全文约2200字;
阅读时间:约6分钟;
听完时间:约12分钟;

当某工厂的物料控制专员收到供应商提交的一份原材料采购报价明细表时,发现该报价单的表格格式存在问题,不利于快速进行匹配和索引计算。具体而言,问题在于同一材料的不同规格报价被合并于同一单元格中,比如:“前驱地脚支撑焊合”这一项下,包含了三种规格:“φ5*13抽芯铆钉”、“水槽固定板01”以及“水槽固定板02”,对应的报价分别是“0.05”、“0.04”、“0.03”。
当前面临的需求是,必须高效地将这些包含多重信息的单元格拆分为独立的单元格,形成规范的一维数据结构,确保每列数据对应单一属性(即“编码”、“名称”、“规格”、“数量”、“单价”)。鉴于报价单中涉及的材料种类繁多,手动进行拆分不仅耗时且易出错,因此迫切需要设计一个自动化公式来实现这一拆分过程,以提高工作效率。
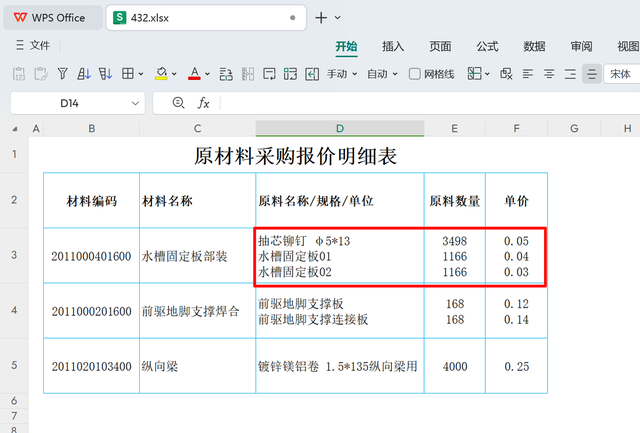 设计思路
设计思路观察数据表明,合并单元格中的内容(即规格、数量、单价)是利用换行符来区分同一材料下的不同规格信息的。据此特点,我们可以采用以下步骤实现列的分离:首先,利用TEXTJOIN函数,以特定的分隔符(例如“#”)将这三列数据合并到单个单元格中。随后,借助TEXTSPLIT功能,依据行间分隔符“#”及列内换行符(CHAR(10)),对合并后的内容进行细致拆分。
拆分完成后,使用HSTACK函数将编码和名称信息横向拼接,以此重构数组。在此过程中,若遇到数组维度不匹配导致的错误(表现为#/NA),可应用IFNA函数,将这类错误值替换回原始的编码和名称组合,确保信息的完整性。
最终,通过REDUCE函数将处理后的各部分数据逐行堆叠起来,即可顺利完成表格的结构调整,满足本次数据处理的需求。
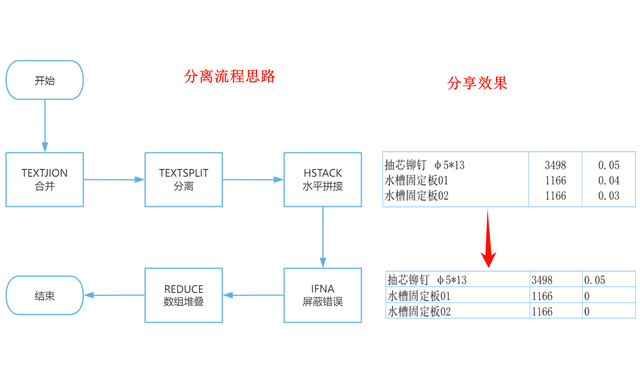 数据合并
数据合并首先,将含有合并单元格信息的多列数据(规格、数量、单价)整合到单一单元格中,以便后续处理。为了清晰展示公式应用方法,请在适当的位置输入以下公式作为示例:
=TEXTJOIN("#",,D3:F3)
此公式说明:
D3:F3 表示选取需要合并的单元格范围,即规格、数量、单价所在列的相应行。
TEXTJOIN 函数的作用是将这些单元格的内容用指定的分隔符(在这里是“#”)连接起来,生成一个连续的字符串。
执行此操作后,原本分散在多个单元格中的信息会被统一到一个单元格内,并以“#”作为不同项目之间的区分标志,其结果直观明了,如图所示。
 数据分离
数据分离然后,我们对已合并的数据进行拆分处理。此步骤旨在将先前结合的单元格内容重新分成独立的部分。请在适合的位置应用以下公式来实现这一操作:
=TRANSPOSE(TEXTSPLIT(TEXTJOIN("#",,D3:F3),CHAR(10),"#"))
该公式的工作原理如下:
首先,通过 TEXTJOIN("#",,D3:F3) 将之前合并的“规格”、“数量”、“单价”信息使用“#”符号连接起来。
接着,利用 TEXTSPLIT 函数依据列分隔符(在这里是“#”)和行分隔符(CHAR(10),代表换行符)将连接后的字符串切分成多个部分。这样就完成了按列和按行的分离。
最后,使用 TRANSPOSE 函数将分离出来的数据行列转置,确保数据的呈现格式与需求相符。
实施这一步骤后,数据会被整齐地重新排列到表格中,每个项目占据一列,如图所示。
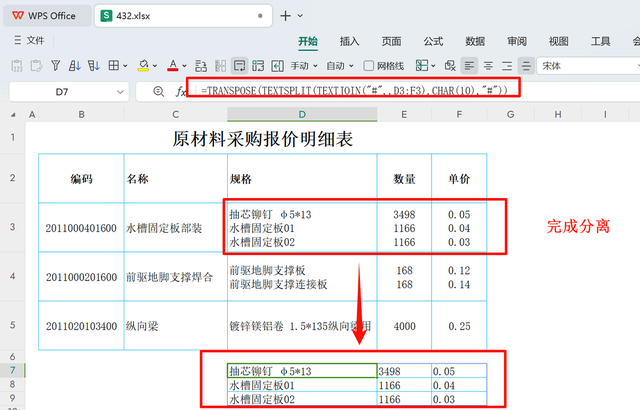 数据拼接
数据拼接在获取了上述处理过的数据之后,接下来需将“编码”和“名称”信息与之拼接。请在恰当的位置输入以下公式来完成这项任务:
