TSFresh(基于可扩展假设检验的时间序列特征提取)是一个专门用于时间序列数据特征自动提取的框架。该框架提取的特征可直接应用于分类、回归和异常检测等机器学习任务。TSFresh通过自动化特征工程流程,显著提升了时间序列分析的效率。
自动化特征提取过程涉及处理数百个统计特征,包括均值、方差、偏度和自相关性等,并通过统计检验方法筛选出具有显著性的特征,同时剔除冗余特征。该框架支持单变量和多变量时间序列数据处理。
TSFresh工作流程TSFresh的基本工作流程包含以下步骤:首先将数据转换为特定格式,然后使用extract_features函数进行特征提取,最后可选择性地使用select_features函数进行特征选择。
TSFresh要求输入数据采用长格式(Long Format),每个时间序列必须包含唯一的id标识列。
构建示例:生成100个特征的100组时间序列观测数据import pandas as pdimport numpy as npfrom tsfresh import extract_featuresfrom tsfresh import select_featuresfrom tsfresh.utilities.dataframe_functions import imputefrom tsfresh.feature_extraction import EfficientFCParametersfrom tsfresh.feature_extraction.feature_calculators import meanfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score,ification_report, confusion_matriximport matplotlib.pyplot as pltimport seaborn as sns# 构建大规模样本数据集np.random.seed(42)n_series = 100n_timepoints = 100time_series_list = []for i in range(n_series): frequency = np.random.uniform(0.5, 2) phase = np.random.uniform(0, 2*np.pi) noise_level = np.random.uniform(0.05, 0.2) values = np.sin(frequency * np.linspace(0, 10, n_timepoints) + phase) + np.random.normal(0, noise_level, n_timepoints) df = pd.DataFrame({ 'id': i, 'time': range(n_timepoints), 'value': values }) time_series_list.append(df)time_series = pd.concat(time_series_list, ignore_index=True)print("Original time series data:")print(time_series.head())print(f"Number of time series: {n_series}")print(f"Number of timepoints per series: {n_timepoints}")
接下来对生成的数据进行可视化分析:
# 选择性可视化时间序列数据plt.figure(figsize=(12, 6))for i in range(5): # 绘制前5条时间序列 plt.plot(time_series[time_series['id'] == i]['time'], time_series[time_series['id'] == i]['value'], label=f'Series {i}')plt.title('Sample of Time Series')plt.xlabel('Time')plt.ylabel('Value')plt.legend()plt.savefig("sample_TS.png")plt.show()
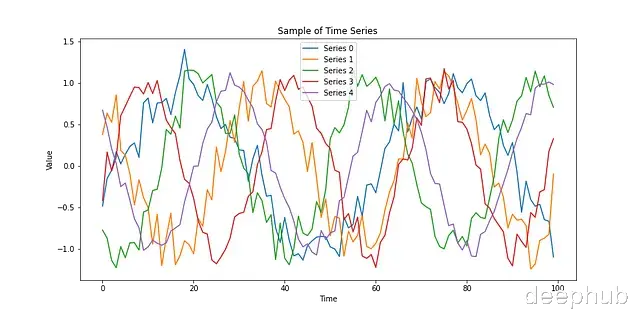
数据展现出预期的随机性特征,这与实际时间序列数据的特性相符。
特征提取过程数据呈现出典型的时间序列特征,包含噪声和波动。下面使用tsfresh.extract_features函数执行特征提取操作。
# 执行特征提取features = extract_features(time_series, column_id="id", column_sort="time", n_jobs=0)print("\nExtracted features:")print(features.head())# 对缺失值进行插补处理features_imputed = impute(features)
输出示例(部分特征):
value__mean value__variance value__autocorrelation_lag_1 id 1 0.465421 0.024392 0.856201 2 0.462104 0.023145 0.845318
特征选择为提高模型效率,需要对提取的特征进行筛选。使用select_features函数基于统计显著性进行特征选择。
# 构造目标变量(基于频率的二分类)target = pd.Series(index=range(n_series), dtype=int)target[features_imputed.index % 2 == 0] = 0 # 偶数索引分类target[features_imputed.index % 2 == 1] = 1 # 奇数索引分类# 执行特征选择selected_features = select_features(features_imputed, target)# 特征选择结果处理if selected_features.empty: print("\nNo features were selected. Using all features.") selected_features = features_imputedelse: print("\nSelected features:") print(selected_features.head())print(f"\nNumber of features: {selected_features.shape[1]}")print("\nNames of features (first 10):")print(selected_features.columns.tolist()[:10])
此过程可有效筛选出与目标变量具有显著相关性的特征。
特征应用于监督学习特征工程的主要目的是为机器学习模型提供有效的输入变量。TSFresh可与scikit-learn等主流机器学习库无缝集成。
