
阿里妹导读
一个特殊请求引发服务器内存用量暴涨进而导致进程 OOM 的惨案。
问题背景
埋点网关是蚂蚁基于 nginx 开发的接入网关应用,作为应用接入层网关负责移动端埋点数据采集,从去年年底开始有偶现的进程 crash 问题。
好在 nginx 设计中 worker 进程闪退后 master 进程会重新拉起新的进程处理请求,埋点客户端也有重试机制,偶现闪退没有造成大的影响。
初步分析
说实话作为 C 语言应用,crash 也没什么好奇怪的 :),第一反应当然是业务代码有问题,查看机器内存的占用也没有大的起伏。

所以先排除了内存泄漏最终 OOM 导致进程闪退。大概率是内存没用好,内存越界访问导致的。这种问题排查起来也挺简单,找部分机器开启 core-dump,拿到 core 文件一看就知道是哪里跪了。说干就干,线上找了部分机器开启开关,等问题复现后登录,就遇到了第一个难题:没有生成核心转储文件。
反复检查 core-dump 开关确认已经正确打开,再回头检查了一遍最近的代码变更,也没看出什么疑点,这时候就有点一筹莫展了。
如果不是
在走迷宫时,如果发现前面无路可走,就得回头思考前面哪一步是不是走错了。
一开始排除了内存泄漏导致的 OOM 问题,是因为从监控上看内存占用水位只有 40% 不到,并没有上涨到内存用完。然而这里的监控是分钟级的,如果内存在短时间内暴涨,秒级尖刺体现到分钟级监控上很可能被平均值抹平。
再结合没有产生 core-dump 文件的现象,如果是内存耗尽导致进程被 oom-killer 进程杀死是说得通的。因为oom-killer 进程使用 SIGKILL 信号强制杀死进程,查看 Linux 信号手册,根据 POSIX.1-1990 标准,SIGKILL 信号意味着进程被强制结束并且不进行核心转储。
Signal Standard Action Comment ──────────────────────────────────────────────────────────────────────── ... SIGIOT - Core IOT trap. A synonym for SIGABRT SIGKILL P1990 Term Kill signal SIGLOST - Term File lock lost (unused) ...瞌睡遇上枕头,刚好发现监控平台上线了单机秒级监控(感谢平台工具给力),再找到发生 crash 的机器和时间点,发现推测是对的,在几秒内其中一个 worker 进程内存占用飙升,从几百 MB 一路暴涨到十几 GB,在 8C16G 规格的机器上很快就因为内存耗尽被内核杀掉。

问题查到这里,好消息是排查方向总算对了,坏消息是 OOM 进程闪退只是问题的表现,而导致内存飙升的根本原因还是没什么头绪。
怀疑有异常的攻击流量,然而查看闪退前后该机器的网络流量,inbytes 和 outbytes 并没有波动,所以也基本排除了被突发流量攻击;怀疑是网关上 ip geo 信息查询的二分查找逻辑有死循环,经过代码检查和测试也没发现这里有问题;甚至怀疑系统跑久了有内存碎片,但经过排查也排除了这种可能,今年之前也没出现这种问题。
所以目前的情况就是在没有任何外部攻击的情况下,系统内存突然就爆了。这还真是见了鬼,排查了这么多问题,如此诡异的情况也是少见。
core-dump!
core-dump 文件是进程闪退前最后的“遗照”,类似尸检之于法医,对于查问题能提供非常多线索。拿不到转储文件真是两眼一抹黑 —— 全靠猜。所以痛定思痛,决定想办法把 core-dump 文件拿到。
既然闪退是因为内存占用过高,而被 oom-killer 杀死又不会进行核心转储,总不能到 Linux 内核里修改 oom-killer 发送的信号。在跟师兄讨论时,师兄提出一个思路:在用户态实现一个 oom-killer(青春版),当然没有复杂的打分逻辑,只需要检测目标进程的内存用量,到阈值之后发送一个可以产生内核转储行为的信号来杀死进程,通过主动杀死进程的方式产生 core-dump 文件。
后面师兄抽空帮忙写了一个 nginx 辅助进程,逻辑是每秒检测一次所有 worker 进程的内存用量,如果超过一定阈值就发送 SIGABORT 信号主动杀死对应进程。当然为了防止工具误杀导致更严重的问题,限制在应用重启后的生命周期内最多只会触发一次。
找了部分机器部署之后,还真给拿到了 core-dump 文件,不过还有个小插曲,第一次拿到的文件过大发生了截断,后续又将单进程的内存阈值从 8GB 调整为 4GB,终于拿到了完整可用的 core-dump!

