原文链接:
Hello,大家好啊!今天给大家带来一篇关于在统信UOS上通过Ollama本地化部署 DeepSeek-R1模型的文章!DeepSeek-R1作为一款高性能的开源AI语言模型,能够本地推理,适用于离线环境。而Ollama是一款轻量级的本地AI模型管理和运行工具,它可以让我们更方便地下载和部署大语言模型。今天就来详细讲解如何在统信 UOS上使用Ollama轻松运行 DeepSeek-R1!欢迎大家分享点赞,点个在看和关注吧!
DeepSeek-R1 模型简介
DeepSeek-R1 是 DeepSeek AI 推出的高性能开源大语言模型,具有以下特点:
支持本地推理,适用于私有环境,数据隐私可控;
性能强劲,可高效处理NLP任务,如问答、摘要、代码生成等;
支持GPU/CPU推理,可在不同硬件环境下运行;
兼容Transformers框架,易于集成到Python应用中。
Ollama简介
Ollama是一个轻量级的AI模型管理工具,特点如下:
直接下载、管理、运行AI语言模型
一键推理,无需复杂配置
兼容多种LLM(如Llama2、Mistral、DeepSeek-R1)
支持GPU加速(可选)
Ollama让本地化部署AI变得更简单,无需繁琐的Python环境搭建。
1.查看系统信息
pdsyw@pdsyw-PC:~/Desktop$ cat /etc/os-version [Version] SystemName=UOS DesktopSystemName[zh_CN]=统信桌面操作系统ProductType=DesktopProductType[zh_CN]=桌面EditionName=ProfessionalEditionName[zh_CN]=专业版MajorVersion=20MinorVersion=1070OsBuild=11018.102.100pdsyw@pdsyw-PC:~/Desktop$ uname -aLinux pdsyw-PC 4.19.0-amd64-desktop #7206 SMP Thu Nov 28 13:45:35 CST 2024 x86_64 GNU/Linux
2.配置临时代理
pdsyw@pdsyw-PC:~/Desktop$ export http_proxy="http://192.168.80.1:7890"pdsyw@pdsyw-PC:~/Desktop$ export https_proxy="http://192.168.80.1:7890"
3.安装 Ollama
pdsyw@pdsyw-PC:~/Desktop$ curl -fsSL https://ollama.com/install.sh | sh
4.验证安装
pdsyw@pdsyw-PC:~/Desktop$ ollama --versionollama version is 0.5.11
5.下载 DeepSeek 模型
pdsyw@pdsyw-PC:~/Desktop$ ollama pull deepseek-R1
6.查看ollama列表
pdsyw@pdsyw-PC:~/Desktop$ ollama listNAME ID SIZE MODIFIED deepseek-R1:latest 0a8c26691023 4.7 GB 3 minutes ago
7.获取更详细的模型信息
pdsyw@pdsyw-PC:~/Desktop$ ollama show deepseek-R1 Model architecture qwen2 parameters 7.6B context length 131072 embedding length 3584 quantization Q4_K_M Parameters stop "<|begin▁of▁sentence|>" stop "<|end▁of▁sentence|>" stop "<|User|>" stop "<|Assistant|>" License MIT License Copyright (c) 2023 DeepSeek
以下是 详细解释每一行的参数含义:
1. Model(模型信息)字段
含义
architecture
qwen2:说明 deepseek-R1 采用 Qwen2 架构(阿里巴巴 Qwen-2 变体)。
parameters
7.6B:模型总参数量 7.6 Billion(76亿参数)。
context length
131072:最大上下文窗口 131072 tokens(13.1万 tokens),表示一次推理时能处理的最大 token 数。
embedding length
3584:隐藏层表示的维度大小(模型内部 token 变换的维度)。
quantization
Q4_K_M:采用 Q4_K_M 量化格式(4-bit 量化,高效推理,减少存储占用)。
解释 quantization
Q4_K_M 表示 4-bit 量化(GPTQ 方法),相比 FP16 版本,显存和存储需求大幅减少。可能带来 轻微的精度损失,但推理速度更快,适合本地推理。2. Parameters(额外参数)这部分 stop 词用于 控制输出终止,即模型在生成文本时遇到这些 stop 词会 自动停止生成。
字段
含义
stop "<|begin▁of▁sentence|>"
停止生成时遇到 `<
stop "<|end▁of▁sentence|>"
遇到 `<
stop "<|User|>"
当输出中包含 `<
stop "<|Assistant|>"
当输出中包含 `<
用途:
避免无限生成:模型会在输出中特定标记出现时终止,防止生成超长无意义的回答。适用于聊天模式:通常在 Chat LLM 中用于分隔 用户输入 和 AI 输出。3. License(许可证)字段
含义
MIT License
deepseek-R1 采用 MIT 开源许可证,允许自由使用、修改和分发。
Copyright
(c) 2023 DeepSeek:版权归 DeepSeek AI 团队所有。
MIT 许可证的特点:
允许 商用、修改、自由分发。仅要求 保留版权声明,适合个人开发和企业使用。8.下载指定参数的模型
pdsyw@pdsyw-PC:~/Desktop$ ollama pull deepseek-R1:1.5b
9.查看下载的模型信息
pdsyw@pdsyw-PC:~/Desktop$ ollama listNAME ID SIZE MODIFIED deepseek-R1:1.5b a42b25d8c10a 1.1 GB 15 seconds ago deepseek-R1:latest 0a8c26691023 4.7 GB 10 minutes ago
10.运行模型
pdsyw@pdsyw-PC:~/Desktop$ ollama run deepseek-R1:latest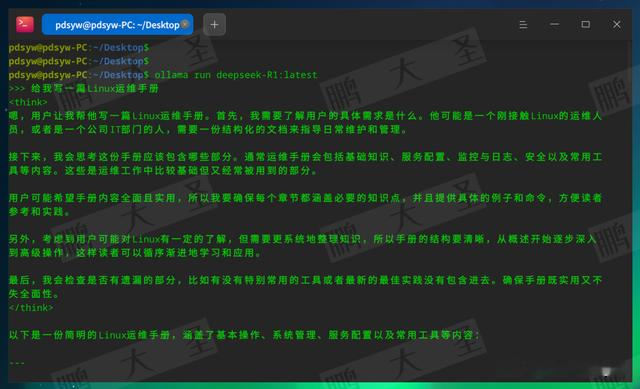








通过Ollama,我们可以轻松在统信UOS上部署DeepSeek-R1,并进行本地推理。相比传统的 Python环境配置方式,Ollama让模型管理和调用更加简单、高效,特别适用于本地化AI应用开发。如果你正在寻找一款易用、快速、本地化的AI部署方案,Ollama + DeepSeek-R1绝对是值得尝试的组合!如果您觉得这篇文章对您有帮助,欢迎分享点赞,记得点个在看和关注哦!我们下次再见!