2024年2月16日,谷歌高调发布新一代多模态大模型Gemini Pro 1.5,谷歌称之为业界最强多模态模型,能生成长达1小时的视频、11小时的音频、超过3万行代码或超过70万字的代码库,在性能上全面超越OpenAI的GPT-4 Turbo,Gemini Pro 1.5是谷歌寄以厚望的AI时代翻身作品。

但是这边期待的热搜还没开始就凉了。因为它遇到了一个现象级的对手,OpenAI,后者当天也在社交平台X发布了其全新文生视频AI模型Sora,并且附上了其生成的视频样本,其效果吊打Gemini 1.5,瞬间火爆全球,持续霸榜全球科技圈舆论热搜,OpenAI表示:“扩展像 Sora 这样的视频生成模型“在构建物理世界的通用模拟器方面很有前途。”

风头被抢,干脆掀桌子,开干!
2024年2月21日,谷歌毫无预兆地发布了开源模型Gemma,该模型基于与Gemini模型相同的原理,但Gemini模型设计用于输入和输出音频数据、视觉数据和文本,而Gemma模型仅支持文本,Gemma也主打轻量级、高性能,有20亿、70亿两种参数规模,能在笔记本电脑、台式机、物联网设备、移动设备和云端等不同平台运。Gemini还支持多种语言,而Gemma模型一开始只提供英文版本。

让谷歌这么焦虑Sora到底是啥?它采用了什么技术?它有什么优势?为什么它可以成功?业界的各位大牛对此如何评价?我们职场人又该如何应对?
本期,我们将一一与您分享。
一、Sora是什么意思?
Sora取自日文的罗马音,意思是“天空”中的“空”的意思,在2023年2月份GPT在X上发布过一条日本的推文

有网友指出“空色デイズ”指的是《天元突破》的片头“”,天元突破的含义“天与次元全都突破”。Sora就是代表openai想要(/已经)突破天空(宇宙)的意思。而OpenAI的联合创始人兼首席科学官伊尔亚·苏茨克维(Ilya Sutskever)在2022年就提出了类似的观点。

而在Sora的首页介绍中,无数个自由飞翔、自主探索的纸飞机也代表着类似的寓意。

二、Sora采用了什么技术,有什么优势?
根据OpenAI官方公布的技术报告,我们能初步的了解到Sora模型的实现原理。
Sora模型主要基于深度学习中的扩散型变换器(diffusion transformer)架构,也就是,Sora是一个扩散模型,同时采用了Tranformer架构。这种架构能够将随机噪声逐渐转化为有意义的图像或视频内容。Sora模型通过训练,学会了理解和处理文本提示,将用户的描述转化为视频内容。

大白话来说,Sora就是:翻译器+搜索引擎+内容制作(概率)
具体来说,Sora模型首先接受用户的文本描述作为输入,然后利用扩散型变换器生成一系列潜在表示(latent representations),这些潜在表示逐渐接近于真实的视频数据。在这个过程中,Sora模型通过不断地迭代和优化,逐渐生成出与文本描述相符合的视频内容。此外,Sora模型还采用了一种称为“时空区块”(spacetime patches)的表示方法。这种方法将视频数据分解为一系列时空区块,每个区块都包含了一段时间和空间上的信息。通过对这些时空区块进行训练和优化,Sora模型能够生成具有连贯性和一致性的视频内容。
同时,Sora模型还利用了一种称为“视频压缩网络”(video compression network)的技术。这种技术能够将高维度的视频数据压缩为低维度的潜在表示,从而降低了计算复杂度和存储成本。在训练过程中,Sora模型在压缩的潜在空间上进行训练,并随后生成视频。同时,还训练了一个相应的解码器模型,将生成的潜在表示映射回像素空间,从而得到最终的视频输出。

