
阿里妹导读
本文作者分享了一些对数据建模的理解,并以社区业务为例展开讨论。
作为一名练习时间1年的数据研发练习生,这一年里我在业务需求中摸爬滚打,系统地学习了数据建模。在这里我想分享一些我对数据建模的理解,并以我支持的社区业务为例展开讨论,如果有任何不足之处,欢迎大家交流指正。
什么是数据
数据是什么:让我们来看一下官方定义,数据是对客观事物的数量、属性、位置及其相互关系的抽象表示,是对信息的记录。这个解释比较抽象,其实我理解,凡是可以被记录的,都是数据。
数据从哪里来,到哪里去:数据不是天然存在的,而是被生产出来的,从原始数据生产-> 数据采集-> 数据加工-> 数据分析挖掘,进而形成知识,再循环到指导原始数据生产,这里有两个关键要素:
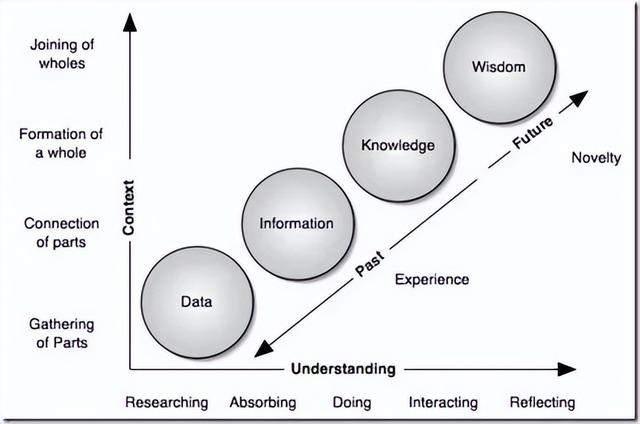
数据源:数据描述的对象;数据生产:对该对象的数字化记录、描述和呈现,即数据化的过程;DIKW框架:数据(data) -> 信息(information) -> 知识(knowledge) -> 智慧(wisdom)
数据是未加工的原材料,简单的事实记录。经过加工处理后,就形成了信息,能够回答一些简单问题。对信息再进行总结归纳,将其体系化,信息之间产生了联系,就形成了知识。而智慧则是在理论知识的基础上,加上自身实践,得出的人生经验或对世界的看法,具有较强的主观色彩。
什么是数据建模
