
随着人工智能技术的飞速发展,特别是大型语言模型的崛起,对算力需求呈指数级增长。这不仅推动了智算中心的建设,还为网络互联技术带来了新的挑战。
在AI大模型训练中,由于单个AI芯片的算力增长速度赶不上模型参数的膨胀,以及庞大的数据和模型结构,单个设备已无法胜任。因此,需将数据样本和模型结构分布在多个计算设备(如GPU卡)上,这就导致了设备间的通信需求激增,尤其是模型梯度的传输。为了应对这一挑战,智算中心内部的网络互联技术显得尤为重要。
在深度学习中,数据样本和模型结构被切分到多张卡或者节点上,这些卡或节点之间不仅有训练数据的通信,还有模型梯度的频繁传递。这种分布式训练方式可以提高训练速度和效率。
• 数据并行(DP):为每个计算设备(如卡或节点)分配完整模型,将数据集拆分至多个设备并行训练。在反向传播过程中,各设备上的梯度进行汇总求平均,再更新各设备上的模型参数。
模型并行分为张量并行和流水线并行。张量并行为层内并行,对模型 Transformer 层内进行分割;流水线为层间并行,对模型不同的 Transformer 层间进行分割 。
节点内互联方案
1. 私有方案 - 英伟达NVLink
NVLink是一种高速互连技术,由英伟达于2014年发布第一代。其初衷是实现GPU芯片间低延迟、高带宽的数据互联。从第一代到第二代,互联拓扑发生改变,从cube直连变为Switch交换拓扑。第三代通过增加单卡的NVLink通道数提升点到点带宽,第四代进一步完善多种协议内容,实现了C2C(Chip to Chip)、AI卡间以及服务器节点的统一连接。到了第五代,带宽大幅提升,同时支持576个GPU之间的无缝高速通信 。
以P100方案为例,其具备四对NVLink。每对NVLink为双向接口,每方向拥有八个差分(采用基于差分信号线的高速串行通信技术)。单对NVLink的带宽可达40GB/s,通过组合多个Sub-Link形成Port,能实现GPU间快速数据传输,总带宽达160GB/s。这种高带宽特性使得在处理大规模数据和复杂计算时,GPU间数据传输更高效,相较于传统PCIe方案,大幅提升系统性能。

