1. 大模型的开发训练与推理部署
随着模型参数规模和网络结构的不断升级,大模型开发、训练和推理部署所面临的挑战日益严峻。为应对这些挑战,研发需依赖算法、算力和数据的全面支持。深度学习框架及其配套工具为大模型的生产和应用奠定了基础,涵盖了开发、训练、压缩、推理和服务等多个环节。同时,框架还能实现与硬件的适配和协同优化,从而提高硬件的计算和推理性能,降低大模型开发和应用的成本。
1.1 大模型开发与训练
由于大模型参数规模大,计算和存储的需求显著增加,与辨别式AI 模型相比,非常依赖分布式技术提升效率。因此,大模型开发的挑战集中体现在基于深度学习框架对各类分布式并行策略进行本地化配置。
为了支持各种分布式并行策略,需要有一套简单、灵活、高效且易于使用的框架和工具界面,使用户可以快捷地进行模型训练和调优,并方便地配置和管理大规模的并行任务。
大模型开发也离不开高效的调试工具及方法支撑,非常依赖动态图的调试机制、清晰的调试日志和可视化的调试界面等,帮助开发人员更好地分析模型的行为和表现。
大模型的训练挑战在于如何在有限的计算资源下,实现高效的收敛和提升训练吞吐量。为此,我们致力于系统级优化,包括模型计算、显存、内存和通信,以确保在保持优良模型性能的同时,充分利用现有资源。
系统级优化方法主要从两个方向实现:
深度学习模型训练中,设备内优化方法至关重要。这些方法主要集中在降低计算和内存开销上,包括半精度浮点优化、混合精度浮点优化等手段,以减少浮点数的冗余表示。同时,我们还采用梯度检查点(Checkpointing)技术,进一步优化梯度计算过程中的冗余表示。此外,为了更有效地管理GPU内存,我们采用了ZeRO-Offload方法,该方法将数据和计算从GPU卸载到CPU,显著降低了神经网络训练期间的GPU内存占用。这些优化策略共同提升了训练效率,助力AI研究者快速实现高性能模型。
多设备优化方法也称分布式优化,即将分布在不同计算节点上的多个 GPU 一起用于训练单个模型,这类方法主要有数据并行、张量并行、流水线并行、分组参数切片并行等多种并行加速策略。
数据并行是一种常见的分布式并行策略,它通过将大数据集分割成多个小批次或子集,然后在多个处理器上同时进行模型的训练。在反向计算出参数梯度后,对参数梯度做 AllReduce 聚合,然后每个处理器独立进行参数更新。数据并行的优点是实现和使用方式简单,可以通过增加数据并行路数提高训练吞吐,是目前最为常用的分布式并行策略之一 。
张量并行是一种将神经网络中同一层的张量运算拆分成多个独立的子运算,并相应地对模型参数做切分,由不同的处理器分别执行,生成的中间结果通过分布式通信进行组合的技术。它可以充分利用多核处理器的计算能力,减少内存访问延迟,但需要设计高效的并行算法和通信机制来确保计算正确性和高效性,避免通信延迟和带宽瓶颈。
"并行策略:此模型采用流水线并行,即各处理器执行网络的不同层。点对点通信确保了上下游的依赖性。高效的调度策略如1F1B和Interleaving 1F1B优化了训练过程,利用“通信-计算”重叠减少了通信时间,从而大幅提升了整体训练效率。"
分组参数并行是一种特殊的数据并行方式,它可以将优化器状态、参数梯度和模型参数切分到不同的处理器上,达到节省大模型显存的目的。这种并行策略的优点是可以有效降低模型显存占用,通过增加数据并行路数提高整体训练吞吐。基于此技术的“组内参数切片+组间数据”并行,可以更合理地分配机内和机间的通信带宽,进一步提升了训练性能。
