Hey, 小伙伴们!今天小米给大家带来一篇关于Kafka生产消费基本流程的揭秘,内容超干货!让我们一起揭开Kafka神秘的面纱,探索它的工作原理吧!
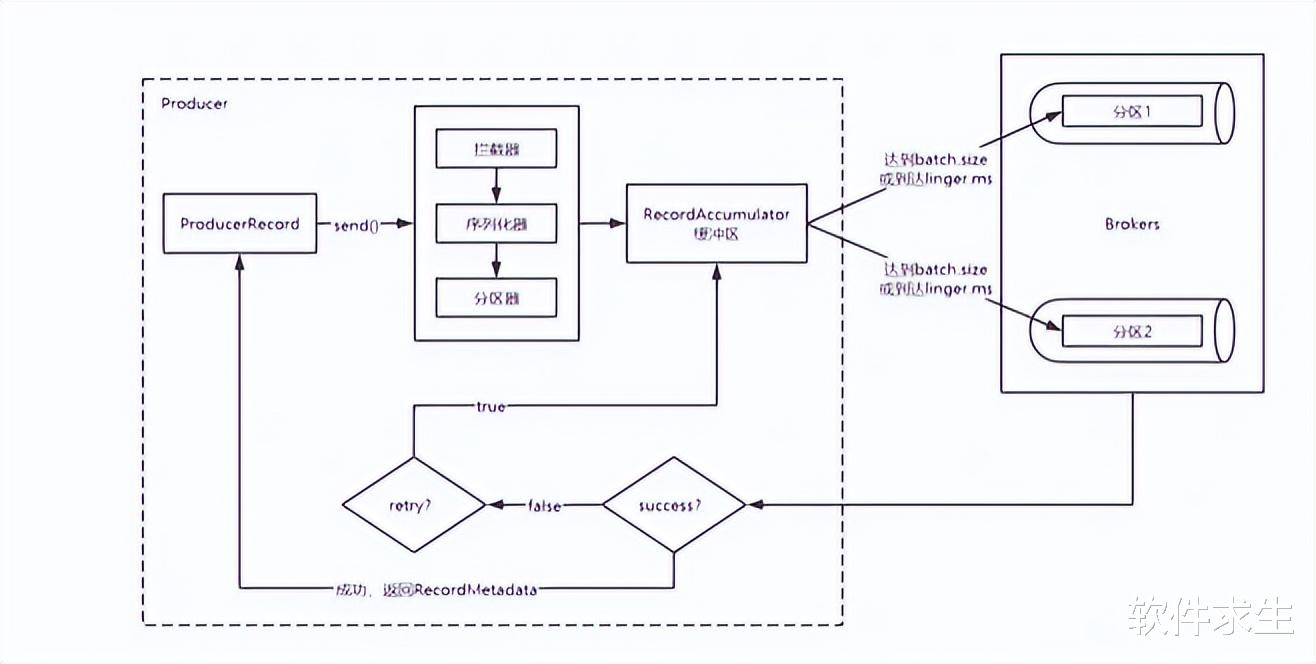
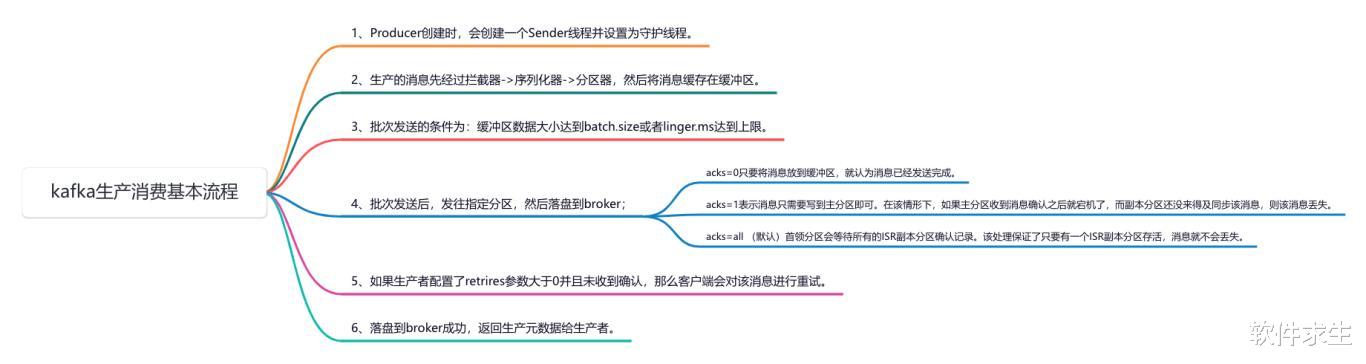
Producer创建及其内部结构当我们创建一个Kafka Producer时,Kafka会为我们创建一个叫做Sender的线程,并将其设置为守护线程(Daemon Thread)。这个线程的主要工作就是不断地从缓冲区中取出消息并发送给Kafka Broker。守护线程的好处在于,它会随着主线程的结束而自动结束,不需要我们手动去管理它的生命周期。
消息的处理流程在Producer发送消息的过程中,消息会依次经过以下几个步骤:
拦截器(Interceptor):首先,消息会通过一系列的拦截器进行处理。拦截器可以用来在消息发送之前或之后做一些额外的操作,比如修改消息内容、统计日志等。
序列化器(Serializer):然后,消息会经过序列化器,将消息对象转换为字节数组,以便于网络传输。
分区器(Partitioner):接下来,分区器会根据消息的Key或者其他策略将消息分配到指定的分区上。
缓冲区(Buffer Pool):最后,消息会被放入到Producer的缓冲区中等待发送。
批次发送的条件Kafka的Producer会将消息进行批量发送,以提高传输效率和吞吐量。具体的批次发送条件如下:
当缓冲区中的数据大小达到batch.size时,Producer会将这些消息组成一个批次进行发送。
当消息在缓冲区中的等待时间超过linger.ms时,即使缓冲区中的数据大小没有达到batch.size,Producer也会将这些消息组成一个批次进行发送。
