weighted Linear Unit)代替GPT-2中的GELU。
🌟Llama 3 8B:
Vocabulary大小:128,000,显著增大。
继续使用了RoPE位置嵌入,但支持更长的输入长度:8192个token。
层数:32层,与Llama 2相同,但引入了Grouped-Query Attention,这是一种改进的注意力机制,优化了多头注意力的处理。
使用RMSNorm进行正则化。