一、背景介绍
Trace、Metrics、Log是APM系统(Application Performance Management,应用性能管理)的三大支柱。过去云音乐使用的Metric监控体系与APM分属不同系统,使用时相互之间没有联动,导致Metric与Trace完全割裂,问题定位中将二者关联起来时需要一定成本;另外不同系统的数据视角不同,使用风格也有较大区别,导致总体问题分析能力较弱。
为此,云音乐中间件团队规划建设了新版应用服务端监控体系(Pylon APM),重新实现了Metric体系,选型了作为云原生监控标准的Prometheus作为Metric监控基础。而云音乐庞大的服务规模,多样的监控需求也对Metric时序存储的可靠性、可用性及性能带来了很大挑战。我们最终形成了围绕VictoriaMetrics(以下简称VM)体系的Metric架构,旨在解决以下问题:
应用层Metric可观测性弱:过去音乐内部Metric监控以机器层面的Metric监控为主,虽也提供了常用框架的监控插件,但无论是性能还是可视化效果都有一定改进空间,问题排查效率低;Metric关联到Trace的问题:Metric是发现问题最直观的方式,比如“接口错误数10”,但还需要Trace协同工作才能定位到发生错误的根因;性能与成本问题:旧版Metric监控数据存储成本较高;而社区版Prometheus单体应用,无法支撑音乐如此大的数量级。需要一套高可用而低成本的数据采集、数据存储方案;数据维度大,聚合查询吃力:监控数据时常应对聚合查询,应用层数据的采集维度很大,若直接查询原始数据往往需要数秒甚至数十秒,严重影响问题排查;可视化能力弱,缺乏灵活的数据对比:监控数据时常需要同环比、多实例比较等手段来帮助定位问题,Prometheus UI和可视化工具Grafana都没有支持这项功能。为解决以上问题,我们对围绕VM时序采集、聚合、Grafana可视化做了深度扩展,最终达成以下目标:
Metric关联到Trace的问题排查:解决信息孤岛,从Metric入手可下钻到Trace、Log排查问题;高效的Metric监控可视化与图表分析能力:我们设计了丰富、直观、多维度的Dashboard,使用户能够在第一时间观测到Metric存在的问题,还改造Grafana提供了图表分析能力,大大提升问题分析效果;高性能、低成本的采集存储方案:我们采用VM作为Prometheus的替代存储方案,以较低的成本支撑了音乐Metric监控;毫秒级的聚合数据查询:为了解决数据聚合、查询效率低的问题,我们实现了时序数据预聚合Recording Rules服务和查询代理Proxy服务。受益于此,常用的大维度数据聚合查询得以在毫秒级完成。二、项目思路和方案
1、选型与架构