基于上述基础并行策略,不同深度学习框架的实现方法各异。例如,微软的DeepSpeed-Megatron、NVIDIA的Megatron-LM和清华大学的BMTrain等,均是基于PyTorch进行进一步封装的独立工具。飞桨PaddlePaddle框架则支持四维混合并行技术,可将基本的并行策略巧妙融合使用。
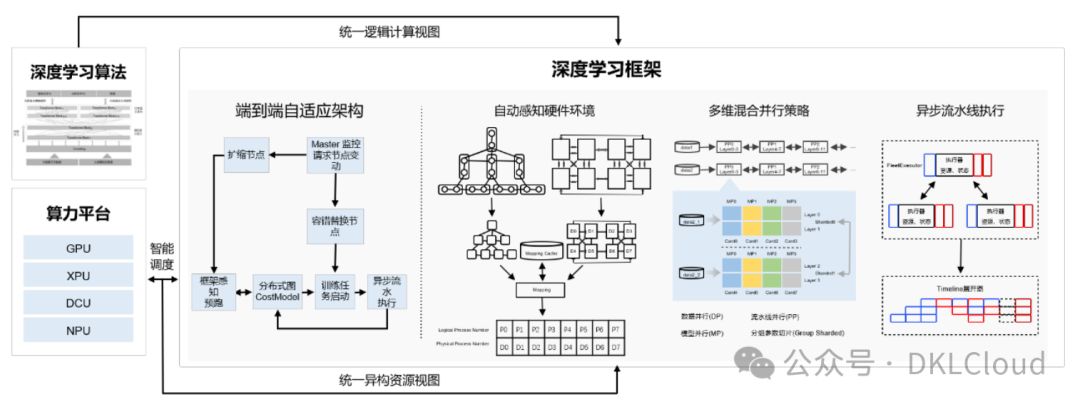
图 1-1 端到端自适应分布式训练架构
"我们的架构将深度学习算法与硬件环境抽象统一,创建了异构资源视图。借助代价模型,我们实现了算法与硬件的联合建模。模型参数、梯度和优化器状态在最优策略下分配到不同的设备上,构建流水线以实现高效的异步执行。"
跨地域多硬件异构,助力存储节省、负载均衡及训练性能提升。弹性资源调度管理机制应对大模型训练资源不稳定问题。
在资源变动时,自动感知硬件环境并调整资源视图,实现模型切分、放置策略选择及异步流水线执行。硬件故障下任务恢复时间从小时级缩短至秒级。
1.2 大模型推理部署
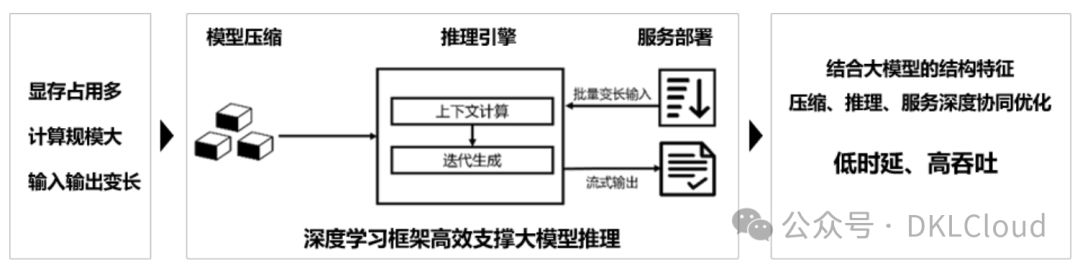
图 1-2 模型压缩、推理引擎、服务部署三个环节协同优化
在深入剖析大模型结构特性的基础上,我们从模型压缩、推理引擎和服务部署三个关键环节出发,致力于全方位协同优化。这一策略旨在降低时延,提升用户体验的同时,最大化服务吞吐量,实现低时延与高吞吐的完美平衡。
大模型的推理可以采用深度学习框架直接实现,通过框架和模型协同优化,可以显著提升大模型的推理效率;也可以采用专门的工具,如:FasterTransformer、TensorRT-LLM、vLLM、Text Genertion Inference、HuggingFace TG 等实现,这些工具已经针对大模型推理进行了优化,能够高效地完成推理任务。大模型推理效率的提升,不仅可以提升用户体验,还能显著降低开发成本,有利于大模型在千行百业的广泛应用。
产业界高度关注大模型推理性能优化,如ChatGPT组建专业团队降低在线推理成本;百度文心一言与飞桨协同提升推理性能30倍以上;腾讯混元大模型通过太极机器学习平台压缩和分布式推理,减少资源设备占用40%。
1.3 大模型压缩
权重矩阵分解:通过诸如奇异值分解(SVD)等矩阵分解技术,对预训练模型中的前馈神经网络(FFN)层权重矩阵进行分解,从而降低注意力层(Attention)的参数量,提升模型性能并节省计算资源。
"精简模型参数,我们探索了ALBERT的独特之道。它采用权重共享策略,让特定层之间的参数互通有无,从而大幅降低模型的复杂度。此外,蒸馏技术也发挥了重要作用,通过模拟预训练教师模型的行为以学生模型为基础,有效地减小了模型的规模。这是模型优化的新视角,让我们共同期待更轻盈、高效的AI未来。"
在日常应用中,学生模型通常由更小的神经网络或线性模型构建。蒸馏技术则是一种有效的知识传递方式,它能将教师模型的丰富知识转移至学生模型,从而使学生模型在保持小规模的同时,仍具备类似教师模型的预测能力。这一技术有助于实现大模型知识的迁移与小型网络的支持,进一步推动轻量化大模型部署的发展。