以下展示了特征在分类任务中的应用实例:
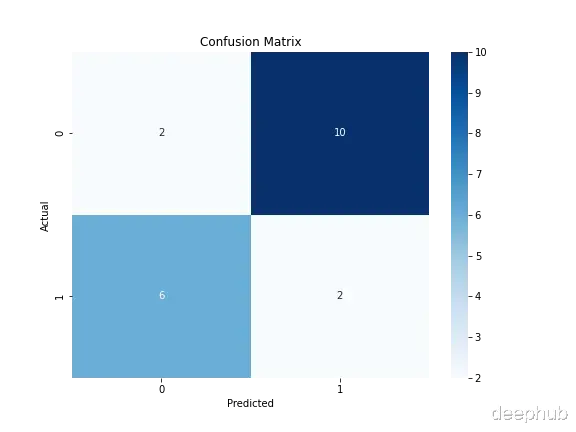
# 分类模型构建# 数据集划分X_train_clf, X_test_clf, y_train_clf, y_test_clf = train_test_split( selected_features, target, test_size=0.2, random_state=42)# 随机森林分类器训练clf = RandomForestClassifier(random_state=42)clf.fit(X_train_clf, y_train_clf)# 模型评估y_pred_clf = clf.predict(X_test_clf)print("\nClassification Model Performance:")print(f"Accuracy: {accuracy_score(y_test_clf, y_pred_clf):.2f}")print("\nClassification Report:")print(classification_report(y_test_clf, y_pred_clf))# 混淆矩阵可视化cm = confusion_matrix(y_test_clf, y_pred_clf)plt.figure(figsize=(8, 6))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')plt.title('Confusion Matrix')plt.xlabel('Predicted')plt.ylabel('Actual')plt.savefig("confusion_matrix.png")plt.show()
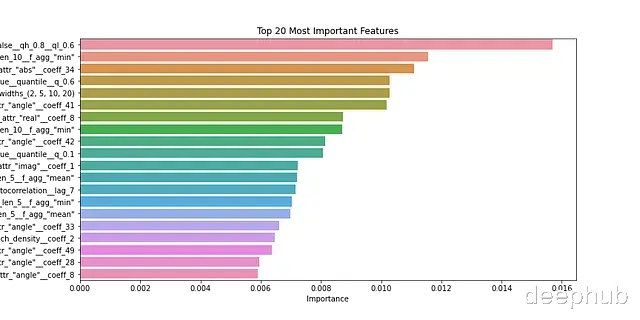
# 特征重要性分析feature_importance = pd.DataFrame({ 'feature': X_train_clf.columns, 'importance': clf.feature_importances_}).sort_values('importance', ascending=False)print("\nTop 10 Most Important Features:")print(feature_importance.head(10))# 特征重要性可视化plt.figure(figsize=(12, 6))sns.barplot(x='importance', y='feature', data=feature_importance.head(20))plt.title('Top 20 Most Important Features')plt.xlabel('Importance')plt.ylabel('Feature')plt.savefig("feature_importance.png")plt.show()
TSFresh支持对数据集中的多个变量同时进行特征提取。
# 多变量特征提取示例# 添加新的时间序列变量time_series["value2"] = time_series["value"] * 0.5 + np.random.normal(0, 0.05, len(time_series))# 对多个变量进行特征提取features_multivariate = extract_features( time_series, column_id="id", column_sort="time", default_fc_parameters=EfficientFCParameters(), n_jobs=0)print("\nMultivariate features:")print(features_multivariate.head())
自定义特征提取方法TSFresh框架允许通过tsfresh.feature_extraction.feature_calculators模块定制特征提取函数。
# 多变量特征提取实现# 构造附加时间序列变量time_series["value2"] = time_series["value"] * 0.5 + np.random.normal(0, 0.05, len(time_series))# 执行多变量特征提取features_multivariate = extract_features( time_series, column_id="id", column_sort="time", default_fc_parameters=EfficientFCParameters(), n_jobs=0)print("\nMultivariate features:")print(features_multivariate.head())
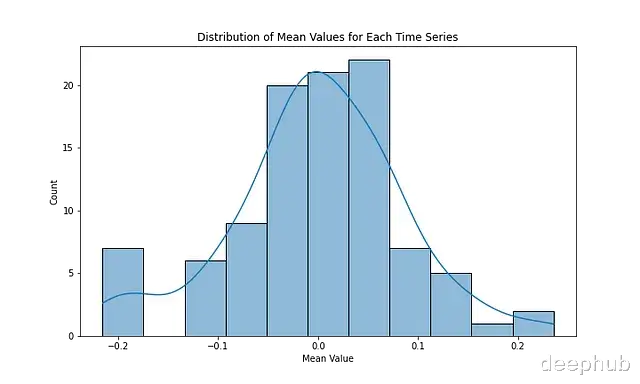
以下展示了使用matplotlib进行数据分布可视化:
# 计算时间序列均值特征custom_features = time_series.groupby("id")["value"].apply(mean)print("\nCustom features (mean of each time series, first 5):")print(custom_features.head())# 特征分布可视化plt.figure(figsize=(10, 6))sns.histplot(custom_features, kde=True)plt.title('Distribution of Mean Values for Each Time Series')plt.xlabel('Mean Value')plt.ylabel('Count')plt.savefig("dist_of_means_TS.png")plt.show()
# 特征与目标变量关系可视化plt.figure(figsize=(10, 6))sns.scatterplot(x=custom_features, y=target)plt.title('Relationship between Mean Values and Target')plt.xlabel('Mean Value')plt.ylabel('Target')plt.savefig("means_v_target_TS.png")plt.show()

TSFresh在时间序列特征工程领域展现出显著优势。通过自动化特征生成机制,它为下游机器学习任务提供了丰富的特征输入。但是需要注意的是,大量自动生成的特征可能导致过拟合问题,这一方面仍需进一步的实证研究验证。
https://avoid.overfit.cn/post/5730b6960bca45f9b89ce5393afb7005
作者:Kyle Jones