OpenAI官方技术报告地址:
https://openai.com/research/video-generation-models-as-world-simulators
拓展:目前AI文生视频主要有三条技术路线,一条是生成式对抗网络,但是由于模式坍塌等问题,现在应用已不多,第二条是基于Tranformer模型,它的模型稳定性和生成图像的质量方面较为优秀,第三条是Diffusion扩散模型,因为其结果的准确性、训练的稳定性而成为目前文生视频领域的主流模型。Sora则是集后两条之大成者。
Sora有什么优势?
Sora模型相比于其他类似的视频生成模型,具有以下几个显著的优势:(1)生成视频时长更长:Sora模型能够生成长达1分钟的视频,而其他主流工具生成的视频通常只有5秒钟左右。这使得Sora模型在视频生成方面具有更强的实用性和应用价值。(2)视频质量和连贯性更高:Sora模型生成的视频不仅时长更长,而且在景物清晰度和动作连贯性方面也更优。Sora模型采用的技术和算法使得它能够更好地理解和处理文本描述,从而生成更加符合描述的视频内容。(3)支持多镜头一致性:Sora模型可以生成具有多镜头一致性的视频,即在不同镜头之间保持动作和画面的连贯性和一致性。这种功能在视频制作中非常重要,可以大大提高视频的观感和质量。
三、Sora为什么可以取得成功?
(一)、超顶尖的人才和堪称996的高强度全情投入。
OpenAI的最核心团队由13人组成,牵头人是2位应届生博士(Tim Brooks和William(Bill) Peebles,二位大神均是2023年毕业于伯克利大学人工智能研究所毕业生,导师都是顶级教授Alyosha Efros),还有3名华人。

Bill Peebles(威廉·皮布尔斯)是OpenAI 的研究科学家

在读博之前,曾在麻省理工学院攻读计算机科学与工程理学学士学位(2015-2019),在校期间共发表论文14篇,专利1篇。他和华人学者谢赛宁(现在的NYU华人教授)一起合著的一篇论文《Scalable diffusion models with transformers》,该论文首次将Transformer与扩散模型结合到了一起,被认为是Sora背后的重要技术基础之一,但是这篇论文曾因为“缺乏创新”,被CVPR(国际计算机视觉与模式识别会议)2023拒绝。2021-2022期间曾在FAIR、Adobe研究院担任研究实习生,还在NVIDIA进行了短期的实习。
而另一名重要的成员Tim brooks ,也是OpenAI的研究科学家,专门研究大规模模拟物理世界的生成模型,也是DALL·E 3的主要研究员。

Tim brooks在读博期间,发明了具有革命性意义的InstructPix2Pix技术,这是一种无需微调新的快速图像编辑方法,使得可以通过语言指导快速编辑图像。Tim Brooks在加入Open AI之前还曾在谷歌工作,参与Pixel手机相机的在AI研究和应用方向的研发,也在NVIDIA从事视频生成模型的研究,早期还在FaceBook有过实习经验。恩,都是大厂,而且都没待多久,天才何须在意简历那点3年稳定性履历?

值得一提的是,Tim brooks还是一名出色的摄影爱好者,其
作品还获得过“国家地理”等颁发的大奖。

除了有顶级的天才,Sora的工作强度也是堪称996,而大家目标非常明确,全情投入。
DiT 论文作者之一的谢赛宁在辟谣自己是Sora作者的时候,也提到了Bill Peebles在研发Sora的强度。

而OpenAI 研究人员 Jason Wei也在社交平台晒出了自己的工作日常时间表,也引起了大家的热议。

和我们“卷”是为了给领导看不一样,这群工程师的“卷”,是发自内心的对技术改变世界的热爱和坚定。
(二)、强大的技术背景支持和开源Ai社区多年的探索积累。
Sora模型由OpenAI开发,OpenAI在人工智能领域具有深厚的积累和丰富的经验,GPT的成功使得Sora在文本理解上具有巨大的优势。开源AI社区多年的探索沉淀。从OpenAI的报告中可以看到参考的文献清单达32篇,涉及计算机视觉、自然语言处理的技术进展,均来自自谷歌,Meta,微软,斯坦福、MIT、UC 伯克利、Runway等全球知名科研机构的研究成果。

比如序号3的论文是:Ha, David, and Jürgen Schmidhuber. "World models." arXiv preprint arXiv:1803.10122 (2018).