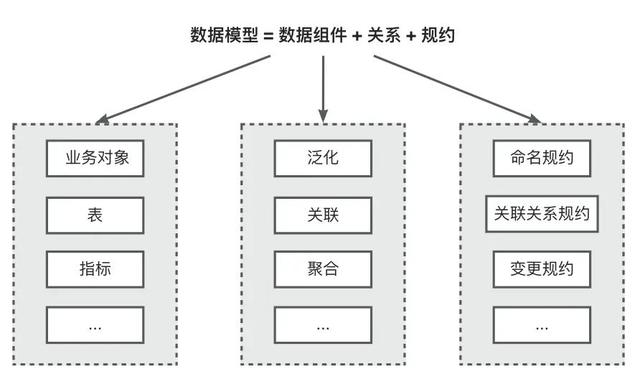
数据建模即构建数据模型,数据模型=数据组件+关系+规约。
为什么要数据建模呢?本质是为了有序有结构地分类存储和组织数据,我们可以从规范,效率,成本三个角度考虑:
规范:指导生产用户进行规范化研发,保障数据的规范化和一致性;效率:消费用户易查找、易理解、易使用、产出稳定、使用性能优;成本:存储成本/计算成本消耗合理,计算性能优;数据建模总体流程
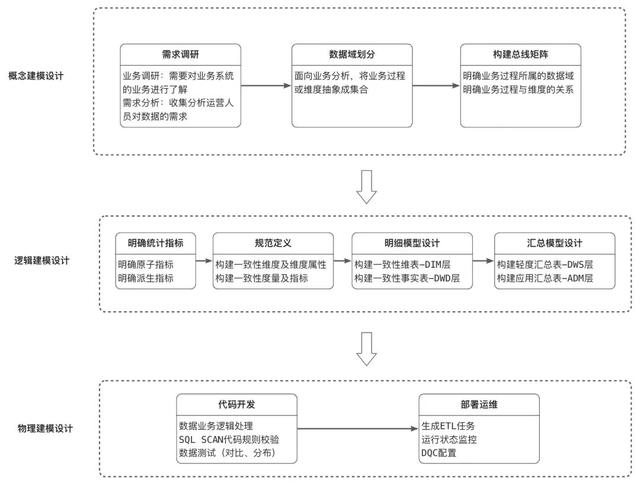
概念建模设计
数据建模的第一阶段是概念建模设计,将业务领域知识转化为图形化表达。这样可以指导后续的逻辑建模,并方便数据消费者查找和使用数据。概念建模的第一步是需求调研,包括业务调研和需求分析两方面:
业务调研:自底向上,了解业务源系统;需求分析:自顶向下,收集分析师和运营人员对数据或报表的需求;下一步是进行数据域划分,这意味着要根据面向业务的分析,将业务过程或维度进行抽象,然后划分出单独的模块。最后构建总线矩阵,明确业务过程所属的数据模块,并确定业务过程与维度之间的关系。
逻辑建模设计

接下来我们进入到逻辑建模设计,第一步要做的是明确并规范定义指标与维度。首先,我们需要明确各个维度及其对应的属性,然后需要明确原子指标和派生指标。原子指标是针对特定业务过程的度量,不可再细分,具有明确的业务含义;派生指标是对原子指标在特定业务统计范围下的限定,下面我们将正式进入明细层模型设计。