开放技术方案 - OAM和UBB
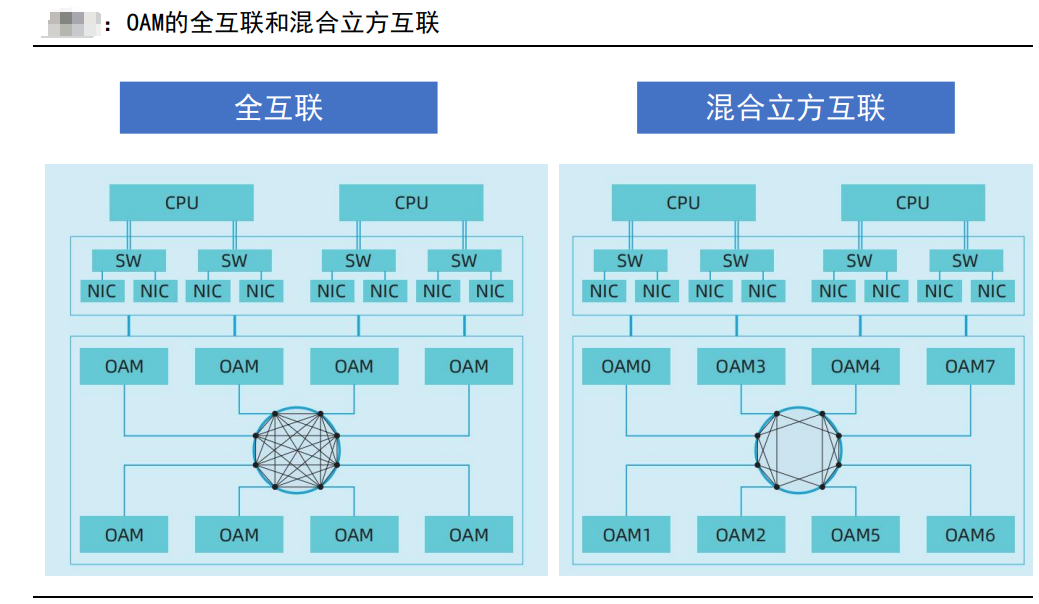
OCP组织在2019年推出了开放加速器基础设施项目(OAI),以简化整机厂家集成多家AI芯片的过程。该项目定义了业内通用的AI扣卡模组形态(OAM)和基板拓扑结构(UBB)设计规范,以8张OAM为一个整体。此外,还详细规定了8*OAM的Baseboard的主机接口、供电方式、散热方式、管理接口、卡间互联拓扑和Scale Out方式等关键要素,从而提高整个系统的性能和效率。
OAM模块在单个GPU节点上实现AI加速计算能力。通过遵循UBB v1.5 base规范的基板,实现高速互联拓扑,如7P*8FC(全互联)和6P*8HCM(混合立方互联),从而实现多OAM数据低延时共享。利用RDMA网络部署实现集群互联,最大限度地提升OAM计算性能并降低通信带宽限制。这一开放性技术方案为不同厂家的AI芯片集成提供了统一的标准和规范,有助于推动智算中心的发展和创新。
节点间互联方案
在分布式场景中,整体算力并不是随着智算节点的增长而线性增长,而是存在加速比(通常小于1,因为存在卡间通信时间)。RDMA技术是解决这一问题的关键,它可以绕过操作系统内核,直接访问另一台主机内存,从而大幅降低卡间通信时间。实现RDMA的方式有Infiniband、RoCEv1、RoCEv2、iWARP等,其中RoCEv1已经被v2替代,iWARP使用较少,目前主要采用Infiniband和RoCEv2两种方案。
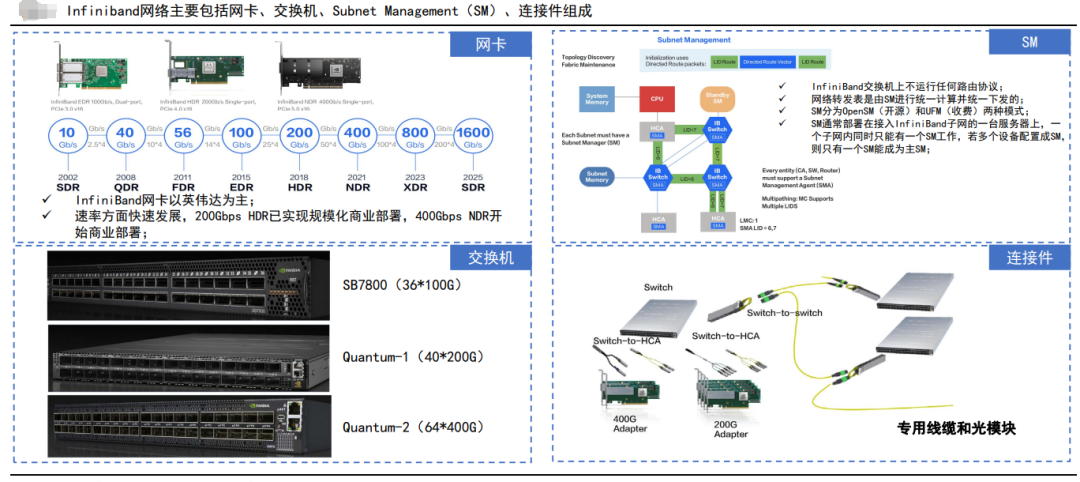
1、Infiniband网络
Infiniband网络主要由以下几个部分组成:信道适配器(Channel Adapter)、交换机、路由器、线缆和连接器。其中,信道适配器分为主机信道适配器(Host Channel Adapter)和目标信道适配器(Target Channel Adapter)。交换机原理上与其它标准网络交换机类似,但必须能满足InfiniBand的高性能和低成本的要求。
