前面介绍了Python中内置的异常类的继承体系,通常来说,这些异常类已经能够满足各种异常的场景需要。但是,有时还是需要自定义异常,来满足一些个性化的需求,以及更加可控、精细化的异常管理。
本文就来介绍一下如何通过自定义异常来满足业务的个性化需求,主要内容有:
1、为什么要自定义异常
2、如何自定义异常
为什么要自定义异常每个技术特性,没有绝对的好与坏,都有其适用的场景。所以,前面的文章中,笔者也一直在提及,学习技术特性,关键是找到实际工作中的适用场景,否则,只是单纯地记忆一些编程语言的语法,其实是没有太大意义的。
内置异常类的体系已经很丰富了,能够满足绝大部分的异常管理的场景需求。但是,自定义异常,还是有其存在的必要性的。
1、提高代码的可读性和可维护性:自定义异常可以使代码更加清晰和可读,通过自定义特定的异常类型,可以更加明确地描述不同的错误情景,从而使得代码更容易理解和维护。
2、更精确的异常管理:通过自定义异常类,可以更加精确地描述、捕获和处理特定类型的异常,从而与通用的内置异常类型区分开来,避免错误捕获不相关的异常。
3、提供更多的上下文信息:自定义异常类中可以包含更多的信息,比如自定义的错误代码、详细的错误消息、或者其他业务上下文相关的数据等,从而通过更加完整的上下文信息进行问题的定位与调试。
4、提供更好的用户体验:通过自定义异常,还可以提供更加有意义或者对用户更加友好的错误信息,而不是显示业务人员或者终端用户看不懂的技术细节或通用的错误信息。
基于以上几点,可以看出自定义异常的优点及适用场景,如果系统中更多的是通用的异常处理,没有特殊的业务领域相关的异常,则完全不需要进行自定义异常。
如何自定义异常回答了为什么要自定义异常的问题,接下来就来具体看一下,我们在Python中如何来自定义异常。
在Python中,自定义异常的通常的方法就是创建一个类,并继承自内置的异常类,通常是继承自Exception类。
直接看代码:
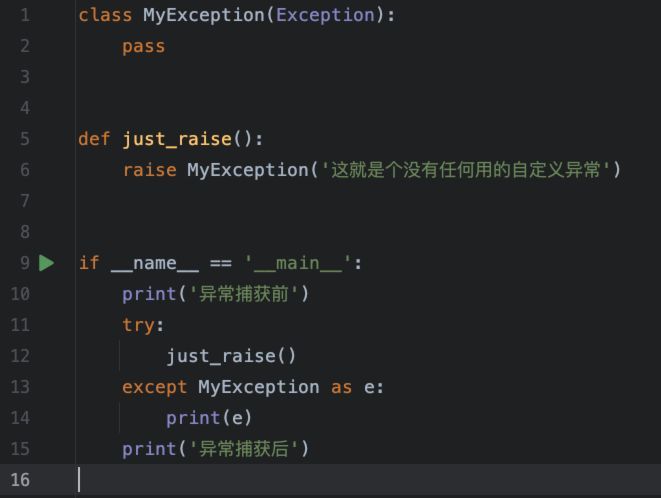
执行结果:

当然,这样一个自定义异常,是没有太大的意义的。
我们通常需要增加一些补充信息,以便于进行问题的定位及调试,比如这样的异常:
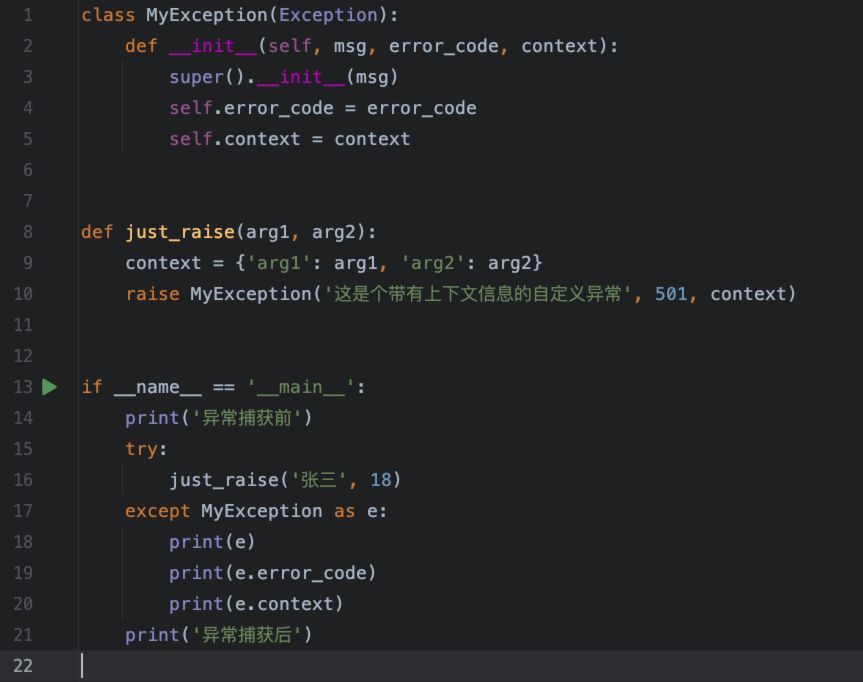
执行结果:
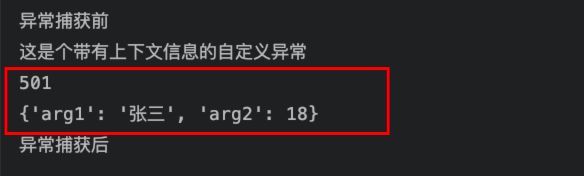
从执行结果中,我们可以看到在自定义异常中,我们可以根据需要,进行相关异常属性的扩充,从而实现更加精确的异常定位与管理。
基于上面的内容,简单总结一下自定义异常的常规做法:
1、自定义类,并继承Python内置异常类,通常是Exception,也可以是其他更加具体的内置类,比如ValueError等。
2、根据需要,在自定义的异常类中,添加需要的相关信息,比如自定义的错误代码、异常上下文环境信息等。
3、在相关的数据校验或者其他可能产生异常的代码中,添加抛出自定义异常的代码。
4、在相关的调用端代码中,添加对自定义异常的捕获、处理逻辑。
总结本文简单介绍了自定义异常的优点及适用场景,然后通过代码实例演示了在Python中自定义异常的方法,然后总结出自定义异常及使用的完整的步骤。
以上就是本文的全部内容了,感谢您的拨冗阅读,希望对您有所帮助。