构建一致性维表-DIM层维度是维度建模的基础和灵魂,如何构建一致性维表,维度表设计过程如下:
第一步:选择业务对象;第二步:定义维度属性;第三步:定义关联维度;第四步:冗余维度;设计TIPS
主键标识:维度表必须要有唯一主键标识,可通过配置DQC强规则保证主键唯一性;(ps:记得很久以前弱弱问了老板一句,维表一定要有主键么?被老板白了一眼,从此铭记于心!)水平拆分/垂直拆分:当出现以下情况时,可以将维度的不同分类实例化为不同维度:不同业务属性差异比较大或者数据量差异大,例如淘宝商品、天猫商品、1688商品,有公共属性,也有各自独特的属性,这时候将所有可能的属性建立在一个表里不切实际;业务的关联程度较低,对于两个相关性较低的业务,耦合在一起弊大于利,影响模型稳定性和易用性;维度属性相同的数据,可以将产出时间晚/运行不稳定/口径变化频繁/热度低较少使用的属性拆分至单独表:主维表存放稳定、产出时间早、热度高的属性;从维表存放变化较快、产出时间晚、热度低的属性;dt每日全量记历史/拉链记历史:拉链记历史:存储计算成本低、运维成本高、使用成本稍高;dt记历史:存储计算成本高、运维成本低、使用成本低;维表命名规范:{project_name}.dim_{业务关键字}[_{数据单元}]_{维度缩写}[_{自定义标签缩写}];按天调度,省略后缀dd;按小时调度,添加后缀hd;构建明细事实表-DWD层明细事实表分为事务事实表、周期快照事实表和累计快照事实表,具体分类如下:
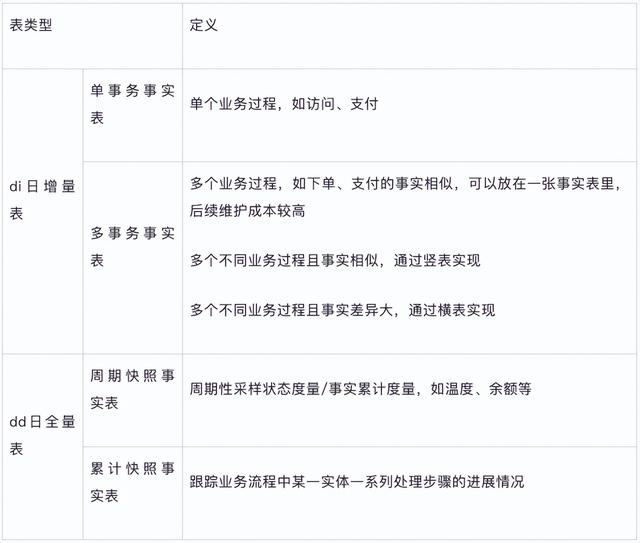
明细事实表设计过程如下:
第一步:选择业务过程,事务事实表的典型特征是限定发生时间等于当天,以解决数据漂移;第二步:声明粒度,事务事实表的粒度表达有多种方式,快照事实表的粒度通常以维度或维度组合形式声明;第三步:确定维度;第四步:确定事实 仅包含与业务过程相关的事实;第五步:冗余维度;设计TIPS
DWD设计的首要原则是稳定,提供最明细的数据,尽量与原系统保持一致,保持足够多信息;从ODS表中提取数据时,需要考虑脏数据的过滤,以及将数据解析成下游可以直接消费的数据,比如枚举值的加工和日志扩展字段的解析;冗余维度属性时,对于经常变化的属性,可以封装视图来避免数据回刷;明细表命名规范:{project_name}.dwd_{业务关键字}_[_{数据单元}]_{单或多业务过程缩写}[_{自定义标签缩写}]_{刷新周期标识}{单分区增量全量标识}构建汇总事实表-DWS&ADM层汇总事实表的设计过程如下:
第一步:确定统计粒度第二步:定义统计指标第三步:划分物理表第四步:冗余维度属性DWS轻度汇总层面向业务需求设计,首先考虑的是复用性。需要特别关注某些维度的聚集是否经常用于数据分析,并在设计时尽量覆盖常用的分析场景。这样做的好处是,一方面可以为上游提供统一、准确、一致的数据,另一方面,上层指标加工时无需多次计算,可以节省资源。