这是谷歌大脑、NNAISENSE和Swiss AI Lab在2018年联合推出的旨在为强化学习环境建立生成神经网络模型的论文,世界模型可以在无监督的情况下得到快速的训练。在这个模型理论里面,系统能够通过使用从世界模型中提取的特征作为代理的输入,且能够训练出非常紧凑和简单的策略,从而解决所需的任务,甚至一定程度上可以完全在由世界模型生成的幻梦中训练代理,并将该策略移植回到实际的环境中。
(三)、算力加持,大力出奇迹。
Sora 并没有创造新的技术,而是依然遵循OpenAI的Scaling Law(大模型公认的定律,模型能力随着模型参数的指数级增长而增强,大量的参数(至少亿级)的模型将涌现出优秀推理能力),其技术本质上和其它区别不大,很大程度是算力“大力出奇迹”的效果。在OpenAI的报告中写道:我们发现,当大规模地进行训练时,视频模型展现出许多有趣的涌现能力。这些能力使得Sora能够模拟现实世界中人类、动物和环境的某些方面。这些属性并没有任何针对3D、物体等的明确归纳偏见——它们纯粹是规模效应的现象。OpenAI至今都没有并未给出Sora训练的算力数据。但是我们可以根据NVIDIA官方曾经发布的信息来一窥究竟,在GPT训练底层模型阶段,训练一次1750亿参数的GPT-3需要34天、使用1024张A100 GPU芯片,训练成本在千万美元,而为了维持日常推理,OpenAI至少需要3.24万张A100,成本更是高昂。Sora对算力的要求应该至少不低于这个数据。为了技术的持续进步和优势领先,OpenAI对于算力的追求无止境,创始人兼CEO奥特曼,之前透露预计融资7万亿美元,用来提高全球芯片制造能力(实际上主要目的还是为了提升算力)。7万亿美金的话,按照当下的市值可以把苹果、微软、谷歌都收了,然后今日,他把7万亿的目标上调了一下,到8万亿,马斯克都忍住不互动了下

四、业界大牛如何看待Sora
(一)埃隆·马斯克:我们早就掌握这一技术。
Sora发布后当天,老马第一时间进行了回应人类要“GG”了。
也就是“Good Games的缩写,表示“打得好,我认输”。

随后的17号,马斯克在X上发布了一篇帖子,称特斯拉在一年前就掌握了类似的视频生成技术,“这些系统生成的视频并不是很有趣,因为训练数据来自特斯拉的汽车。它看起来像特斯拉的一个普通视频,事实上它是动态生成的世界。

2月19日,马斯克更是在和网友互动特斯拉是否会做一款电子游戏的时候直接表态特斯拉的“真实世界模拟和视频生成是世界上最好的“

老马还是老马,绝对的自信中带点傲娇。
(二)Yann LeCun(杨立昆):Sora不能理解物理世界,死路一条。
Yann LeCun(杨立昆),法国人,图灵奖获得者,卷积神经网络(CNN)发明人,被业内誉为“深度学习之父”之一,目前也担任Meta(META)公司的首席人工智能科学家,他对于Sora目前的生成式模型来达成“世界模型”的目标并不看好,认为其不能有效理解物理世界。
在Sora团队放出了一个指令为「蚂蚁巢穴内爬行的POV镜头」的生成式视频后,虽然一看很惊艳,但是细看却发现蚂蚁只有4条腿。
LeCun对此也在社交平台上吐槽表示:“嗨,Aditya,蚂蚁有6条腿,不是吗?”