Prometheus定义了云原生监控体系,但由于社区版性能较差且对数据持久化、高可用的支持较弱,衍生了很多数据远程存储方案,用以支持高可用、超大量级的数据。目前主流方案有VictoriaMetrics、M3DB、InfluxDB等。
其中VM以其极高的性能、对Prometheus生态的完整替代、其重新实现的PromQL进化版-MetricQL等优秀的特性,得到了业界的高度认可和广泛使用,故我们选型了基于VM来实现我们的Metric监控方案,关于VM与其他TSDB的性能对比可以参考VM作者的文章。
基于VictoriaMetrics的Metric方案整体架构如下:
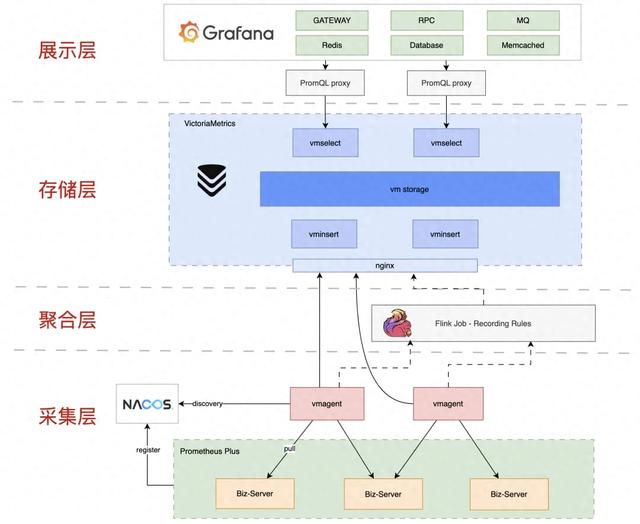
架构可分为采集链路、查询链路:
采集链路负责将Metric数据分片收集、预聚合后存储到vmstorage(VM的存储引擎)中,由以下组件组成:Exporter:内嵌在业务服务中的Prometheus SDK,暴露数据采集端口;vmagent:负责数据采集;Nacos:注册中心,负责vmagent和Exporter之间的服务发现。监控数据采集的服务发现节点量级较大,对一致性的要求没有可用性和性能的要求高,故我们选型Nacos,并对其做了兼容Prometheus服务发现的补充;Recording Rules:自研的Flink任务,负责Metric数据的流式预聚合;vminsert:VM集群模式的组件之一,负责数据写入;查询链路负责优化数据查询语句,查询存储引擎,由以下组件组成:Grafana:数据可视化,我们将其二次开发支持了数据同环比、多实例比较;proxy:自研的查询代理,负责解析并优化PromQL;vmselect:VM集群模式的组件之一,负责数据查询。2、监控数据采集、预聚合和查询方案
问题背景
一条完整的Metric数据结构如下:

在此结构下应用层Metric监控数据label-value键值对取值情况多,其组合数量是乘积的关系。遇到大维度聚合查询,对存储层的查询压力很大,延迟较高,严重影响问题排查的效率。
比如我们监控一个API网关服务,集群中有200台实例,注册有10000个API,平均每个API有10种返回code,则按集群查询总的code分布情况时,存储层需要聚合的时序量有:
200 * 10000 * 10 = 20000000 条。

我们尝试了社区开源的后置聚合方案Recording Rules,发现后置聚合对存储层的压力并未缓解,整体性能并不高,并不能达到优化整体查询性能的目的。
解决方案
由于时序数据不断增长的特点,数据预处理提高查询时效率较好的解决方案。经过测试,开源方案后置聚合(数据存入存储引擎后,再查询出来聚合)的方式不能满足我们的性能要求,故我们基于Flink设计实现了预聚合的Recording Rules服务,另外为了让用户更方便地使用聚合数据,我们设计了查询代理Proxy。
