
导语:作为2024年服贸会重要组成部分之一,国家卫生健康委员会百姓健康频道(CHTV))定于9月13日在京举办“2024首都国际医学大会的平行论坛——数智医疗与医学人工智能创新论坛”,CHTV&医学论坛网将为您带来AI赋能医疗的系列报道,今天,我们特别聚焦腾讯优图最新发表的一项突破性研究成果,探讨大语言模型如何打破语言的桎梏 ,以实现其在中文医疗场景下的应用拓展。

吴贤博士
腾讯优图天衍研究中心主任,专家研究员。主要研究方向为自然语言理解、深度机器学习、医学大模型等。在Nature子刊,T-PAMI, NeurIPS, ACL, CVPR等国际顶级杂志会议上发表文章一百余篇,被引用超过4700次,有近50项美国和中国专利。
作为腾讯优图实验室天衍研究中心负责人,吴贤博士是医疗自然语言处理和医学影像领域的领军人物,专注于自然语言理解、深度机器学习和辅助诊疗系统等领域的研究。他带领的团队医疗大模型领域已取得了突破性进展,如医学影像的精准解读、疾病早筛及智能辅助诊疗系统等。
01
语言障碍下的大型语言模型困境:开拓医疗AI新视野
近年来,随着自然语言处理(NLP)技术的飞速发展,大型语言模型(LLM)在医疗健康领域的应用前景日益广阔。它们通过大规模文本数据的预训练,不仅掌握了强大的语言理解和生成能力,还编码了广泛的知识,以支持合理的医学分析。然而,这些模型的开发和验证主要依赖于以英语为中心的数据集,面对非英语的医疗环境,它们的表现大打折扣。全球有超过7 000种语言,但用于训练LLM的数据大约90%是英文的,非英语医学语料库更是稀缺,这种语言不平衡对LLM在非英语临床场景中的应用构成了挑战。
此外,现有的研究尝试在训练阶段将临床知识整合到LLM中,但这些尝试往往局限于英语中心的LLM,缺乏跨语言环境的通用性,限制了它们在全球医疗保健领域的应用。同时,这些研究需要大量的高质量数据集和巨大的计算资源,对于资源有限的群体或国家来说并不实际。因此,如何在不同语言边界内有效地整合各种类型的医疗知识到LLM中,仍然是一个未充分研究的问题。

2024年9月,腾讯优图实验室吴贤博士团队联合浙江大学医学院袁长征教授团队,共同在美国医学信息学协会(AMIA)官方期刊J Am Med Inform Assoc发表了一篇题为“大型语言模型利用外部知识,将临床洞察力扩展到语言界限之外”的文章,提出了一种新颖的解决方案——开发一个能够结合外部临床知识源的上下文学习框架,以增强LLM在中文医疗背景下的表现。这一研究不仅针对了当前LLM在非英语环境中的局限,还可能为其他语言环境提供了一种切实可行的解决路径。
02
构建知识桥梁,提升模型性能:上下文学习框架的创新应用
本项研究的核心目标是通过构建一个全面而深入的医学知识库和问题库,引入一种创新的知识与少量样本增强上下文学习(KFE)框架,以此显著提升LLM在处理非英语临床问题时的性能。为了实现这一目标,研究团队搜集并整合了53本权威的医学书籍和高达381 149条医学问题,以此构建出内容翔实的医学知识库和问题库。这些资源不仅涵盖了广泛的医学领域知识,也包含了丰富的临床案例。
研究中,团队选用了包括ChatGPT(GPT3.5)、GPT4、Baichuan2-7b和Baichuan2-13B在内的不同规模的LLM,并将它们置于中国国家医学执照考试(CNMLE-2022)这一严格的真实临床情境中进行评估。此评估不仅关注模型在整体考试中的表现,更深入地考察了它们在各个医学科目以及临床案例分析问题上的具体性能,从而全面评价模型的医学知识和临床推理能力(图1)。

