一份关于机器学习中“解码器(Decoder)”基本原理的可视化说明。databites.tech绘制
关于编码器的之前发过可以看这里:
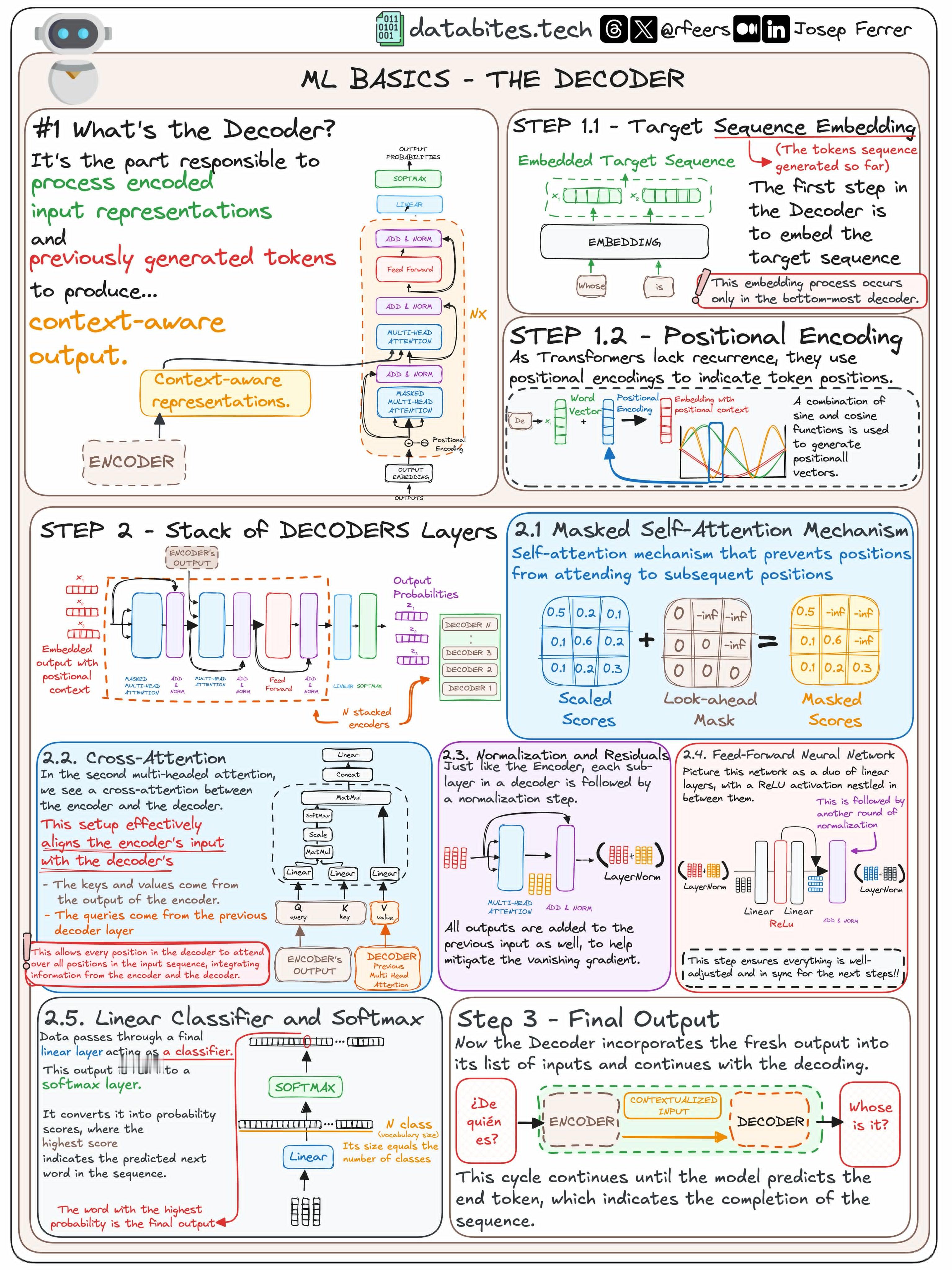
解码器是负责处理编码后的输入表示和之前生成的令牌,从而产生上下文感知的输出。其主要任务是根据编码器提供的输入和目标序列的上下文生成最终的输出。
⭐1:嵌入目标序列(Target Sequence Embedding):
1.1:目标序列嵌入(Target Sequence Embedding)
解码器的第一步是对目标序列(之前生成的令牌)进行嵌入(Embedding)操作。这一步只发生在解码器的最底层,目的是将离散的词(令牌)映射到一个高维连续空间中,使其便于模型处理。
1.2:位置编码(Positional Encoding)
因为Transformer模型没有顺序感,需要通过位置编码来为序列中的每个词添加位置信息。通过正弦和余弦函数为每个词生成一个独特的向量,以表示其在序列中的位置。
⭐2:解码器层堆叠(Stack of Decoders Layers):
解码器通常由多个解码器层堆叠而成,每一层都有其独立的处理单元。
2.1:遮罩自注意力机制(Masked Self-Attention Mechanism):
这个机制阻止模型关注未来的令牌,只关注当前及之前的令牌。这是通过“遮罩”来实现的,保证模型不会提前看到未来的序列信息。
2.2:交叉注意力(Cross-Attention):
在解码器的第二个多头注意力中,解码器将编码器的输出与解码器自身的输出对齐。这里的键和值来自编码器的输出,而查询来自解码器的前一层。这一步有效地将编码器输入的信息整合到解码器中。
2.3:规范化和残差(Normalization and Residuals):
解码器的每个子层后面都有一个规范化步骤,输出会被加回到前面的输入中,这样可以减轻梯度消失问题。
2.4:前馈神经网络(Feed-Forward Neural Network):
前馈神经网络是由两个线性层组成,中间夹着一个ReLU激活函数,随后进行归一化。这确保输出在下一步是调整好的。
2.5:线性分类器和Softmax:
解码器的最终输出会通过一个线性层作为分类器,之后进入Softmax层。Softmax层将输出转化为概率分布,其中概率最高的词就是预测出的下一个词。
⭐3:最终输出(Final Output):
解码器会把生成的输出循环再加入输入中,继续预测序列的下一个词,直到预测出终止令牌,表示序列完成。