有趣的是,经常在X等平台上就学术问题和LeCun有激烈争执的马库斯(纽约大学荣誉退休教授,著名的人工智能研究者和认知学家)在这个问题上罕见和LeCun达成共识。“如果你只看一秒钟(的视频片段),你会觉得它太神奇了。但如果你仔细看看,就会发现(这个人工智能系统)仍然不太懂常识。”
LeCun认为,认为根据提示词生成看似真实的视频,绝不代表系统真的理解物理世界。
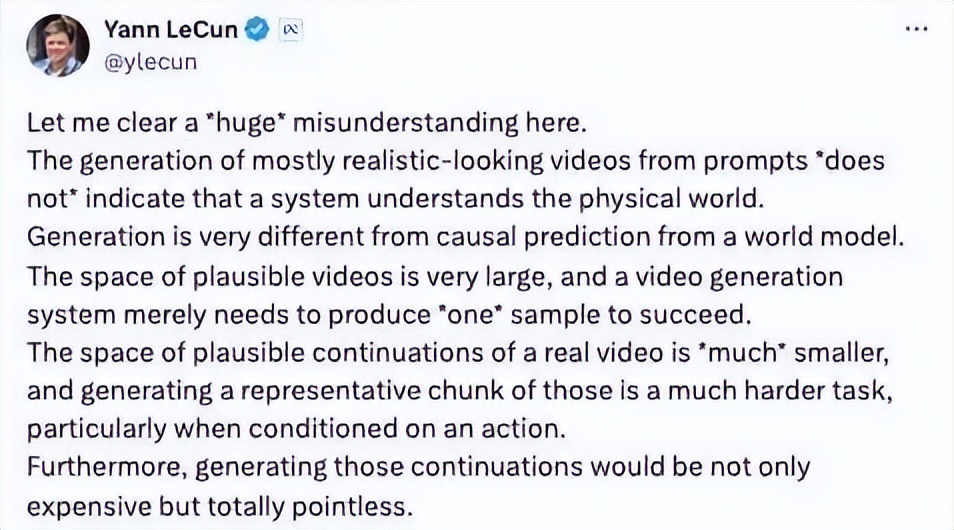
LeCun 认为Sora主要被视为文本和视频到视频模型,然而OpenAI的研究目标实际上是构建一个世界模拟器。Sora并不符合这一目标。LeCun更指出,通过生成像素来模拟行动是“非常浪费资源的,而且注定会失败”。

LeCun认为,对于感官输入的生成模型,可以适用于文本,因为文本内容属于离散且数量有限的符号,预测过程中的不确定性相对容易处理。而视频,对于感官输入则产生了更高层次的复杂性,对高维连续感官输入中的不确定性进行预测会变得非常困难。他表示:“如果你的目标是训练一个用于识别或规划的世界模型,使用像素级的预测是一个糟糕的想法。”
当然,作为AI大神,人家不是杠精,LeCun也提出了自己对于实现“世界模型”的技术解决方案: JEPA(Joint Embedding Predictive Architecture,联合嵌入预测架构)。

LeCun认为,人类对于周边世界的理解和知识的掌握大多来自观察,而非耗费数小时的指导或者阅读上千本学术著作(他曾经也举了一个例子,一个从没有开过车的青少年可以在 20 小时之内学会驾驶,但最好的自动驾驶系统却需要数百万或数十亿的标记数据,或在虚拟环境中进行数百万次强化学习试验。即使费这么大力,它们也无法获得像人类一样可靠的驾驶能力),让机器智能像人类般学习、建立起周遭世界的内部模型,从而高效学习、适应并制定计划以完成种种复杂的任务。
这就是它提出的技术架构的核心理念:并不是在“生成”,而是在更广泛的空间中进行预测。比如开发Video Joint Embedding Predictive Architecture(V-JEPA)模型,可以专注于预测复杂的相互作用,并通过向视频中添加隐藏部分来传达对象和相互作用的动态给人工智能,这是作为不依赖生成方法的世界模型的一步。

吃个瓜,现在Meta 已经将 V-JEPA 代码开源,供用户下载使用。而 Sora 仍然没有向普通用户开放,OpenAI在GPT-3只有“越来越抠”了,都要变成“CloseAI”了。
(三)François Cholle:只让 AI 看视频学不成世界模型。
François Cholle,是深度学习框架Keras的发明人,目前是谷歌人工智能研究员,François Cholle出版了许多很有价值的机器学习教材,并经常在 X平台上发表对人工智能领域的见解

他认为仅仅通过让 AI 观看视频是无法完全学习到世界模型,仅仅依靠拟合大量数据(例如通过游戏引擎生成的图像或视频)来期待构建出能广泛适用于现实世界所有情况的模型是不现实的。原因在于,现实世界的复杂度和多样性远远超出了任何模型通过有限数据所能学习到的范围。

