全文约2400字;
阅读时间:约7分钟;
听完时间:约14分钟;

在销售运营计划(S&OP)的职责中,有一项至关重要的任务是对工厂销售产品的历史数据进行细致的销售预测。这一预测过程依据不同的行业及产品特性,采取多种多样的方法。常见的预测方法包括简单平均法、加权平均法以及线性回归分析等。每种方法均有其独特之处,因此,选择时需紧密贴合自身工厂的具体情况,灵活应用。通过持续对比预测结果与实际销售数据的准确度,可以逐步摸索并确定最适合本厂的预测模型。
案例分析接下来,我们将采用一组模拟数据来详细阐述如何运用上述三种方法构建工厂产品的销售预测模型。在提供的表格中,B列向下延伸,列出了各种产品(如A、B、C等),而横向的C2至H2单元格则代表了不同的月份,依次为1月至6月;这些行列交点处的数值反映了各产品在相应月份的销售额(单位:万元)。当前任务是基于这些已有数据,预测7月的销售额。我们计划通过简单平均法、加权平均法和线性回归分析这三种策略来执行预测。
为了满足需求,我们旨在设计一套自动化的函数公式系统,旨在实现销售预测的“一键式”计算处理,从而极大地提高效率与准确性。
 简单平均法
简单平均法简单平均法是最直接的预测手段。要预测7月的销售额,可以使用如下公式,并将其填充到相应数据列的末尾:
I3 = AVERAGE(C3:H3)
该公式解释:此公式计算C3至H3单元格范围内所有数值的平均值,以此作为7月的销售预测值。
另外,若不希望手动填充每个单元格,可采用数组公式以实现批量计算:
=BYROW(C3:H7,AVERAGE)
该数组公式解释:此公式会对C3至H7范围内的每一行数据应用AVERAGE函数,自动计算出各产品从1月到6月的平均销售额,进而实现预测目的。这种方式更加高效,一次性获取多行数据的平均值。
效果如下图所示:
 加权平均法
加权平均法在进行加权平均法的公式设计前,先学习一下什么叫加权平均法。加权平均法是一种考虑了每个数据点重要性(权重)的平均值计算方式。在不同情境下,数据点的权重可能依据时间的远近、数据的可靠性或其它逻辑而有所不同。在销售预测的情境中,较近期的数据往往被认为更能反映市场趋势,因此给予较高的权重。

以1月至6月的数据为例,我们假设这些月份的顺序同时也代表了它们的权重值(即1月权重为1,2月为2,依此类推)。此时,可以利用如下公式来进行加权平均的计算:
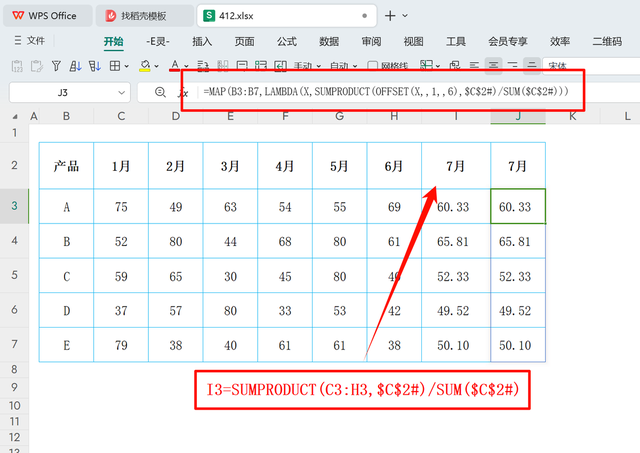
=SUMPRODUCT(C3:H3,{1,2,3,4,5,6})/SUM({1,2,3,4,5,6})
公式解释:
此公式首先通过SUMPRODUCT函数计算C3至H3单元格区间内数值与对应权重(1至6)的乘积之和,即加权求和。然后,将这个加权和除以权重的总和(1+2+3+4+5+6),以得到加权平均值。这样的计算方式确保了近期数据在预测中占有更大的比重,从而提高了预测的时效性和准确性。
同样地,我们可以采用数组公式来实现一键填充所有预测值,提高效率。以下是使用MAP函数配合LAMBDA函数实现的公式示例:
=MAP(B3:B7,LAMBDA(X,SUMPRODUCT(OFFSET(X,,1,,6),C2#)/SUM(C2#)))函数解释:
MAP函数会遍历B3至B7范围内的每一个单元格(代表各个产品),对每个单元格应用定义在LAMBDA函数中的计算逻辑。
LAMBDA(X, ...)定义了一个匿名函数,其中X代表当前遍历到的单元格(产品标识)。
