如下图,将下表中“年龄”一列的数据都+1,然后另存为一份新的文件“修改后的员工信息”。

图1.原始数据表
文心一言提示词打开百度“文心一言”,输入提示词:“你是pandas专家,文件路径为:D:/Samples/员工信息.xlsx。该Excel文件的第一个工作表中A-D列为给定数据。用pandas导入Excel文件的数据,引擎为"openpyxl"。在导入的数据中,将“年龄”列数据加1。输出修改后的表数据,并在同目录下另存为“修改后的员工信息”。添加代码注释。”
显示结果如下:
首先,确保你已经安装了pandas和openpyxl库。如果没有安装,你可以使用以下命令进行安装:
pip install pandas openpyxl接下来,我将提供Python代码来执行你的要求。
import pandas as pd# 定义文件路径file_path = 'D:/Samples/员工信息.xlsx'# 使用pandas的read_excel函数读取Excel文件的数据# 指定引擎为'openpyxl',并只读取第一个工作表# 假设A-D列包含我们需要的数据,并且"年龄"在C列(根据常规Excel列命名,A=1, B=2, C=3, D=4)df = pd.read_excel(file_path, engine='openpyxl', sheet_name=0, usecols='A:D')# 假设"年龄"列在DataFrame中的列名是'年龄'# 将"年龄"列的数据加1df['年龄'] = df['年龄'] + 1# 查看修改后的数据print(df)# 在同目录下另存为“修改后的员工信息.xlsx”# 使用to_excel函数,并指定索引不保存output_path = 'D:/Samples/修改后的员工信息.xlsx'df.to_excel(output_path, index=False, engine='openpyxl')# 完成操作print(f'数据已修改并保存到文件:{output_path}')请确保Excel文件中"年龄"列的名称与代码中使用的名称相匹配,否则你需要修改代码中的列名以匹配实际数据。此外,usecols='A:D'假定你只对A到D列感兴趣,并且这些列包含你需要的所有数据。如果列的顺序或名称不同,请相应地调整代码。
代码注释已经添加在相应的代码行旁边,解释了每一步的操作。在保存修改后的数据到新文件时,我们使用了index=False参数来避免将DataFrame的索引保存到Excel文件中,这通常是处理表格数据时的一个好习惯。
Python编辑器运行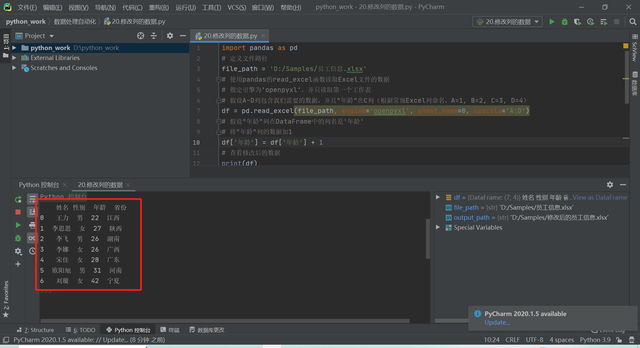
图2.Python运行结果

图3.新生成的数据文件

本合集使用的工具如下:
文心一言:3.5版本
Python编辑器:3.9.0
申明:以上结果皆为实际运行结果,如遇到无法运行可在评论区留言。部分数据来自网络,如有侵权请私信告知,感谢!