如上图可以看到程序的堆栈,这种通过自杀产生的内核堆栈不像内存越界的堆栈直接指向了程序崩溃点,当前的堆栈只能反应程序在异常时执行的代码,不一定是准确的问题点,但也能提供非常多的线索。从堆栈结合代码可以看出程序正在进行数据攒批写出, 再往前是 schema 埋点数据的拆分,攒批写出时恰好在调用 ngx_pcalloc 函数从内存池中申请内存,所以很可能是在 schema 埋点数据拆分之后的攒批发送时内存分配出了问题。
合理猜测
在继续分析之前插入一个我们的业务流程,大致可以分为请求接收、数据处理、数据攒批、数据发送几个阶段,为了保护埋点网关,在这些阶段分别设置了数据大小限制:
数据解压前的 body 大小限制 4MB 以内;解压后的数据限制 32MB 以内;而拆分后单条埋点大小限制根据业务类型动态调整,最大支持 2MB;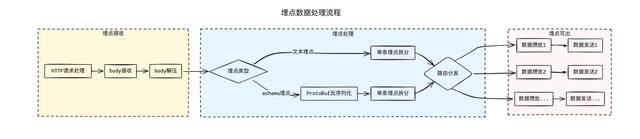
既然程序申请了这么多内存,也拿到了 core-dump,直接将内存 dump 出来看看里面都装了些什么数据,根据数据的内容可以大概推测是哪个节点申请的内存。再将之前的 core-dump 文件翻出来寻找蛛丝马迹,从内存中看到大量攒批完成准备发送的日志内容,说明很可能是数据攒批发送阶段占用了大量内存。
数据从攒批到发送阶段的内存管理使用了内存池,开始攒批时创建内存池,在攒批完成后会将数据打包为 HTTP 协议发送出去,期间会经过 ProtoBuf 序列化、压缩、生成签名等流程,最后数据写出成功后将内存池整体释放。

仔细分析这里内存相关的动作,有一个问题是内存的分配比较粗旷,因为有部分数据有单条超大埋点的需求,比如客户端闪退堆栈数据,在数据攒批阶段为了保证每次攒批至少能存放一条以上的数据,所以内存池创建时的最低大小设置为 攒批阈值 + 单条埋点最大限制 + 部分协议元数据大小,最终这个值大约是 3MB,意味着创建一个写出请求至少会申请 3MB 内存。但正常情况下数据发送相对数据流入的数量级会少很多,写出请求的创建也会随着请求流入和数据攒批打散,内存池在数据写出完成后就会释放,内存的轮转速度非常快,所以网关的内存占用并不高,仅有 30% 左右。
将目光转向内存池的释放阶段,该阶段是在 HTTP 数据发送完成并收到响应后做的,没有提前释放是因为若数据写出失败,网关需要将数据暂存到内存或磁盘中,在后续进行重试,看起来好像也没有什么地方会有发生急性内存泄漏。
但考虑极端情况,如果前面的数据攒批速度远超数据写出呢?会一瞬间创建大量写出请求,而数据发送到下游,同机房的一个 rt 大约 20ms,如果从上海跨机房调用到河源,一个 rt 就需要 40ms 了,若数据还没来得及写出完成并释放内存池,理论上有可能导致内存占用飙升。但从之前的分析看,问题机器上并没有大量数据涌入,若是单个请求过大,对于单个请求还有 4MB 的数据大小限制,怎么才能一瞬间将整个内存超过 10GB 的空间打满?
四两拨千斤
以上都是猜测,既然怀疑是这里,干脆就加监控指标发上去看看内存究竟申请了多少。上线后发现在问题机器闪退的时间点,创建写出请求的数量确实出现了一个明显尖刺,由于之前增加了进程内存限制,这里还没有涨更高就因为触发阈值被杀死。到这里问题的直接原因算是定位到了:短时间内创建了大量数据写出请求,内存池来不及释放,导致内存瞬间被打爆。

打破砂锅问到底,又是什么场景下会集中创建写出请求呢?两种可能:
有大量上报请求流入。之前也提到过,从单机的网络流量监控来看,问题时间点并没有波动,并且这台机器上的其他 worker 进程也没有问题,所以基本可以排除第一种场景。单次上报请求中携带了非常多数据。而对于单次请求,网关有设置 4MB 的原始数据限制,携带超过 4MB 的数据上报会被直接拒绝服务。难道这不到 4MB 的数据经过一系列处理和攒批,真就撬动了超 10GB 的内存消耗?从之前的内存 dump 中又发现了可疑的地方,一个用户的 uid 在内存里重复了 6 万次!再细看重复的数据,大部分字段都是相同的,仅有 timestamp、startTime、endTime 等时间戳字段不同。到这里第一时间想到的是一种攻击方式——压缩炸弹。大量重复字符,意味着更高的数据压缩率,因为不论是 LZ77 算法、哈夫曼编码还是字典编码,压缩算法的核心都是利用各种手段减少重复数据占用的存储空间。

