
STAR (Spatial-Temporal Augmentation with Text-to-Video Models) 提出了一种创新的视频超分辨率解决方案,针对现有模型中存在的过度平滑和时间一致性不足等问题进行了系统性改进。该方法基于文本到视频(T2V)扩散模型架构,通过优化时序建模能力,有效处理复杂退化场景下的视觉伪影,同时解决了强生成模型导致的保真度损失问题。STAR的核心创新在于引入局部信息增强模块(LIEM)用于增强空间细节重建能力,并设计了动态频率(DF)损失函数,通过在扩散过程中对频率分量进行自适应调节来提升重建质量。实验表明,该方法在合成数据集和真实场景数据集上均优于现有最先进的方法。
技术方法
STAR框架由四个核心组件构成:变分自编码器(VAE)、文本编码器、ControlNet以及集成LIEM的T2V模型。其工作流程如下:
VAE负责将高分辨率和低分辨率视频映射至潜在空间
文本编码器生成高级语义信息的嵌入表示
ControlNet利用上述潜在表示和文本嵌入引导T2V模型的生成过程
T2V模型在扩散步骤中预测噪声速度以完成视频质量重建
在优化策略方面,STAR采用速度预测目标来最小化预测误差,并通过创新性的动态频率损失来提升重建保真度。该损失函数能够根据扩散过程动态调整高频和低频成分的约束强度。最终的损失函数将速度预测目标与DF损失进行时序加权组合。
局部信息增强模块设计
传统T2V模型主要依赖全局注意力机制,这种架构虽然在视频生成任务中表现出色,但在实际视频超分辨率应用中存在明显局限性。具体体现在处理复杂退化模式和捕获局部细节特征方面的能力不足,往往导致输出结果存在模糊和伪影问题。

LIEM模块的设计正是针对这些限制。该模块置于全局注意力层之前,通过结合平均池化和最大池化操作突出关键特征,随后由全局注意力机制进行处理,从而实现对局部细节信息的有效提取和增强。
动态频率损失机制
扩散模型强大的生成能力在视频重建任务中可能导致保真度降低。研究发现,扩散过程具有明显的阶段性特征:早期阶段主要重建低频结构信息,后期阶段则侧重于优化高频细节如边缘和纹理。基于这一观察,STAR提出了针对性的损失函数设计方案。
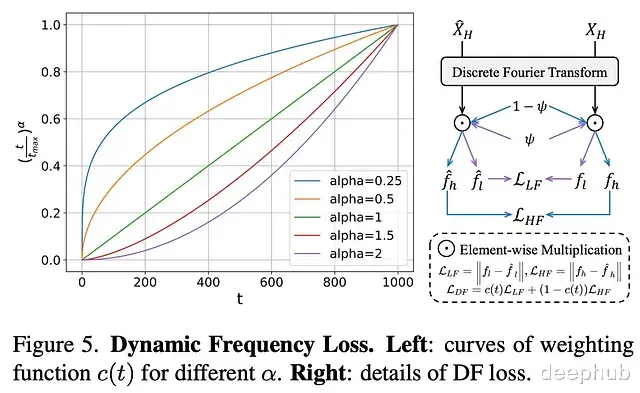
所提出的DF损失通过频率域解耦方式分别优化结构(低频)和细节(高频)重建质量。具体实现过程为:
在每个扩散步骤中重建潜在视频表示
应用离散傅里叶变换分离频率成分
分别计算低频和高频损失
通过动态权重函数调整优化重点,在早期步骤优先保证低频保真度,后期步骤则着重提升高频保真度
实验验证
STAR方法与多个先进基线方法(包括Real-ESRGAN、DBVSR、RealBasicVSR、RealViformer等)在合成和真实数据集上进行了系统性对比实验。实验结果表明:
定量评估:
在合成数据集上,STAR在80%的评估指标上达到最优性能,PSNR指标位居第二,充分验证了其在细节重建、保真度和时间一致性方面的优势
在真实场景数据集上,展现出优秀的空间和时间质量重建能力
定性分析:
STAR生成的空间细节最为逼真,同时有效抑制了退化伪影
在文本、人手、动物毛发等精细结构重建方面表现突出
这些优势得益于T2V模型的时空先验知识和DF损失的保真度增强机制
时间一致性:
相比依赖光流估计的传统方法(如StableSR和RealBasicVSR),STAR通过T2V模型的时间先验实现了更优的时间一致性
无需显式光流计算即可保持视频序列的连贯性
论文:
https://avoid.overfit.cn/post/3e63ac5ec2844de6bd4d0675d13f7752
作者:Andrew Lukyanenko