私信 ”运维笔谈”,对话回复 “阿里云k8s” 可以获取《阿里云Kubernetes项目实战手册》PDF。
这次同步数据库,我使用了mydumper这个工具,它可以并发处理,默认是4个线程,可以同时进行4张表的下载和上传操作。当然我们可以通过 -t 或者--threads 提高这个线程数(需要注意服务器的负载等情况,不要一味的增加)
-t, --threads Number of threads to use, default 4
我这个负载就很高了
但是呢,我遇到一个情况,一个库里有一张表很大,接近100G的数据量(我也是醉了[笑哭]),结果就是别的表是早早的上传好了,等这一张表上传完成就等了超过1天,实在是伤不起。
我使用的mydumper是 0.12版本,有个--chunk-filesize参数,可以把表拆分成几个文件,单位是MB
-F, --chunk-filesize Split tables into chunks of this output file size. This value is in MB所以后面的一个库,我使用了如下的方法来dump和load
mydumper -u admin -p **** -h 192.168.1.100 -B playlogdb -t 6 -o /data/20241028/dbsync --chunk-filesize=2048-t 6 我开了6个线程--chunk-filesize=2048 把大表分割成2GB一个文件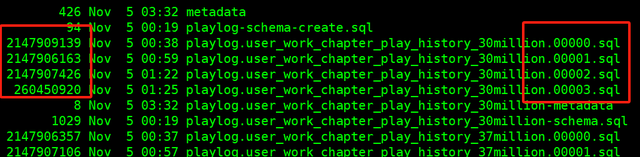
表已经按2GB大小切成了4个文件
myloader和之前的写法一样,myloader -u dba -p ***** -h 192.168.1.20 -B playlog -t 6 -d /data/20241028/play_dbsync,会自动根据切片对同一张表处理。

几个线程同时load这一张表
Mydumper的Github地址:https://github.com/mydumper/mydumper