正常线上的请求压缩率根据业务上报策略的差异平均会在 30% 左右,而如果数据大量重复,这个压缩率则会非常高。根据 dump 出来的数据,简单撸了个脚本手动构造出类似的测试数据,时间戳随机递增,其他耗时相关的字段取随机数,剩余字段用固定 mock 值。
执行结果如下,单条埋点经过 ProtoBuf 序列化后为 3.47KB,一万条埋点打包后原始数据有 34.7MB,压缩后只剩 1.2MB,压缩率达到恐怖的 3.5%,这就能解释为何前面有 4MB 的 body 大小限制但没能防住超大数据上报。
origin data bytes: 34697723compressed data bytes: 1214252真相大白
将 mock 出的原始数据裁剪到 32MB 以内再发送到埋点网关,果然复现了内存暴涨并闪退的问题。埋点网关对于文本类埋点有单次请求最多携带的埋点条数限制,而对于 ProtoBuf 类型的 schema 埋点还没有做限制。于是在生产环境先增加了对超量 schema 埋点上报的告警,发现确实存在零星携带超量埋点的请求,接着再对 schema 类型的埋点增加了条数限制后果然再没有闪退,可以确认根本原因是这里了。
但话说回来,这次上报虽然日志条数非常多,就算有重复数据的压缩率高问题,解压后最多也就 32MB 的原始数据,又是如何放大到超过 10GB 呢?
答案也在 dump 出的数据内容中,可以看到大量重复数据的埋点业务码,对应业务对数据的时效性要求非常高,所以数据攒批阈值设置得很小,每攒够 25.6KB 即会触发一次日志写出。意味着一个 32MB 原始数据的请求上来,在数据攒批发送时会瞬间创建出大约 1250 个写出请求,每个写出请求的内存池至少 3MB,就会申请出总计 3.75GB 的内存。
话又说回来,3.75GB 离 10GB 还是差很远,因为还没完,端特征埋点因为有实时消费需求,所以网关会同时写出三份数据,一份写出到 SLS,还有两份分别发送到不同的应用系统,每个写出通道都有独立的数据攒批发送流程,最终申请的内存大小就是 3.75GB * 3 = 11.25GB。
排查到这里,问题的原因链条就比较完整了:
单次请求携带大量埋点数据,因为重复字段多压缩率足够高,所以绕过了前面对请求 body 的尺寸限制;埋点网关在数据攒批发送阶段的内存池分配粗旷,默认按链路的最大阈值来分配内存,并且内存池释放依赖请求写出完成,内存释放速度远小于数据流入速度;高时效、多份写出的业务特性,更是让原本粗旷的内存管理雪上加霜,这些因素叠加在一起,最终撬动了超过 10GB 的内存消耗;话又又又说回来,以前为什么没有出现这个情况?
因为埋点网关的数据大小限制经历了几次调整,为了支持客户端闪退这类超大埋点的上报,网关分别将数据大小限制从压缩后 2MB、解压后 16MB、单条埋点 256KB 调整到了当前的压缩后 4MB、解压后 32MB、单条埋点限制支持根据业务动态调整,也就间接达成了原因链条里的第二个因素。
解决方案
之前为 schema 埋点增加了单次请求最多携带的埋点条数限制,闪退问题虽然已经解决,但排查下来可以发现闪退是各种因素叠加在一起导致的结果,这些地方都还有优化空间,对于埋点网关这种百万 QPS 的在线服务,性能和稳定性的优化非常有必要。
对于数据攒批发送,内存池很大一部分空间被原始数据占用,其实原始数据在经过 Protobuf 序列化及压缩后就不再需要了,因为 HTTP 请求发送和后续的失败缓存使用的都是压缩后数据。原始数据使用的这块内存可以提前到请求发送之前就释放,不用等待请求结束才能释放内存。而压缩之后的数据量大约只有原始数据的十分之一,大幅提升内存的轮转效率。

内存的分配其实也可以更精细,之前为每个写出请求分配了 3MB 内存,是为了支持单条超大埋点,例如客户端闪退埋点一条最大可能达到 2MB,为了保证攒批时至少能存一条埋点,并且网关的内存资源比较宽裕,这块内存池创建得很大,实际使用中大部分业务攒批都用不到这么大的内存,可以改为根据攒批数据量动态扩容。
除了这些缝缝补补,我们也在探索使用内存安全的语言比如 Rust 来实现更多能力,这里不过多展开。
小结
历时半年之久,经过反复猜测、修改、验证,终于将网关上这个“定时炸弹”成功拆除,在成功复现并定位到根因后真是长舒一口气,总结下来一点小小的心得(主要还是心理层面的,技术方面还需要一题一议,不具有普适参考价值):
坚信任何现象都有其背后的原因,在排查时苦于找不到方向,屡次道心破碎想过放弃,但线上的闪退告警时刻提醒着“革命尚未成功,同志仍需努力”。没有思路时可以拿出来和别人讨论案情,思维碰撞中往往会有灵光乍现。大胆假设,小心求证。通过现象推测可能的原因并一一验证,同时要有将之前的假设都推翻重来的勇气。
评论列表