全文约2200字;
阅读时间:约6分钟;
听完时间:约12分钟;

某PMC在接收客户提交的订单资料时,面临一项任务:将客户留下的联系方式进行整理并归档。然而,在整理过程中,发现客户提供的联系方式格式不一,不仅将联系人姓名、手机号码和地址全部合并在一个单元格内,而且这些信息的排列顺序各异。例如,手机号码有时出现在开头:“180****8600,湖南省芒果市金桥区,周秀”,有时则夹杂在中间:“沈卿;189****1668,苏州市新区金山路87号”,等等。
面对这样的情况,手动整理数千份订单中的客户联系信息无疑是一项极为繁重的工作。因此,迫切需要设计一个自动化公式或脚本,以便高效地从这些非标准化的输入中快速抽取联系人姓名、手机号码和地址等关键信息。
 格式分析
格式分析在着手设计该公式之前,对数据进行了深入分析。除已知问题——姓名、电话等信息被合并录入在同一单元格外,还注意到单元格内不同信息间的分隔符样式多样,既包括空格、半角逗号,也有全角逗号等不一致情况。
鉴于上述特点,可以考虑利用TEXTSPLIT函数来分解这些混杂的信息,关键在于将所有识别到的特殊符号设置为分隔条件。完成分割后,由于信息排列顺序无规律,需进一步规范,确保姓名、手机号码、地址分别对应第1、2、3个元素。这里可借助SORTBY函数实现排序,排序标准依据各部分信息的长度(通过LEN函数测定)。至此,整个处理逻辑框架已清晰规划完毕。
 数据分列
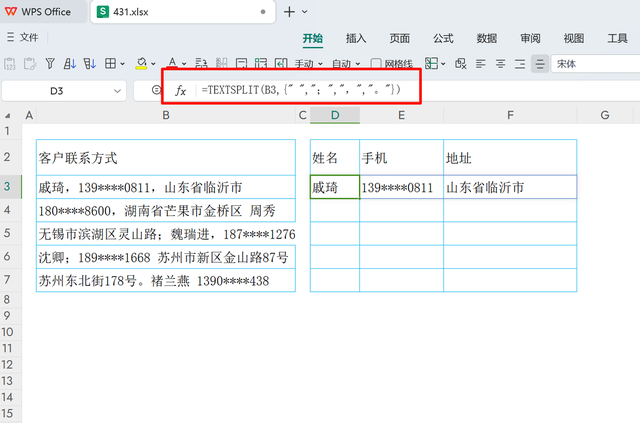
数据分列首先,应对这些混合信息进行分列处理。在此之前,需识别并定义所有可能的特殊分隔符号。随后,在适当单元格中应用以下公式执行分列操作:
=TEXTSPLIT(B3, {" ", ";", ",", "。"})
函数解释:
TEXTSPLIT函数用于根据提供的分隔符列表拆分文本字符串。在这个例子中:
B3 是待分列处理的单元格,包含需要被拆分的信息。
{" ", ";", ",", "。"} 是一个分隔符数组,包含了空格、全角分号、全角逗号和句号,用来界定不同信息的边界。
通过此公式,可以有效将合并在一起的姓名、电话号码、地址等信息依据这些不同的分隔符号分开,为后续的数据标准化和整理奠定基础。
 判断长度
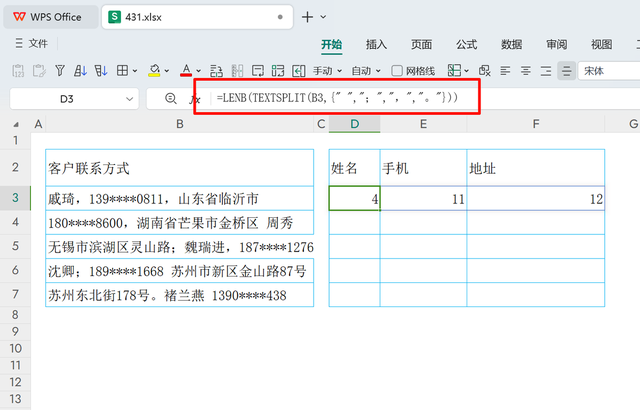
判断长度为了确保姓名、手机号码、地址能够准确对应到分列后结果的第1、2、3个位置,可以利用信息长度的不同进行排序。通常情况下,姓名最短,接着是固定长度的手机号码,地址最长。基于这一规律,在特定单元格中采用以下公式进行长度判断及排序指引:
=LENB(TEXTSPLIT(B3,{" ",";",",","。"}))
函数解释:
以单元格B3中数据“戚琦,139****0811,山东省临沂市”为例,应用上述公式后,会返回每个分隔元素的字符长度数组,即:{4,11,12}。这意味着原始信息被正确分割,并且通过计算各部分的长度(姓名4个字符,手机号11个字符,地址12个字符),可以进一步辅助进行信息的自动分类和排序。
 排序数据
排序数据在获取了各信息段的长度数值后,接下来便能开展客户信息的标准化整理工作。为了提升公式使用的便捷性与效率,我们首先定义一个变量X来存储分割后的信息数组,即 X=TEXTSPLIT(B3,{" ",";",",","。"})。随后,在合适的位置输入并向下填充至数据末尾的公式为:
=LET(x,TEXTSPLIT(B3,{" ",";",",","。"}),SORTBY(x,LENB(x)))
函数解释:
LET 函数允许创建局部变量并简化公式表达。在这里,它定义了变量 x 代表对单元格B3中内容使用 TEXTSPLIT 函数按指定的分隔符进行分割的结果。
SORTBY 函数根据提供的排序依据对数组进行排序。在这个公式中,SORTBY(x, LENB(x)) 表示依据 x 中每个元素的字节长度(通过 LENB 函数计算)进行排序。考虑到中文字符占2个字节,这样可以确保按照预期的顺序(姓名、手机号码、地址)对信息进行标准化排序。
综上所述,该公式首先利用 TEXTSPLIT 对数据进行分割,然后通过 SORTBY 结合 LENB 确保分割后的信息能按照姓名、手机号码、地址的逻辑顺序进行正确排序,从而实现客户信息的有效整理。
一键填充为了提高公式填充的准确性和效率,可以采用数组公式来一次性处理多行数据,减少手动操作的错误风险。具体转换后的数组公式如下:
=DROP(REDUCE("",TOCOL(B3:B2000,3),LAMBDA(X,Y,VSTACK(X,LET(x,TEXTSPLIT(Y,{" ",";",",","。"}),SORTBY(x,LENB(x)))))),1)
公式解释:
初始值设定:以空字符串 "" 作为 REDUCE 函数的初始累积值。
数组构建:使用 TOCOL(B3:B2000,3) 构建一个数组,该数组包含B3至B2000范围内所有非空单元格的值,参数3指示跳过空值,确保处理的是实际有效的数据行。这一步骤为后续处理提供了一个动态的数据源。
函数应用:在 REDUCE 函数中,通过一个匿名 LAMBDA 函数逐项处理数组中的每一个单元格 Y。对于每一项,先用 TEXTSPLIT 分割单元格内容,然后用 SORTBY 根据字节长度对分割后的信息进行排序,这部分处理结果由 LET 函数临时存储为变量 x。最后,利用 VSTACK 将当前行处理后的结果堆叠到累积值 X 上,逐步构建整个结果数组。
最终调整:使用 DROP 函数去除结果数组的第一行(即初始空值所在行),确保输出结果直接从实际数据开始,没有不必要的空白。
综上所述,这个数组公式不仅自动化处理了数据分列、排序和整合的过程,还能动态适应数据范围的变化,提高了工作效率并减少了潜在的错误。。
 最后总结
最后总结通过上述步骤的详细解析,我们不仅揭示了解决复杂数据整理问题的策略,还展示了如何利用WPS高级函数如TEXTSPLIT、SORTBY、LET以及数组公式等,来实现数据的高效自动化处理。此方案针对某PMC面临的客户联系方式整理难题,提供了一套从分析、分列、排序到一键填充的完整解决方案,极大降低了人工处理的负担,提升了信息归档的准确性和时效性。
特别强调的是,通过灵活运用现代电子表格工具的强大功能,即便是面对格式不一、排列无序的大量数据,也能设计出既智能又高效的处理流程。这不仅优化了日常办公的操作流程,还为企业或组织在处理大规模数据时提供了宝贵的技术参考和实践路径,证明了技术进步在提升工作效率方面的巨大潜力。
总之,本文展示的解决方案不仅解决了某PMC的具体挑战,也为各行各业在处理非结构化数据时提供了一个典范,强调了数据分析预处理阶段的重要性,以及如何利用现代技术手段克服此类挑战,确保数据后续分析或存储的精确性和流畅性。这种创新方法的应用,无疑是对数字化时代背景下,提升工作效率和质量的一次成功探索。