量化:一种将预训练模型权重从浮点数降维至低位数的技。精度可降至8位或更低,大幅减小存储和计算需求,但可能对性能产生一定影响。
"大模型压缩中,我们采用量化技术,但激活分布的异常值问题阻碍了无损模型效果的实现。为此,自适应 Shift-SmoothQuant 方法应运而生,有效平滑激活分布,显著提升大模型量化效果。"
超大模型精度无损的压缩技术,可以通过组合使用模型稀疏化、蒸馏和参数共享等压缩技术,将模型参数量压缩至百分之一、甚至千分之一左右。例如,组合使用低比特量化和模型稀疏化,同时从数值和结构两个维度对大模型的冗余信息进行精简,协同优化计算和访存算子,可以进一步提高压缩率。
为了使文章更加简洁明了,我建议删除一些不必要的细节,并将重点放在压缩技术的介绍上。同时,可以使用更具有吸引力的语言来吸引读者的注意力。
超大模型的压缩是一个重要的问题。通过组合使用模型稀疏化、蒸馏和参数共享等压缩技术,可以在精度无损的情况下,将模型参数量压缩至百分之一、甚至千分之一左右。例如,组合使用低比特量化和模型稀疏化,同时从数值和结构两个维度对大模型的冗余信息进行精简,协同优化计算和访存算子,可以进一步提高压缩率。
1.4 大模型推理与服务部署
在推理引擎领域,通用技术包括自动计算图融合优化和自动混合并行推理。这些技术实现对模型结构和计算硬件的自动感知,协同提高模型推理效率。自动计算图融合优化通过非侵入方式匹配高性能融合算子,降低算子数量、减少访存次数,从而实现自动化推理加速。
自动混合并行推理:利用智能感知硬件特性,如存储、带宽和算力,自适应划分大模型至多部署硬件,实现分布式并行推理。大幅减少卡间及跨机通信,轻松部署千亿、百亿参数模型。
除了技术提升,推理引擎的优化还可以通过协同模型压缩和开发适应大模型特性的量化推理策略来进一步强化。例如,对于大型语言模型,其上下文计算环节对计算资源需求较高,而Token生成阶段则更依赖内存访问。
针对这一计算特性,我们提出协同硬件优化策略,研发LLM.INT8()和Weight Only量化混合推理方案。这种方法能实现快速量化,同时保持高精确度,尤其在访存受限场景中表现优秀。
在服务化调度协同方面,针对生成式模型计算过程中的输入输出长度不一致问题,我们采用变长优化技术降低计算量。同时,引入动态插入批处理技术,大幅提升硬件资源利用率,从而提高整体服务吞吐量。
动态插入批处理技术,具备感知负载能力,实现请求快速插入。结合输入输出长度动态调整,提高GPU资源利用率,降低用户等待时延。
1.5 软硬件适配与协同优化
目前,全球大型模型训练芯片市场主要由英伟达GPU(如H100、A100)和谷歌TPU主导。在国内,我们有华为昇腾NPU、昆仑芯XPU、海光DCU以及寒武纪MLU等优秀产品。这些芯片在架构和性能规格上各有特色,满足了不同场景的需求。大型模型训练对芯片的计算性能和硬件规格有较高要求,如显存大小、访存带宽和通信带宽等。
为提升大模型训练与推理效率,需借助深度学习框架实现硬件适配与深度协同优化。通过低成本、高效率的硬件适配策略,加强大模型与硬件的契合度。同时运用混合精度、显存复用、融合优化等软硬件协同技术,充分利用硬件特性,实现系统级优化。
1.6 大模型的软硬件适配