设计TIPS
避免维度属性一起聚合,数据汇总完成后关联维度获取最新维度属性;避免所有统计周期/CUBE一起计算,考虑计算复用,如nd依赖1d、粗粒度依赖细粒度;注意维度用于业务限定或统计粒度的使用方式,使用当天的 vs 最新的:使用当天的快照数据,则在回刷数据时,数据始终一致;使用最新的快照数据,则在回刷数据时,数据无法和最初保持一致;汇总表命名规范:DWS轻度汇总表:{project_name}.dws_{业务关键字}[_{数据单元}][_{数据粒度缩写}][_{单或多业务过程缩写}][_{自定义标签缩写}]_{后缀};日汇总通过1d/nd/td等进行区分,其中[1d是1天数据汇总]、[nd是多天数据汇总],[td是历史累计汇总],其他周期用[hs小时汇总]、[ws周汇总]、[ms月汇总]、[rs实时汇总]表示;ADM应用汇总表:{project_name}.adm_{业务关键字}[_{单元}][_{自定义标签缩写}]_{后缀};统计时间周期:统一用[ds日统计]、[ws周统计]、[ms月统计]表示,如果能明确界定1d/nd/td,后缀也可写成1d/nd/td;物理建模设计
逻辑模型设计好后,我们可以开始正式进入代码开发和运维阶段(即正式开始干活):