以Sora发布的“海盗船在咖啡杯中缠斗”为例子

François Cholle提出模型能否准确反映水的行为等物理现象,或者仅仅是创造了一种幻想拼贴。他认为模型目前更倾向于后者,即依赖于数据插值和潜空间拼贴来生成图像,而不是真实的物理模拟。有人将这种行为类比为人类做梦,认为 Sora 其实只是达到了人类做梦的水平,但是逻辑能力依然不行。
额外思考:目前Sora的成功离不开基于超大规模的数据训练,按照目前的消耗进度,人力已知公开的数据终究会在不久的将来会被挖掘完毕,按照现有的技术线路,当训练的数据触达天花板的时候,它又能达到什么样的高度?这也是值得我们思考的。
五、面对Sora的冲击,我们职场人如何应对?
尽管Sora目前还存在着很多不足,但是不可否认的是,它已经是技术的巨大进步,人工智能开始去理解物理世界的逻辑和彼此的联系,并且在一些场合可以生成人类能认同的产品。而与此同时,很多行业从业者开始思考,自己所在的岗位会不会被Sora为代表性的技术所取代,很多人开始焦虑,比如好莱坞。

从目前来看,受到Sora冲击的最直接的是: 影视行业、策划和广告行业、内容创作行业、电商行业,紧接着是教育行业。在GPT-4发布后,市面上已经有公司开始做出尝试:裁掉一部分基础程序员,然后把5-8年经验的程序员培训成GPT教练,用于审核调整GPT生成的代码。而Sora的出现,也将会进一步加速很多公司在人员调整的步伐。

去年的裁员潮流,不仅仅发生在国内,连硅谷许多大科技公司也开始,这是典型的“腾笼换鸟”动作。在不具备增长前景的业务线进行战略收缩,或者用AI取代基础人力,尽可能薪酬包空间用于投入AI新兴领域的探索。
对于平时习惯借助公域市场获取信息来完成工作,对于偏重复性低耗脑的工作,对于工作8年和工作3年在技术水平要求差别不大的工作,所在行业可以自动化替代性强的工作,都有可能在未来5年被AI取代。不是在贩卖焦虑,资本永远是理性且冷血的,当AI成本低于人力成本的时候,老板抛弃你的速度会大于你电脑关机的速度。

我们应该怎么办?
老祖宗提的观点可以参考:“技多不压身”。
以Sora为代表,预计还会出现更多与AI视频生成、医疗数据处理和用户体验优化相关的工作机会,可能会催生出医疗可视化设计师、AI伦理和合规专家、医疗培训和教育顾问、研究和发展(R&D)人员、远程医疗顾问、数据科学家和分析师等新职位。这些新兴职位将要求跨学科的知识和技能,包括医学、计算机科学、数据分析、用户体验设计和伦理法律知识等。这些都是我们可以去探索的方向。
要么在一个领域扎根,足够精深,要么多元化的扩展自己。
当然,在GPT爆火后,国内的“大师”也层出不穷,纷纷利用职场人的焦虑开始割起了韭菜,要钱不要个AC脸。

相对于职场人,同样需要我们去关注的是我们还在学校的学生,对于很多学生来说,他们目前所在的专业和学习的内容远远落户于市场需求,是最容易被AI取代的。
六、在结尾的思考
(一)我们既需要反思“为什么中国没有诞生出OpenAI和Sora这样的现象级产品”的同时,也要去思考:就算我们发明了OpenAI和Sora,按照我们现有的情况,它们也能像在美国一样取得如今的成功么?
(二)我们现在已经处于技术“代差”,而这背后是整个教育体系和商业体系的代差落后,如果不改变,我们还会有机会么?承认差距不可怕,可怕的是掩盖差距。
(三)在AI时代,我们又该如何教育和引导下一代。
(四) 我们如何管控Sora可能带来的风险。
1、 版权和知识产权:Sora模型生成的视频内容可能涉及版权和知识产权问题,如未经授权使用他人的创意、图像、音乐等。为了避免这些问题,需要对模型生成的内容进行严格的版权审查和管理,确保使用的素材和创意都是合法授权的。
2、真实性和可信度:由于Sora模型生成的视频内容是自动生成的,可能存在真实性和可信度问题。为了避免这些问题,需要对模型生成的内容进行严格的审核和验证,确保其符合实际情况和用户需求。同时,也需要提高模型的生成质量和精度,减少错误和虚假内容的产生。
3、社会和伦理问题:Sora模型生成的视频内容可能涉及一些社会和伦理问题,如恶意攻击、虚假宣传、隐私泄露等。为了避免这些问题,需要制定相应的法规和伦理准则,规范模型的使用和开发行为。同时,也需要加强用户教育和管理,提高用户的意识和素质,避免滥用和误用模型。
