引用格式:王孝焱,孙秀彬,纪伊曼,等.群组多轨迹模型在纵向数据研究中的应用及实例分析[J].中华流行病学杂志,2024,45(11):1590-1597.DOI:10.3760/cma.j.cn112338-20240529-00314

王孝焱,孙秀彬,纪伊曼,张涛,刘云霞

摘 要
纵向队列的发展为识别和监测影响疾病病程或健康状况的多种生物标志物及行为等因素创造了条件。然而,传统统计方法通常只能利用单变量纵向数据的信息进行研究,无法充分利用多变量纵向数据信息。群组多轨迹模型(GBMTM)是近年来提出的研究多变量发展轨迹的一种方法,通过影响目标结局的多个指标来识别遵循相似轨迹的潜在人群亚组,在处理多变量纵向数据中具有独特优势。本研究阐述GBMTM的基本原理,并运用一项基于智能穿戴设备的老年人健康管理研究的数据探索多种生活相关指标与高血压的关系,展示GBMTM的具体应用,以期促进其在纵向队列研究中的应用。
【关键词】纵向数据:群组多轨迹模型:发展轨迹:队列研究

前 言
随着数据采集和存储技术的创新与发展,临床治疗、预后随访、健康体检及健康管理等医学领域中产生了大量的纵向数据[1]。纵向数据指每一个体在不同观测时点的测量值集合,其中包含了很多随时间或年龄变化而变化的变量,如血压、体重等,此类变量也被称为时依变量[2]。时依变量在时间线上依次排列而形成的轨迹被称为发展轨迹,其能够动态描述变量随时间的变化特征[3]。在医学领域中,识别和监测时依变量不同的发展轨迹亚组具有重要意义,如可进一步分析轨迹分组的决定因素或不同轨迹组不良健康结局的风险因素等[4]。传统的统计分析方法中,有一些能够对发展轨迹有相似进程的集群亚组进行识别,如建模较为简单灵活的群组轨迹模型(GBTM)[3]和适用于较复杂数据的潜在类别混合模型[5]等。
然而,疾病的发生和发展通常是由复杂的、相互依赖的多个时依变量相互作用的结果[6]。传统的统计方法一般仅能利用其中关于疾病进展过程的单一变量信息,而无法充分利用多个变量的发展轨迹及其相互作用的信息。为解决这一问题,Nagin等[6]于2018年对传统GBTM进行了改进,使其通过对多个感兴趣的变量(时依变量)定义轨迹组,即通过同时分析多个变量的联合轨迹,识别潜在的个体集群,因此被称为群组多轨迹模型(GBMTM)。本研究对GBMTM的基本原理及分析步骤进行阐述,并结合实例展示该方法在纵向队列研究中的具体应用,为其在医学相关研究中的应用提供参考。
基本原理
1. GBTM:



2. GBMTM:

3. 最优组数及多项式参数的选择:
GBTM及GBMTM的选择通常包括2步[8-10]。第一步选择最优轨迹组数:轨迹组数由1开始,轨迹的最高多项式次数固定为3(三次项),在此基础上增加轨迹组数,依据贝叶斯信息准则(BIC)、平均后验概率(APPA)、正确分类优势(OCC)及组成员比例选择最优轨迹组数:
①BIC尽可能接近0;
②各组APPA>0.7;
③各组OCC>5.0;
④各组至少包含5%的参与者[3,10]。
第二步选择轨迹形状:在确定最优轨迹组数基础上,对每条轨迹从高阶三次项开始拟合,若高阶多项式次数无统计学意义则继续拟合低阶多项式次数,一次项即使无统计学意义也要将其保留在最终模型中。
选择合适的轨迹组数是轨迹分析的关键问题,研究中不能仅依赖于上述统计学评价标准,还应综合考虑模型的解释能力、复杂性和实用性等[3,10]。最佳模型需要确保能够以最简洁和实用的方式概括数据特征;同时,还要避免过度拟合数据。如果额外的亚组并未捕捉到与其他亚组截然不同的轨迹,为简约起见,则更倾向于选择较少数量的轨迹亚组[10]。目前模型构建可以通过SAS软件的Proc Traj过程、Stata软件的traj程序包和R软件的gbmt程序包实现[6,11]。
实例分析
1. 数据来源及统计分析:
(1)研究设计与来源:
实例数据来自于一项基于智能穿戴设备的老年人健康管理研究[12]。在2018-2022年(以3个月为1季,共20季),纳入基线未患高血压的11 090名参与者,研究终点为参与者被诊断为高血压,随访时间截至2022年12月31日。排除标准:
①测量值异常及重要协变量信息缺失者(n=1 024);
②基线至研究终点或随访截止时间内随访季数<3者(n=5 276)。
最终共4 790名参与者纳入研究。
(2)纵向测量指标:
睡眠时长(包括清醒时长、深睡眠时长、浅睡眠时长,min)、运动量(cal)和心率(次/min)均通过统一配备的智能运动手环监测。研究中计算深睡比(即深睡眠时长/睡眠时长)和各项指标的季平均值纳入分析。
(3)协变量:
年龄(岁)、性别、文化程度、居住形式和慢性病患病情况等通过问卷调查收集;BMI通过体脂秤获得。
(4)结局事件:
通过手臂式电子血压计进行血压监测,SBP≥140 mmHg(1 mmHg=0.133 kPa)和/或DBP≥90 mmHg则认为参与者发生高血压[13]。计算季平均SBP和DBP纳入分析。
(5)统计学分析:
计量资料不符合正态分布,采用M(Q1, Q3)表示,两组间比较采用Mann-Whitney U检验,多组间比较采用Kruskal-Wallis检验。计数资料采用频数和构成比(%)表示,组间比较采用检验。利用GBTM分别对运动量、深睡比和心率进行单变量轨迹分析,并通过GBMTM识别运动量、深睡比及心率的联合轨迹分组;进而采用Cox比例风险回归模型,评估不同轨迹亚组与高血压发生风险之间的关联。双侧检验,检验水准α=0.05。
2. 结果:
(1)基线特征:
4 790名参与者的随访时长M(Q1, Q3)为7(4, 11)季,随访期间共529名发生高血压。未发生高血压者随访次数M(Q1, Q3)为6(4, 10)次,发生高血压者随访次数M(Q1, Q3)为5(4, 7)次。未发生高血压人群年龄M(Q1, Q3)为69(64, 75)岁,发生高血压人群年龄M(Q1, Q3)为72(66, 78)岁。
(2)GBTM分组:
本研究所识别的单变量轨迹见图1,按轨迹特征进行分类:低运动量组(56.2%)、中等运动量组(34.9%)和高运动量组(8.9%),低深睡比组(25.6%)、中等深睡比组(58.3%)和高深睡比组(16.1%),低心率组(27.2%)、中等心率组(48.3%)和高心率组(24.5%)。

(3)GBMTM分组:
基于GBMTM拟合轨迹过程中的逐步筛选指标,结果显示,轨迹组数为5的模型其BIC值优于轨迹组数为4的模型,拟合指标均达到推荐值。然而,轨迹组数为5的模型中并未发现与轨迹组数为4的模型有实质性差异的组。见表1。

为简单起见,本研究最终选择轨迹组数为4的联合轨迹模型,按轨迹特征分别命名为:低运动量-高深睡比-中等心率组(组1)、低运动量-低深睡比-高心率组(组2)、较低运动量-低深睡比-低心率组(组3)和高运动量-较高深睡比-中等心率组(组4)。其中,组1各项纵向指标的变化趋势均较为平稳且深睡比最高;组2心率水平最高;组3与组2的差异主要体现在心率水平及变化趋势不同,组3心率水平低且呈下降趋势;组4运动量最高。见图2。

各轨迹组中组1中女性比例最低,组2中高脂血症患者比例最低,组3中BMI水平较高且冠心病患者比例较高,组4的随访时长最短。不同轨迹组间的基线运动量、深睡比及心率差异有统计学意义(均P<0.001)。见表2。