主要评价指标聚焦于模型在CNMLE-2022中的总体性能,而次要评价指标则涉及到模型对不同医学领域的掌握程度和对临床案例的分析能力。通过这些细致的评价体系,研究旨在深入理解KFE框架如何影响LLM在医学专业领域的应用效能,以及如何通过上下文学习优化模型的临床推理过程(图2)。这一研究设计不仅体现了方法学的严谨性,也展现了对模型性能全方位评估的深度考量。
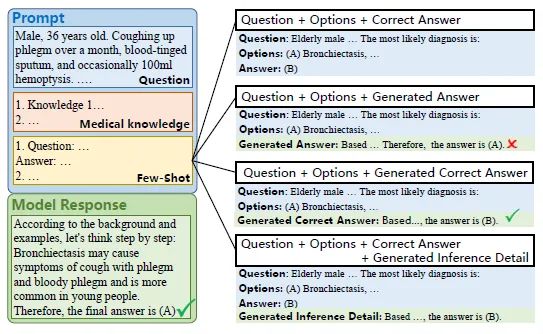
注:将检索到的示例与问题和选项结合,以增强LLM的问题解决能力图2 少量样本增强的四种策略
03
知识融合显著提升,模型表现超越人类平均水平
KFE框架显著提升模型临床推理能力,成绩飞跃
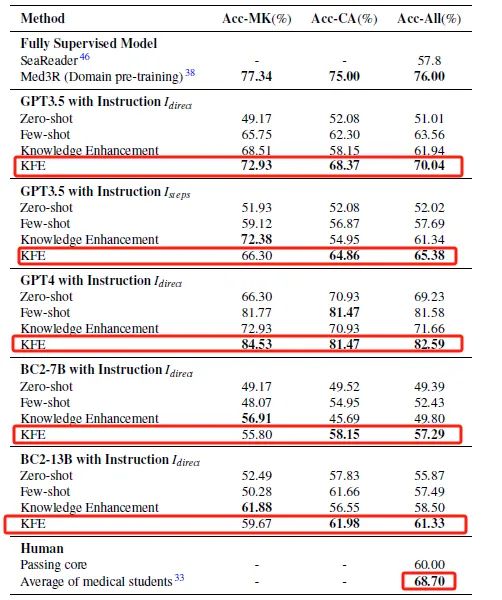
在本研究中,KFE框架的引入对LLM在临床推理任务中的表现带来了显著提升。未经KFE框架辅助的ChatGPT在CNMLE-2022中的原始得分为51分,未能达到及格标准。然而,当ChatGPT结合KFE框架后,其得分飙升至70.04分,这一成绩不仅达到了及格线,更超越了平均人类受试者的得分68.70分。更值得一提的是,在KFE框架的辅助下,GPT-4取得了82.59分的优异成绩,这一分数在所有参与测试的模型中表现最为突出(表1)。
表1 不同方法在CNMLE中的表现
多维度分析模型表现,KFE框架优势明显
进一步的分析表明,KFE框架对提升模型在医学知识问题(MK)和临床案例分析问题(CA)上的准确率具有显著效果。在KFE框架的辅助下,GPT4在处理MK问题时表现出色,准确率达到了84.53%,而在解决CA问题时,其准确率也达到了81.47%(表1)。这一结果不仅凸显了KFE框架在加强模型对医学知识的深入理解和应用上的功效,也显示了该框架在提升模型解答临床问题时的精准度和适应性。KFE框架通过整合丰富的医学背景知识和类似历史问题的解决方案,为模型提供了更为精准的决策支持,使其在面对复杂的临床情境时能够做出更加合理和准确的判断。

不同规模模型均展现性能提升,KFE框架普适性验证研究发现,不同规模的LLM,包括规模较小的Baichuan2-13B,均在KFE框架的辅助下通过了CNMLE-2022。Baichuan2-13B的成功,不仅验证了KFE框架在低资源地区医疗教育和临床实践中的应用价值,更提供了一种成本效益高的解决方案,这对于提升这些地区医疗服务水平、缩小全球医疗差距具有深远的意义。通过KFE框架的辅助,即使是规模较小的模型也能在复杂的临床推理任务中展现出与大型模型相媲美的能力,这对于推动医疗资源的均衡分配和优化医疗质量具有重要的实践价值。
KFE框架的临床应用价值与学术贡献
作者指出,KFE框架的提出与验证,不仅为非英语国家的医疗专业人员提供了一个强大的辅助工具,也为全球医疗教育和临床实践的数字化转型提供了新的思路和方法。KFE框架的灵活性和可扩展性,使其能够根据不同临床需求定制化地整合专业医学知识,进一步拓展了LLM在特定医疗领域的应用前景。此外,研究还指出了KFE框架在实际应用中可能面临的挑战,如模型对特定医学术语的理解和解释能力,以及在不同医疗环境中的适应性等,这些都是未来研究需要进一步探讨的问题。
04
总结
这项研究提出了一种新颖的上下文学习框架KFE,通过整合多样化的外部临床知识源,显著提升了LLM在中文医学环境中的表现,不仅展示了KFE框架在提升模型性能方面的巨大潜力,而且通过实证研究证明了其在资源受限环境中的适用性。研究者不仅关注模型的直接应用和性能评估,更深入探讨了如何通过上下文学习增强LLM在非英语医疗环境中的能力,为全球数字医疗领域的发展提供了宝贵的见解和方法。
9月13日,吴贤博士将作客数智医疗分论坛,带来题为“医疗大模型新进展及其应用”的主题报告,将分享更多关于如何将最新的人工智能技术与临床医疗实践相结合的前沿洞见。欢迎莅临现场,共同见证AI如何重塑我们的医疗与健康的未来。
参考文献WU J, WU X, QIU Z, et al. Large language models leverage external knowledge to extend clinical insight beyond language boundaries[J]. J Am Med Inform Assoc, 2024, 31(9): 2054-2064. DOI: 10.1093/jamia/ocae079.
编辑:梨九
二审:且行
三审:清扬
排版:耳东