代码开发:数据业务逻辑处理+SQL SCAN代码规则校验+数据测试(对比、分布)
部署运维:生成ETL任务+运行状态监控+DQC配置
数据模型验证与保障
社区数据服务
写在前面
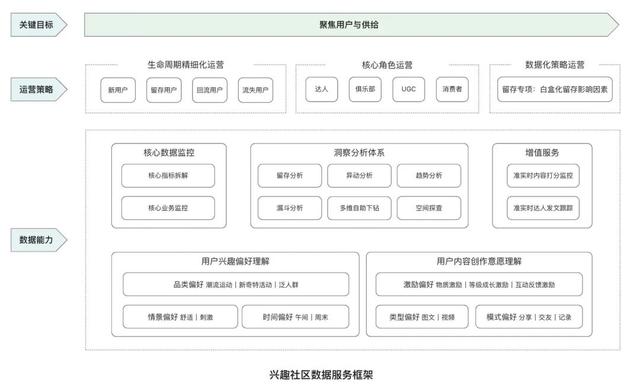
我7月初接手了社区业务,这里从我的视角讲述如何针对一块业务进行数据建模以及提供对应的数据服务。对于数据同学来说,我们能做的包括帮助业务看清现状,定位业务问题,以及数据驱动发现产品优化方向与运营策略并定量效果。首先第一步,我们要充分了解业务背景,即市场机会如何,市场现状如何,在我司的定位是什么?以兴趣社区为例,相较于传统的社交方式,目前市场上的趋势是人们更倾向于寻找共同兴趣爱好和认知的伙伴,而针对小众兴趣领域,用户对非标准化商品的交易需求也在增加,比如户外活动和livehouse门票。目前主流的平台只有粗门和闪动,剩下大部分是微信私域在承接(私聊、朋友圈、微信群、小程序等),抖音和小红书等也还在起步阶段。我们的兴趣社区产品是以兴趣为基础,社区为形态,具有分发长尾内容和非标准化商品能力的本地化社区产品。行业内社区的商业模式如下图所示:

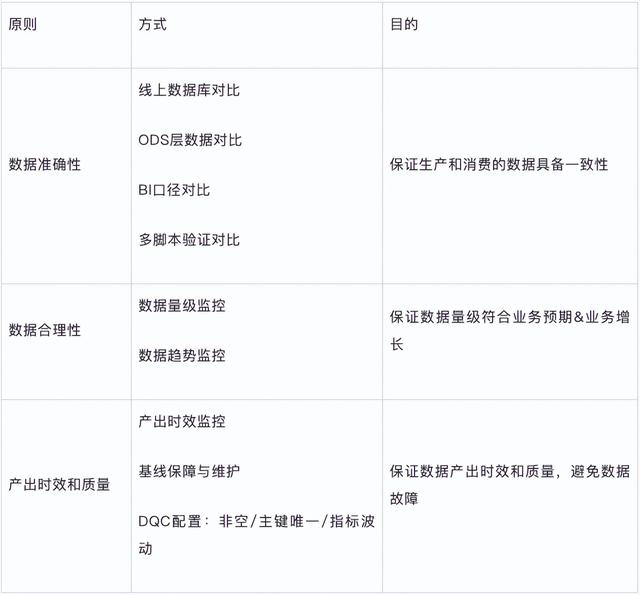
兴趣社区整体的数据服务框架如下图所示:
数据建模过程
接下来讲述社区数据建设流程,这里只列出了一些关键流程,具体细节在此不展开叙述。