(4)不同轨迹分组的高血压发生风险:
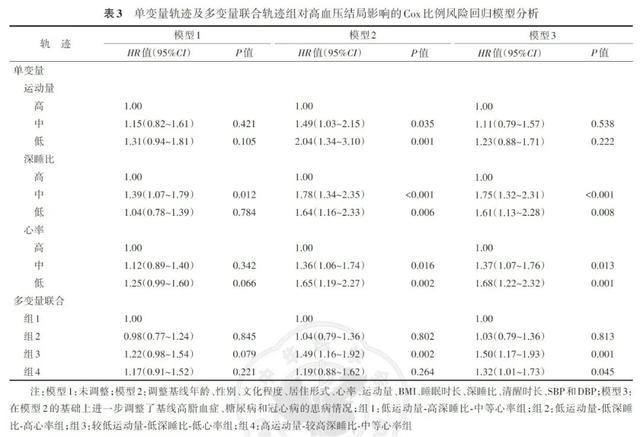
在单变量轨迹分析中,深睡比轨迹组及心率轨迹组与参与者高血压发生风险间有统计学关联。在调整混杂因素的模型3中,以高深睡比组作为参照,中等深睡比组和低深睡比组的风险比(HR)值(95%CI)分别为1.75(1.32~2.31)和1.61(1.13~2.28),以高心率作为参照,中等心率组和低心率组的HR值(95%CI)分别为1.37(1.07~1.76)和1.68(1.22~2.32)。在多变量联合轨迹分析中,以组1(低运动量-高深睡比-中等心率组)作为参照,在调整混杂因素的模型3中,组3(较低运动量-低深睡比-低心率组)和组4(高运动量-较高深睡比-中等心率组)的HR值(95%CI)分别为1.50(1.17~1.93)和1.32(1.01~1.73),而未发现组2(低运动量-低深睡比-高心率组)与参与者高血压发生风险间有统计学关联。见表3。
讨 论
本研究利用穿戴设备记录的随访数据介绍了GBMTM在队列研究中的应用。研究中基于多个纵向变量构建了GBMTM,与只考虑单一指标纵向变化的研究相比[14-16],同时考虑了多项生活相关指标的纵向变化,能够捕捉多种维度的共同变化,为改善生活方式以提高健康水平提供了新的见解。对多变量纵向数据进行联合轨迹分析能够将更多的信息纳入到建模过程中,有利于识别到更具有临床意义或更深入的生物学见解的分组[17]。
近年来,针对多个变量发展轨迹的聚类分析方法不断涌现,如GBMTM、多变量潜在类别混合模型(MLCMM)[5,18]和贝叶斯一致聚类模型(BCC)[19]等基于模型的方法,以及K均值聚类[20]等基于算法的方法。值得注意的是,上述基于模型的方法均需要轨迹形式和随机效应分布形式的假设,但在如何对随机效应进行建模方面存在差异,GBMTM假设不存在随机效应,而MLCMM假设亚组间的随机效应分布存在差异,但在变量间无差异[21]。虽然后者建模更灵活,但其假设所有变量具有相同的随机效应分布,这在实际中可能是不现实的,特别是当每个变量代表不同的生物过程时。相比而言,BCC则假设随机效应在亚组和变量之间均存在差异,并且进一步假设如果给定潜在类别,不同变量的随机效应分布是独立的。另一方面,基于算法的方法不需要关于轨迹形式和随机效应分布形式的假设,因此可更灵活地捕获曲线的形状,特别是在分析非多项式轨迹时。然而,此类方法无法量化分组的不确定性,其要求测量值无缺失且在固定时间点记录[22]。由于目前尚无相应的统计学检验方法来评估这些假设,故很难在实际中进行验证。因此,需要在具体研究设计和学科知识的基础上仔细考虑这些假设,并对可能的模型进行相互比较[17]。与其他方法相比,GBMTM具有以下优势:
①不同变量的测量时间可以是不同尺度(如年、小时或分钟);
②能够同时对多个不同类型的变量进行聚类分组(如连续变量、离散变量和分类变量);
③允许数据含有缺失值;
④允许通过后验聚类概率量化组内成员的不确定性;
⑤分组结果易于解释。
研究中识别出潜在的轨迹分组之后,常见的后续分析策略是将确定的轨迹分组与临床结局或感兴趣的暴露相联系。根据分析目的,轨迹分组既可以作为后续分析中的自变量,也可以作为结果变量[23-29]。例如,利用GBMTM探索多种生理生化指标的联合轨迹亚组人群心血管疾病发病风险的差异,不仅可以提高个体特定集群概率的准确性,还能充分考虑众多临床相关指标之间的相互关系[23-28]。
目前,GBMTM在应用中仍有一些问题需进一步探索。首先,模型选择是一个具有挑战性的问题。模型选择的一个关键步骤是确定轨迹组的数目,其在多变量轨迹分析背景下更加复杂。样本量、变量的数目和类型、不同变量的观测值数量、不同变量值的缺失数和缺失模式以及潜在的轨迹形式(如线性或非线性)等因素对轨迹组数目的影响程度仍然是未知的[17]。其次,确定纳入模型的时依变量也是一项挑战。目前的研究多依靠相关领域的知识选择变量,而不是数据驱动的变量选择方法。开发一种数据驱动的方法来帮助选择纳入模型的变量,以去除那些对识别个体集群没有贡献的变量,将有助于建立一个简约的模型,从而具有更好的分组性能[30]。第三,现有研究只考虑了少量时依变量下GBMTM的表现,在高维数据和大样本情景下的表现如何,以及计算速度如何,值得未来进一步探讨。第四,当缺失数据为随机缺失时,极大似然估计将提供渐近无偏的参数估计[6],但在多个时依变量轨迹分析背景下非随机缺失数据的处理方法尚未得到充分探索,因此针对纵向数据中缺失数据填补问题的研究亦具有重要意义。
综上所述,多变量轨迹分析在大数据时代变得越来越重要,同时也是一个活跃的研究领域,仍存在许多开放性和挑战性的问题。电子医疗大数据的兴起和应用,为识别和监测人们生活中影响疾病进程、健康状况和行为模式的各种生物标志物和其他因素的进展提供了难得的机遇。GBMTM旨在解决这一需求,其充分地考虑了多个临床相关指标之间的相互关系并具有独特的优势,相信在今后会有更广泛的推广和应用空间。

参考文献
 下载全文
下载全文