=LET(A,B3:C3,IFNA(HSTACK(A,TRANSPOSE(TEXTSPLIT(TEXTJOIN("#",,D3:F3),CHAR(10),"#"))),A))
这一公式的逻辑解释如下:
首先,通过 LET 函数定义变量 A 为单元格 B3:C3 区域,即“编码”和“名称”所在的列。
接着尝试使用 HSTACK 函数水平拼接变量 A 与之前分离并转置的数据(由 TEXTSPLIT 处理过,基于换行符 CHAR(10) 和列分隔符 # 进行分割)。
由于数据结构可能引起的维度不匹配问题,HSTACK 操作可能会返回 #/NA 错误。这时,IFNA 函数会介入,将此类错误替换回原始的 A 值,确保数据连续性和准确性。
执行此公式后,最终结果将展示为每一行的“编码”和“名称”与对应分离出的规格、数量、单价数据完美拼接在一起,如示意图所示。
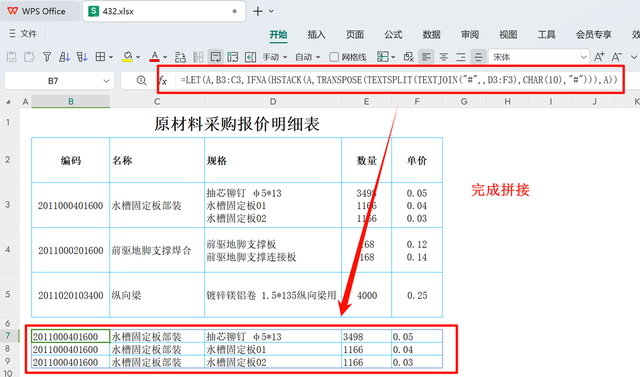 数据堆叠
数据堆叠最后阶段涉及数据的堆叠操作,根据 REDUCE 函数的需求,我们需要对引用的范围进行适当调整。首先对引用进行格式化处理:
将 B3:C3 调整为 OFFSET(B3,,,,2),以动态方式表示从 B3 开始向右的两列;
将 D3:F3 调整为 OFFSET(B3,,2,,3),意指从 B3 下方第二列开始的连续三列。
完成调整后,执行数据堆叠操作,使用以下公式:
=REDUCE(B2:F2,B3:B5,LAMBDA(X,Y,VSTACK(X,LET(A,OFFSET(Y,,,,2),B,OFFSET(Y,,2,,3),IFNA(HSTACK(A,TRANSPOSE(TEXTSPLIT(TEXTJOIN("#",,B),CHAR(10),"#"))),A)))))
该公式的详细解释如下:
初始值:B2:F2,这是表格的标题行。
数组:B3:B5,代表了需要进行堆叠处理的“编码”列数据。
函数:通过 LAMBDA 自定义了一个累积函数,其中 X 是累积结果的起始值,Y 是当前迭代的“编码”值。累积操作使用 VSTACK 将新计算的行数据垂直堆叠到累计结果 X 上。
在每次迭代中,LET 函数定义了两个局部变量 A 和 B,分别对应当前行的“编码”和“名称”以及接下来的规格、数量、单价信息。随后,应用之前类似的逻辑处理这些数据,最终通过 IFNA 确保错误安全地拼接,并使用 VSTACK 实现堆叠。
此公式运行完毕后,将产生一个从标题行开始,向下依次堆叠处理后的所有数据行的结果,正如图例所示。
 最后总结
最后总结总之,在面对复杂且易错的手动数据拆分任务时,我们通过一系列精心设计的公式成功实现了数据的自动整理与重构,极大地提升了处理此类问题的效率与精确度。本解决方案核心在于巧妙运用了WPS的高级函数,如TEXTJOIN、TEXTSPLIT、HSTACK以及REDUCE,不仅解决了原始报价单中的格式难题,还将多维度信息智能地重组为易于管理和分析的一维数据结构。
通过逐步的公式应用,我们首先合并了分散的信息,接着精准地将其拆分为独立单元,再通过智能化的条件拼接保证了数据的连贯性,最后利用REDUCE函数高效地完成了所有数据行的垂直堆叠。这一系列操作不仅克服了人工处理的局限,还充分展示了现代电子表格软件在数据处理上的强大能力。
结此过程,我们不仅获得了一个清晰、规范的表格,更重要的是构建了一套可复用的方法论,对于未来处理类似大规模数据整理任务具有极高的参考价值。此案例再次证明,合理利用技术工具,特别是高级公式与函数,能够显著提升工作效率,使数据分析工作更加流畅与准确。对于任何从事数据管理与分析的专业人士而言,掌握并灵活应用此类技巧,无疑是提升个人职业竞争力的关键所在。