英伟达是InfiniBand网络方案和设备的主要供应商,同时还有intel、Cisco、HPE等供应商也提供相关产品。SM分为OpenSM(开源)和UFM(收费)两种模式,通常部署在接入InfiniBand子网的一台服务器上,一个子网内同时只能有一个SM工作。
Infiniband网络,基于信用信号机制,有效防止缓冲区溢出和数据包丢失。发送方在确认接收方有足够的容量接收预期数量的数据包后,才会启动数据传输。每条链路都有预设的缓冲区,发送方一次发送的数据不会超过接收方缓冲区的最大容量。接收方在完成数据转发后会清空缓冲区,并持续反馈当前可用的缓冲区大小给发送方。这种流量控制机制确保发送方不会发送过多的数据,从而避免了网络中缓冲区溢出和数据包丢失的问题。
Infiniband的Adaptive Routing基于逐包的动态路由,在超大规模组网的情况下保证网络最优利用。这种特性使得Infiniband网络能够支持大规模的智算中心集群,满足不断增长的计算需求。
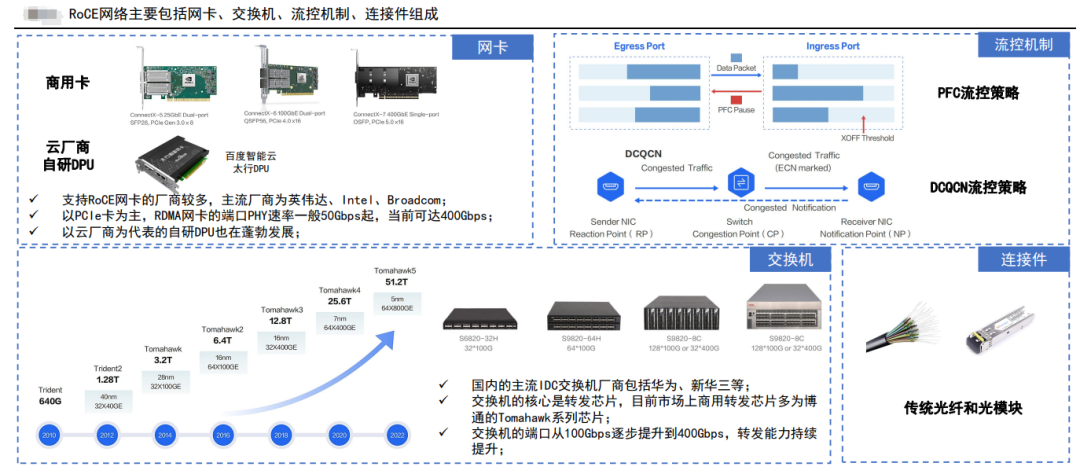
2、RoCEv2网络
RoCEv2网络是一个纯分布式的网络,由支持RoCEv2的网卡和交换机、连接件、流控机制组成。连接件使用传统光纤和光模块即可,流控机制通常使用PFC、ECN和DCQCN。新华三、华为等占据主要市场份额,英伟达ConnextX系列网卡占据主要市场份额 。
与Infiniband的对比
Infiniband和RoCEv2在集群规模方面表现出色,可支持数万甚至上千张卡,且性能基本保持稳定。
运维方面:Infiniband更成熟,包括多租户隔离能力,运维诊断能力等。
Infiniband成本更高,主要因为其交换机价格较贵。
英伟达主导InfiniBand供应商群,RoCEv2供应商亦颇具规模。


智算中心网络互联方案多样,节点内外皆具特色。各方案在不同场景发挥重要作用,为人工智能等领域的高速发展提供强大支持。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-