预聚合的Recording Rules
预聚合服务负责将用户经常需要使用的大维度聚合查询提前的聚合,提高查询效率。
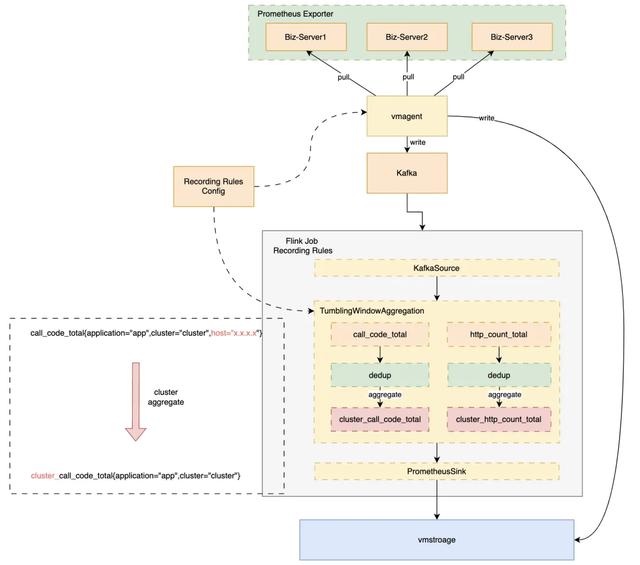
Prometheus体系下的Metric数据是时间连续的,每隔一个interval都会有一组数据上报,非常符合流式数据窗口聚合处理的特点,故我们选型大数据领域广泛使用的Flink来实现数据预聚合Recording Rules。
整体架构为:vmagent将采集上来的原始数据双写,一份直接写出到存储层,另一份写出Kafka中,由Recording Rules消费,经过滚动窗口聚合后,写出到vmstorage中。方案如下图:
经预聚合,大维度查询RT从数秒降低到毫秒级。
 查询代理Proxy
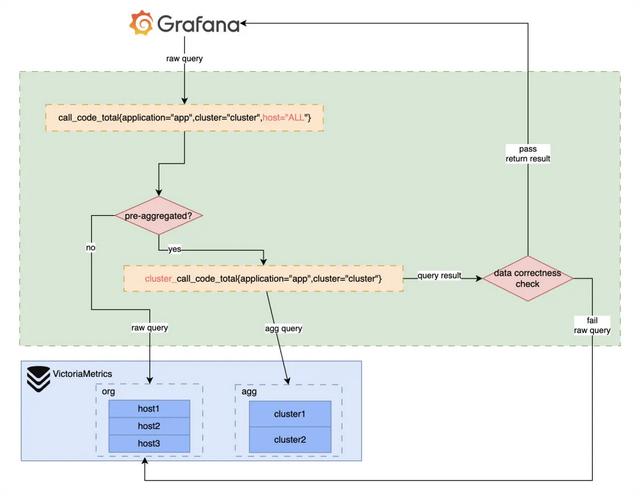
查询代理Proxy经过数据预聚合的数据需要与原始数据隔离,metric名称、label都会发生变化。
比如我们有聚合前原始数据gateway_call_code_total{application="app1",cluster="cluster1",host="host1",env="online"},按集群聚合。
按集群聚合后host这个label即丢掉,且为了隔离,表名添加前缀后变化为cluster_gateway_call_code_total{application="app1",cluster="cluster1",env="online"}。
用户若要在查询时使用聚合数据需感知聚合规则,比较不便。为解决这个问题,我们自研了查询代理Proxy,与聚合配置联动,为用户提供统一的数据查询接口,查询请求经过查询代理时直接优化修改用户的PromQL,将原始数据查询转为聚合数据查询、检测聚合数据正确性等。
Flink聚合任务数据稳定性建设
在设计我们的Flink任务Recording Rules过程中,也引入了一些新的问题,以下是一些重点问题的解决方案。
任务发布、Failover的处理
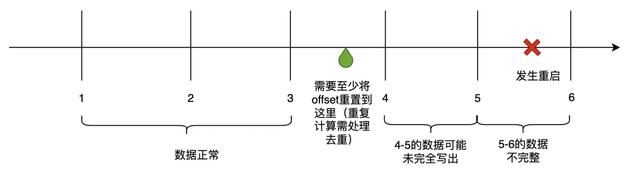
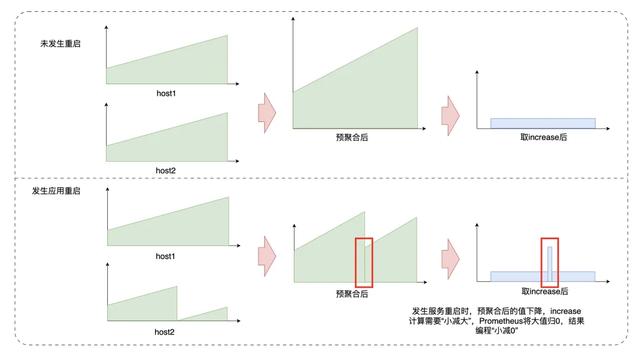
当Flink任务有需求变更、或底层资源导致的Failover,会发生任务重启,导致聚合停止。重新拉起服务时,从Kafka当前位点继续消费,无法完整拿到当前这分钟的完整数据,上一分钟的数据也可能未完全写出,故会造成数据丢失和错误。