消息发送及落盘当批次发送的条件满足时,Producer会将消息发往指定的分区,然后落盘到Kafka Broker中。消息发送的可靠性可以通过acks参数进行控制:
acks=0:当acks设置为0时,Producer只要将消息放到缓冲区,就认为消息已经发送完成。这个模式下的消息发送速度最快,但可靠性最低,因为Producer不会等待任何确认,消息有可能会丢失。
acks=1:当acks设置为1时,消息只需要写到主分区(Leader Partition)即可。在这种情况下,如果主分区收到消息确认之后就宕机了,而副本分区(Follower Partition)还没来得及同步该消息,则该消息会丢失。
acks=all(默认):当acks设置为all(默认值)时,Leader分区会等待所有的ISR副本分区(In-Sync Replica)确认记录。这种模式下,只要有一个ISR副本分区存活,消息就不会丢失,是可靠性最高的一种设置。
消息重试机制如果生产者配置了retries参数大于0,并且未收到消息的确认,那么Producer客户端会对该消息进行重试。重试机制能够有效提高消息发送的可靠性,避免由于网络波动或临时故障导致的消息丢失。
消息落盘及元数据返回当消息成功落盘到Kafka Broker后,Broker会返回生产元数据给Producer。这个元数据包含了消息的主题、分区、偏移量等信息。Producer可以通过这些信息进行消息的追踪和管理。
END好了,以上就是Kafka生产消费基本流程的详细揭秘啦!希望小伙伴们通过这篇文章对Kafka的工作原理有更深入的了解。如果你对Kafka还有其他疑问或者想要了解更多技术干货,欢迎在评论区留言,小米会及时回复大家哦!
别忘了关注我的公众号,获取更多有趣又实用的技术分享!我们下次见啦!