深度学习框架需提供标准化硬件适配接口,以适应异构硬件。针对AI芯片在指令集、开发语言、加速库、计算图引擎、运行时环境和通信库等方面的差异,需根据技术栈提供差异化硬件接入方式,包括算子适配、通信库适配和设备驱动适配等多个方面。
在算子适配方面,我们有两种策略:算子映射和框架算子库对接硬件算子库。通过提供单算子粒度的接入方式,我们可以让框架执行器调用并执行硬件算子库接口。这种方法适用于底层硬件 SDK 支持硬件算子库的情况。
算子开发:芯片厂商提供完善的高级开发语言,如NVIDIA的CUDA C,助力深度学习框架实现算子代码。通用性佳,支持大量算子开发,但研发难度和成本较高。
神经网络编译器接入:利用深度学习框架的神经网络编译器将中间表示(IR)与硬件代码生成器(Codegen)对接,实现从编译器 IR 到底层硬件 IR 的转换。接着,编译器负责算子融合和调度,以适应支持代码生成的底层硬件 SDK。
1.7 大模型的软硬件协同优化
为了提高大模型在硬件上的运行效率,深度学习框架需要在显存优化、计算加速和通信优化三个方面进行优化。在显存优化方面,框架支持多层显存复用、重计算和低比特量化等技术,从而降低大模型对硬件显存的需求。
框架采用混合精度和算子融合优化等技术,借助硬件 Transformer 大算子库为生成式大模型提供深度融合优化,从而大幅提升大模型的计算性能。
在通信优化方面,框架具备自适应拓扑优化技术,能感知硬件集群环境并搜索最优并行策略。它支持大规模模型在不同规模集群下高效训练,提高性能的同时降低开发者配置门槛。
TPU(张量处理单元)硬件加速技术,针对深度学习计算进行定制优化,与通用CPU和GPU相区隔。其独特设计能满足大规模模型训练的苛刻需求,助力AI领域突破计算瓶颈。
ASIC(Application-Specific Integrated Circuit)加速器是一种专门设计的集成电路,用于解决特定的应用场景。 ASIC 加速器通常具有更高的性能和更低的功耗,相比于通用的 CPU 和 GPU。
ASIC(Application-Specific Integrated Circuit)加速器是一种定制化的集成电路,专门为某个特定应用场景而设计制造。
ASIC 和 FPGA 都是硬件加速技术,但它们的优势不同。ASIC 能够实现高度优化的电路结构和算法,从而提高性能和能效;而 FPGA 则具有灵活性和可编程性,可以根据不同的应用场景进行定制化设计。
FPGA,一种神奇的可编程逻辑芯片,以其高度灵活性和强大的可编程性脱颖而出。通过编程方式实现各种逻辑电路,FPGA 集成了大量逻辑单元和存储单元,轻松应对布尔逻辑运算与算术运算的挑战。更妙的是,它还能与其他电路和设备无缝通信,让集成变得更加简单高效。
云服务在大规模模型训练中发挥着至关重要的作用,为其提供了强大的计算和存储资源。诸如 AWS、Azure、Google Cloud 等云服务供应商,以及百度智能云、阿里云、腾讯云、华为云等,均提供了一系列深度学习服务和工具,涵盖了模型训练、部署及自动伸缩等方面。这些云服务能够根据实际需求和流量波动,实时调整计算资源规模和配置,确保高效且可靠的服务运行。
大模型推动了软硬件协同优化的挑战与机遇。为支持其研发与广泛应用,我们需要对硬件进行全面适配并开展极致的软硬件协同优化。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-