时序监控数据的丢失、错误会直接影响到告警、问题排查,需要尽量避免。考虑到时序数据量级大,Checkpoint存储成本高、效率低,我们采用记录Kafka位点,重启时将位点向前重置、重新计算的方式。在数据处理时,定期将当前处理到的kafka timestamp offset记录下来,重启时向前推至少2个聚合间隔。offset前推引入的数据重复问题,我们借助vmstorage自带数据去重处理。
Flink任务内部序列化优化
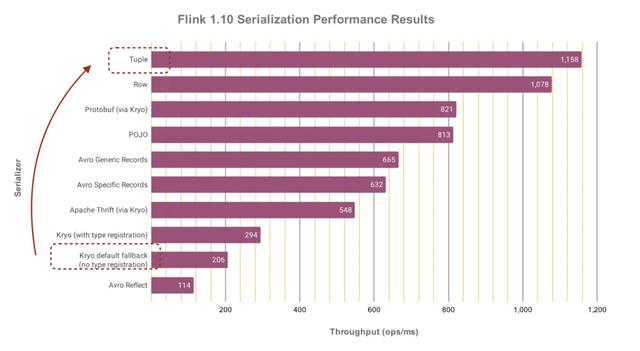
我们的聚合数据量极大,超过了250万+QPS,且对实时性要求高,若通过简单扩容去支撑该量级,需要的IT资源过高,故需要提高任务效率。通过火焰图抓取可以发现,我们的任务花费了大量开销在Function之间的序列化上,我们的数据是JavaBean,其中包含泛型的HashMap,会劣化为性能最低的Kyro序列化。我们重新抽象了数据结构,将其设计为Flink原生的Tuple类型,其中只用基本数据类型。在同样的数据源和运行环境下对比,序列化开销从54%降低为15%(下火焰图中紫色部分为序列化),在物理资源不变的基础上,任务支撑处理的输入QPS扩大数十倍。

以下是Flink官方提供的各序列化的效率对比,可知Tuple序列化对比Kryo有巨大提升。
踩坑解决:Counter数据预聚合值下降导致Increase值突刺
问题背景
采用预聚合的方案会遇到以下问题:目前我们的数据聚合主要是针对Counter做求和聚合,Counter的特点是在同一数据源上是累增的,若要获取一段时间内的值,需要用区间末尾减掉区间开始。
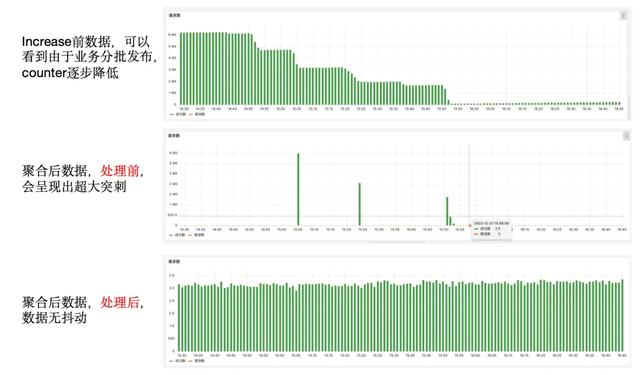
我们若按照集群聚合,第n分钟该集群发布,则会有服务的Counter被重置为0,导致整个集群的聚合值下降。若此时我们用PromQL的rate或increase函数查询发布这一分钟的值,存储层会用n分钟的值减n-1分钟的值,但此时n分钟的值大于n-1分钟的值,即小值减大值。此时存储层会认为该Counter被重置,基数应当为0,则变成n分钟的值减0,得到n分钟的值。由于集群发布前大概率已经累计了很长时间的Counter,此时n分钟的值可能非常大,会导致这一分钟的increase结果非常大,展示在图表上为一个超大的突刺。
若要在预聚合中像查询时聚合一样,在rate时对每条被聚合的原始数据一一检测counter重置,那么则需要存储每条原始数据的前值并一一检测,如此存储成本和计算成本都很高,所以我们需要其他方法来规避掉这个问题。
解决方案:通过查询代理Proxy实现聚合数据正确性检测
前文的问题背景介绍中已经介绍过,Counter的聚合数据在遇到increase查询时会发生超大的突刺,我们想到在查询时检测和屏蔽这种情况。我们自研的Proxy查询代理,本身的功能是自动解析修改业务的PromQL,将普通查询转为原始查询,我们设计在这个转换过程中检测数据正确性。