OFFSET(X, 0, 1, 1, 6)根据当前的产品标识X,向右偏移一列(到达销售额数据列)并选取接下来的6个单元格(即对应1月至6月的销售额)。
SUMPRODUCT(..., {1,2,3,4,5,6}),也就是C2#中的数据,计算销售额序列与对应的权重(1至6)的乘积之和,体现了加权计算的过程。
最后,将上述加权和除以权重总和(1+2+3+4+5+6),得到每个产品基于加权平均法的7月销售额预测。
这个数组公式能够自动为列表中的每个产品计算出预测值,大大提升了处理速度和便捷性。
 线性回归分析
线性回归分析线性回归分析作为一种统计手段,专注于探究两个或多个变量之间的关联,尤其是探讨当某变量(被称作因变量,常标记为Y)受一个或多个其他变量(自变量,常用X1, X2, ..., Xn表示)变动影响的情况。其根本目的是构建一个数学模型,以描绘出自变量与因变量间的线性关联。
在电子表格环境中,预测下一期数据(如7月的销售额)可通过应用预置函数实现,例如:
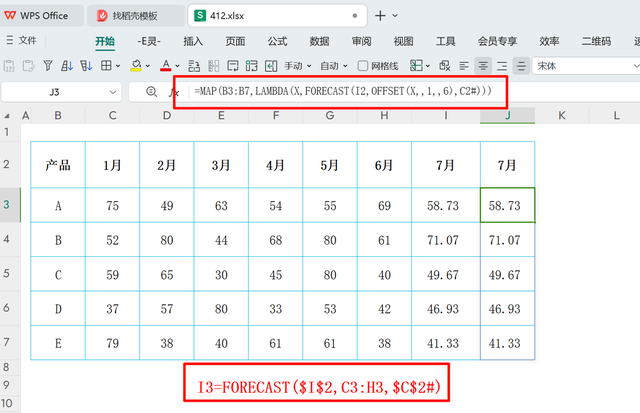
=FORECAST($I$2,C3:H3,$C$2#)
对此函数的解释如下:
FORECAST函数在此用于基于历史数据进行线性回归预测。
参数7代表我们想要预测的是第7个月(即7月)的值。
范围C3:H3包含了前六个月的销售额数据,作为输入的因变量序列。
数组{1,2,3,4,5,6}则代表了这些销售额所对应的时期序号,视为自变量序列。
简而言之,这个公式利用指定的自变量(月份序号)和因变量(历史销售额)数据,通过线性回归原理计算出第7个月份的预测销售额。
数组公式如下:
=MAP(B3:B7,LAMBDA(X,FORECAST(I2,OFFSET(X,,1,,6),C2#)))
函数解释:
MAP 函数对范围 B3:B7 中的每个元素应用一个定义好的匿名函数(由 LAMBDA 创建)。
LAMBDA(X, ...) 定义了一个简单的函数,其中 X 是从 B3:B7 中取出的当前元素。
FORECAST(I2, OFFSET(X, 0, 1, 1, 6), {1, 2, 3, 4, 5, 6}) ,也就是C2#,针对每个 X 位置执行以下操作:
OFFSET(X, 0, 1, 1, 6) 从 X 向右偏移一列(获取与 X 同行的下一个单元格开始的序列),并提取长度为6的数据序列,用作自变量。
I2 代表要预测的值所对应的因变量目标点。
{1, 2, 3, 4, 5, 6} 是时间序列或周期序号,用作自变量序列的参考框架。
整个公式对 B3:B7 每个单元格执行上述预测步骤,输出预测结果序列,分别对应每个 X 位置的未来值预测。
 最后总结:
最后总结:综上所述,通过对简单平均法、加权平均法以及线性回归分析的应用探索,我们不仅深入理解了各种预测模型的核心机制,还实践了如何在实际场景中运用Excel的强大功能来自动化销售预测流程。简单平均法提供了快速基础的预测视图;加权平均法则通过赋予不同数据点以权重,优化了预测的时效性与精确度;而线性回归分析则深入挖掘数据间的关系,为长期趋势预测奠定了坚实的统计学基础。
每种方法各有千秋,适用场景各异,但共同构建了一个多层次、立体化的销售预测体系。通过实施自动化公式系统,我们显著提高了预测工作的效率与质量,减少了人为误差,使销售运营团队能更专注于策略制定与市场响应。未来,随着数据量的增长与算法技术的进步,持续优化和定制化预测模型将成为提升企业竞争力的关键一环。最终,精准的销售预测不仅助力库存管理、生产调度的科学决策,也是驱动企业资源有效配置、实现可持续增长的重要基石。