ER关系图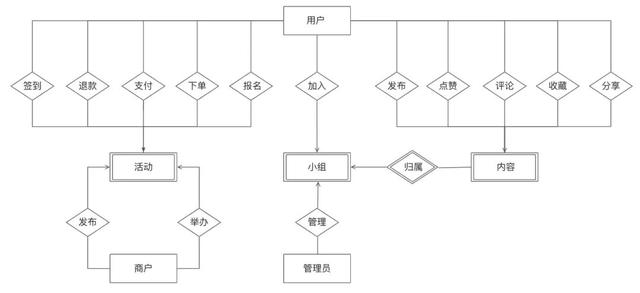 业务架构图
业务架构图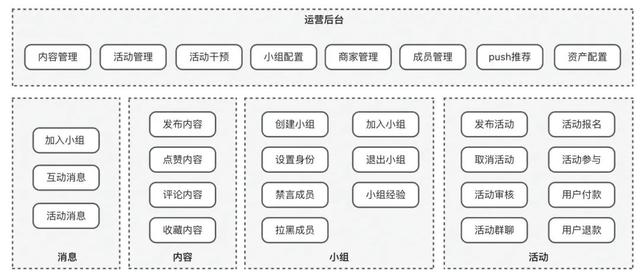 构建总线矩阵
构建总线矩阵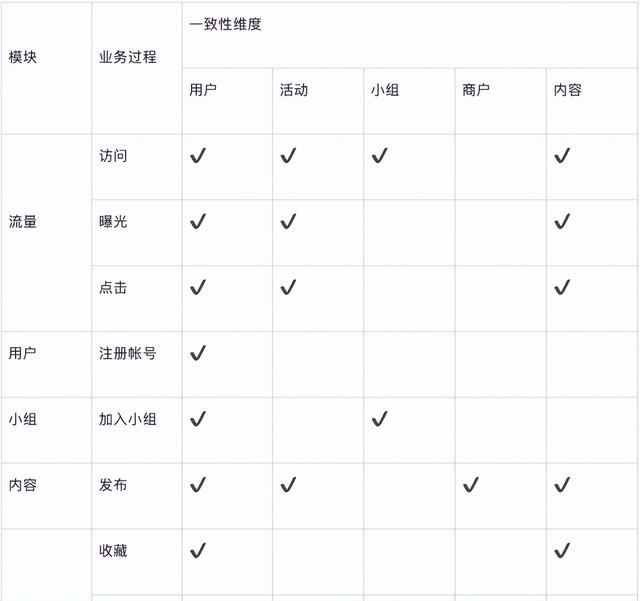
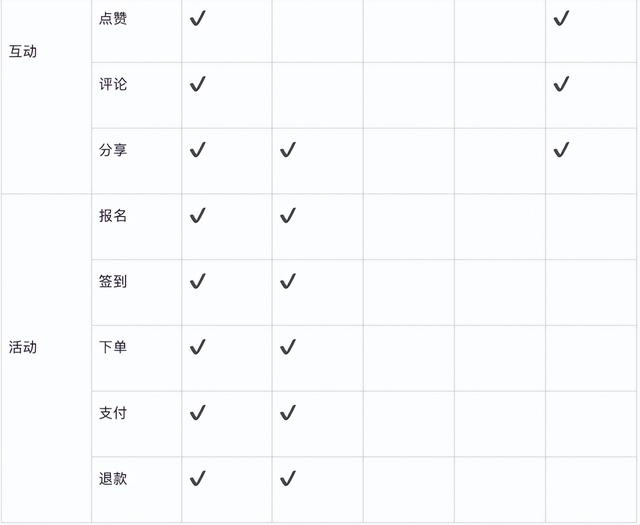
数据分析思路
指标体系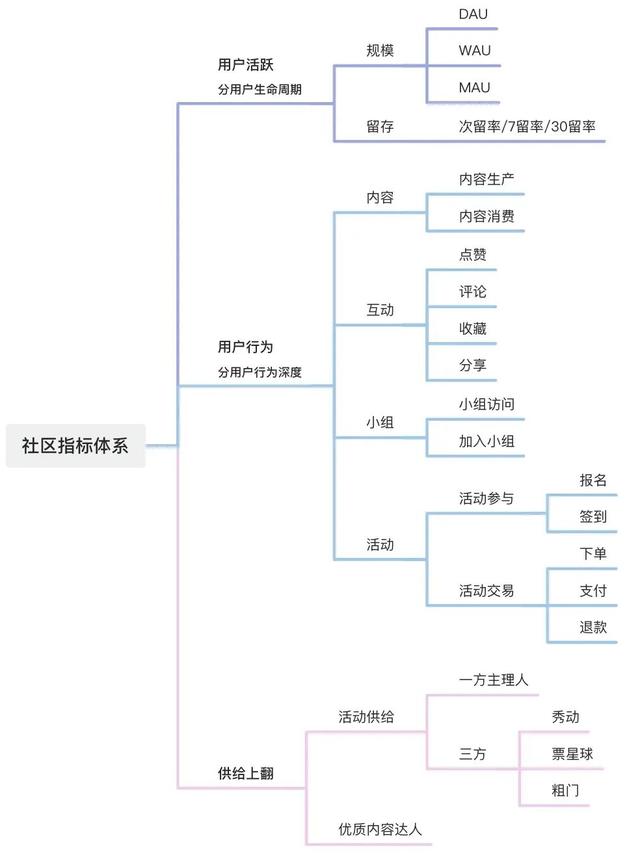 OSM拆解
OSM拆解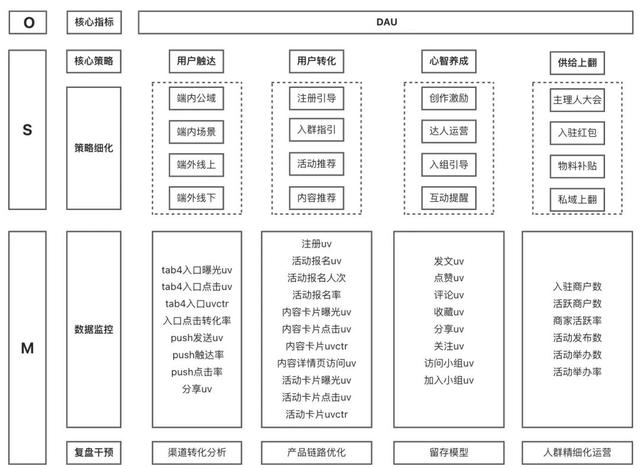 明确和规范定义指标与维度原子指标
明确和规范定义指标与维度原子指标
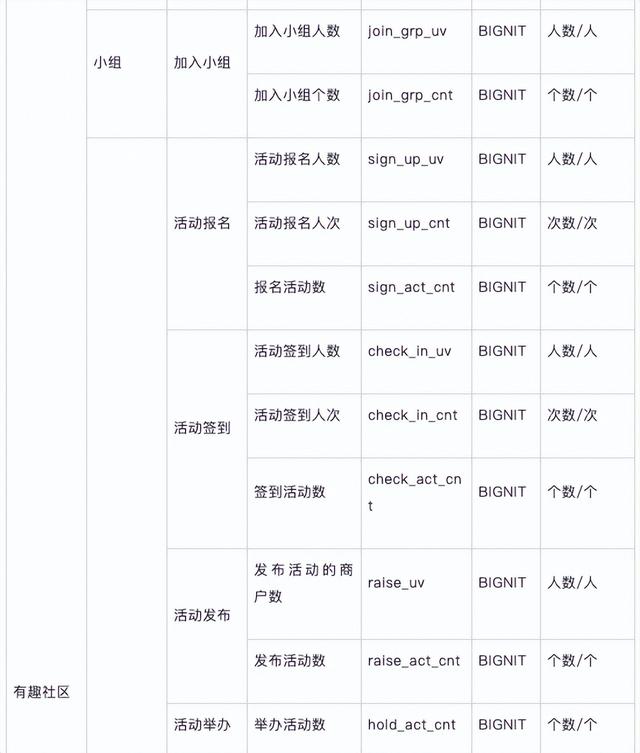

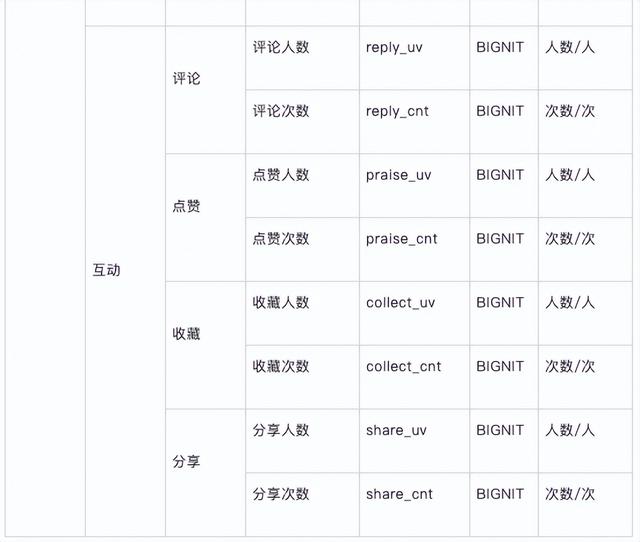
派生指标

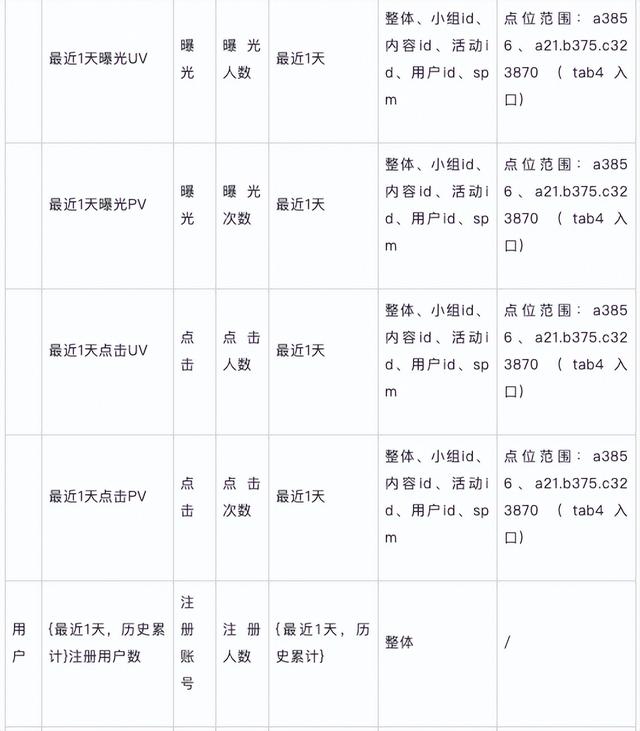


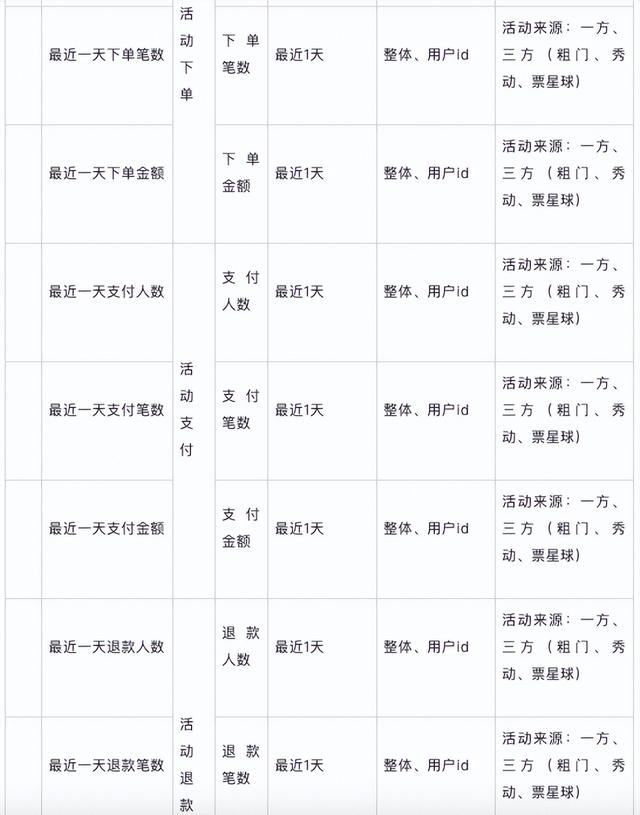
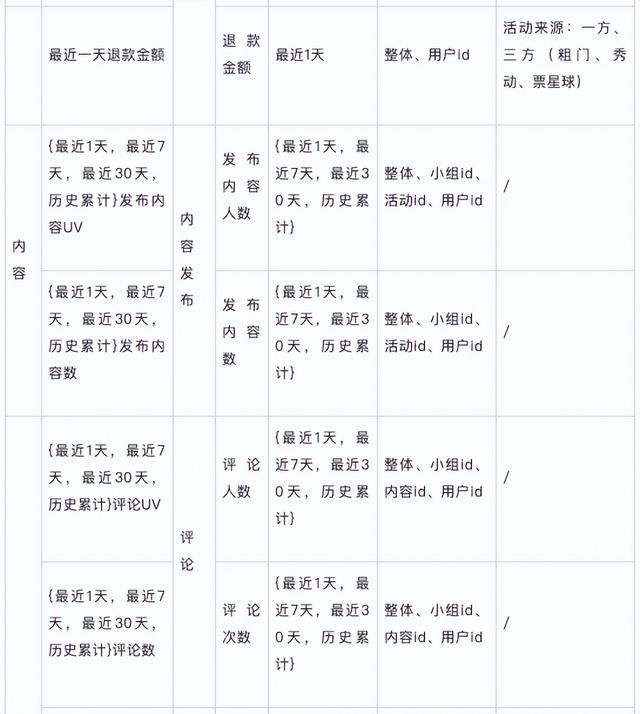
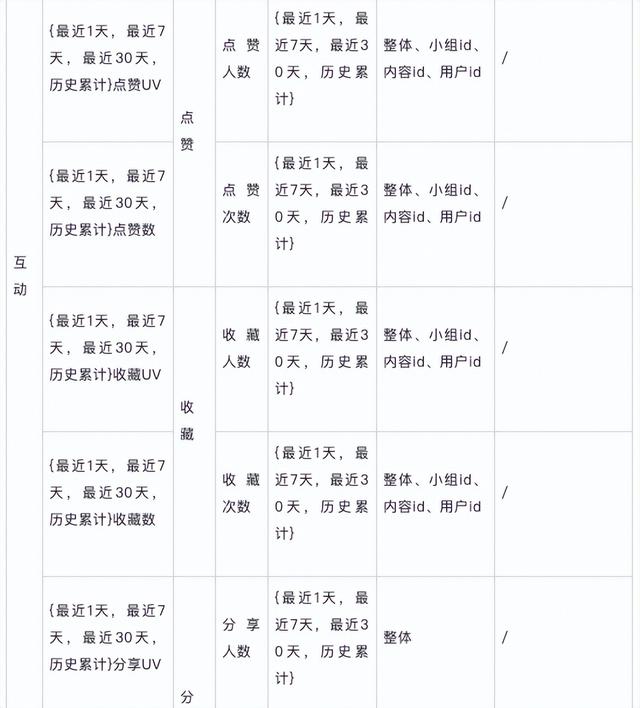

维表设计