通过此方案,我们解决了该问题。
3、Metric与Trace关联分析
为关联Metric和Trace,我们设计了关联表,单独上报存储。我们从Metric关联到Trace时,先通过Metric的label、value、时间范围查出TraceId列表,随后查出对应的Trace详细信息。
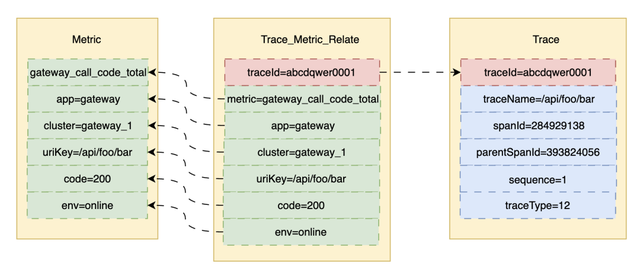
在APM平台设计上,我们将Metric数值做成了可点击的按钮,用户点击即查询出关联到的TraceId列表,进一步点击可看到详细内容。
4、高效的Metric监控可视化与图表分析能力
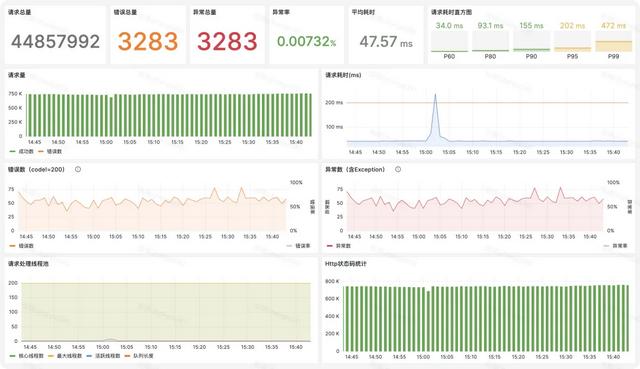
Metric可视化:我们使用Grafana来可视化Metric数据,设计了大量直观的Dashboard,维度包括应用总览,各组件如HTTP、RPC、Redis、数据库、MQ等的总览、异常、错误、请求执行的图表。如以下为某服务的请求总览Dashboard,用户可直观看到总量、P99、异常率、平均耗时、错误码、线程池等信息,非常方便。
图表分析能力:在日常故障排查中,经常需要进行时间跨度和实例之间的比较分析。我们选型的Grafana虽然对时序数据的可视化支持很好,但对图表比较分析的支持较弱。因此我们对Grafana做了二次开发,支持了以下功能:
环比分析:支持用户对监控项跨时间段比较;多实例比较:支持用户同集群内的同监控项跨实例比较,还支持按照不同的数据指标排序、查看TopK的实例等;指标分析:帮助研发一键计算曲线的数据指标,方便数据统计方面的需求。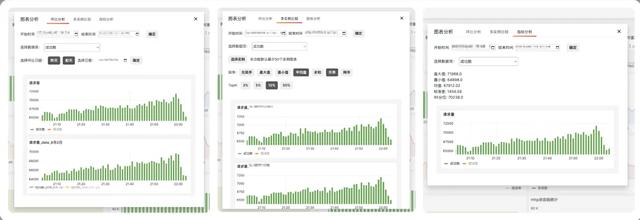
三、总结
基于VictoriaMetrics的Metric监控目前已经在云音乐各业务线全面推广,目前支撑活跃时序近7亿。其带来的优势如下:
Metric与Trace关联排障,打破信息孤岛;
应用层监控能力提升:补足应用层各维度Metric监控数据可视化,应用观测能力明显提升,可直接产出P99等指标,问题定位能力强;大规模业务低成本Grafana可视化:利用Grafana的低代码配置,省去大量开发成本;低成本解决大规模时序数据存储:基于VictoriaMetrics的存储方案成本低、性能高,经对比所占用资源仅需如M3DB等方案约三分之一。在未来我们将持续拓展监控能力,在智能分析、智能告警等方向持续深挖,为业务发展保驾护航。
作者丨张琪
来源丨公众号:网易云音乐技术团队(ID:gh_e0a72742f973)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn