
阿里妹导读
本文记述了一次由 skb(socket buffer)异常导致的内核故障排查过程。
起初,没有人在意这个工单。这不过是个别机器的崩溃、一些数据包的迷失、一次服务的中断。直到这场灾难开始和每个人息息相关。
零点敲响的神秘钟声
2024年5月13日,晴。急促的钉声从破旧的 macbook 中骤然响起,在钉群混乱的信息流中,强而有力且坚持不懈的 ding 展现了它的实力,不达,一位日渐肥胖的网络工程师,大致还原了事情的全貌。
从集团升级内核版本开始,集团搜索服务就开始陷入频繁的内核故障,这些故障呈现出诡异但异常明显的规律,仅发生在午夜 0 点,然后如泥牛入海,不见其踪。而 618 的钟声即将敲响,每日 300+ 例频繁的宕机,还有进一步扩大的趋势。这时,没有丰富工作经验的同学肯定会着急忙慌的开始寻根问底, 而处理故障时长长达 2 年半的不达则会告诉你:Ding is cheap, show me the Aone.

Aone 准确的展现了一个事实,这是一个老旧难的问题,最早发生在 2023/03/23,我们的同学也尝试跟踪过多轮,未果。愁云瞬间笼罩,半吊子水平的笔者并不是这种问题的一合之敌,与其解决不了被迫丢人,不如退隐江湖。但一想到嗷嗷待哺的房贷,问题或许还有其他转机。
站在前人的肩膀上,Aone 的历史记录给我们提供了第一个证据:

不难看出,这是一个由 skb 结构体成员异常导致的内核恐慌问题,和我一样的内核小白们想必会发出同样疑惑的声音,什么是 skb?
通义千问告诉我们:
skb,又叫 sk_buff,全称是 socket buffer,它是 Linux 内核网络子系统中的核心数据结构之一,用于在网络协议栈的不同层次之间传递数据包。当数据包从网络接口卡(NIC)到达时,它被封装到一个 sk_buff 结构中,并通过网络栈向上层协议传递。同样地,当上层协议需要发送数据包时,它也会创建一个 sk_buff 结构并将其传递给下层协议进行处理。
sk_buff结构包含了数据包的所有相关信息,如数据包的头部、有效载荷、长度、标志位等。此外,它还包含了一些用于网络栈内部管理的信息,如指向下一个sk_buff 结构的指针,以及一些统计信息等。

图片出处:
https://www.minzkn.com/moniwiki/wiki.php/skbuff
让我们来稍微解释一下相关的术语,不喜欢可以跳过,这不会影响我们问题甩锅的过程。
skb->len , 报文的实际长度, 由头部长度和数据长度(payload)构成。skb->data_len, 报文的数据(payload)长度,在不同的协议层中其指向的数据并不相同,在IP层,其代表TCP/UDP数据报文长度,在TCP/UDP层,其指向的是用户态传输的数据长度。通常,不需要设置data_len,因为我们可以从len和头部长度中计算出这个结果,但若 data_len 被显式设置,代表skb是非线性skb。线性skb,指的是数据包的数据部分(即skb->data到skb->end之间的区域)是一个连续的内存块。这意味着当数据包被创建或调整大小时,整个数据部分可以在内存中作为一个整体移动或复制,没有碎片。这简化了数据包的处理,因为访问数据不需要跳转到不同的内存位置。非线性skb,指的是数据包的数据部分分布在内存中的多个不连续的块中。它适合处理大量数据或高带宽网络连接时,因为它减少了连续内存的负担,当然,它的实现通常更复杂,需要更多的内存管理和跟踪分段信息。这里的故障表明,故障发生时,skb 指向的数据报文的实际长度,小于其数据(payload)的长度。一个超集小于其子集,显然是一个内核无法处理的异常。
遇到故障不要慌,先打开 vmcore 看一看
定位 SKB
只需要一点点汇编的小常识,我们就能找到故障的 skb。


可以看到 len 是明显小于 data_len 的,这是异常的直接原因。

当我们分析多例同样问题的 vmcore 后,我们会发现一个惊人的事实, len 和 data_len 总差 4 个字节。我们知道,正常的结构体出现异常,无非就是:
内核网络栈的模块对 skb 的处理存在异常。其他模块踩踏了内存,skb 不幸受害。而这个新发现的规律给我们提供一个非常重要的结论, 异常的 skb 大概率不是其他模块踩踏了内存,而应该是在正常的操作中出现了处理异常,因为 skb 中数据的自洽性相当好(skb其他部分的内容也能说明),只是数据的描述信息似乎指向的不太正确,这帮助决定了后续的排查方向。
恢复 SKB
我们先尝试看看它指向的一个什么报文:
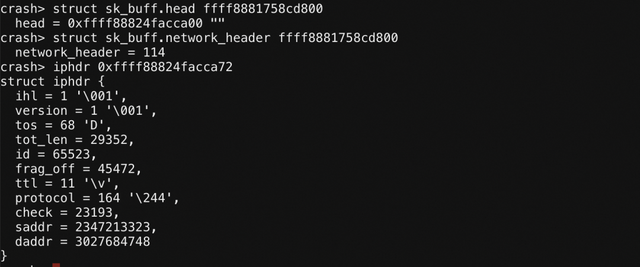
从 skb 给出的信息来看,这是一个 “IPv1” 的报文。但很可惜,没有这种东西。这说明 network_header 字段也被错误的更新了。从上一节的结论中知道,数据应该是没有被破坏的,大概率是这些描述信息被错误更新。因此,让我们回归最原始的办法,瞪眼一瞧。
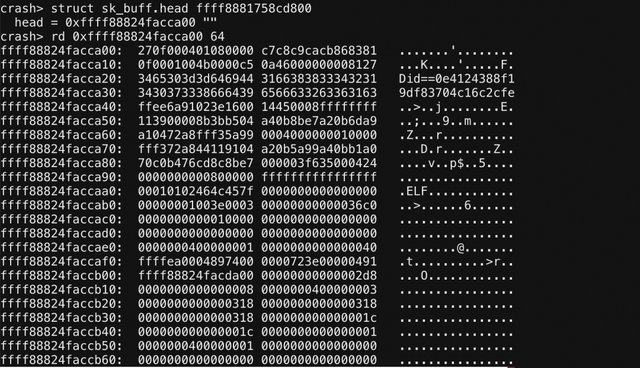
从 Aone 提供的信息来看,这是一个 IPv4 的服务。回忆计算机网络教过我们IPv4的协议格式,只要在上图中找到 4500,我们就可以找到可能是正确的IP报文了。

这个结构告诉我们,这是一个 UDP (17) 的报文,IP报文总长度(46340)为 1205, 其目的地址(1520018443) , 恰好就是搜索服务的机器。这说明我们盯出来的IP报文大概率是正确的。
那么紧跟着它的应该就是 UDP 报文:
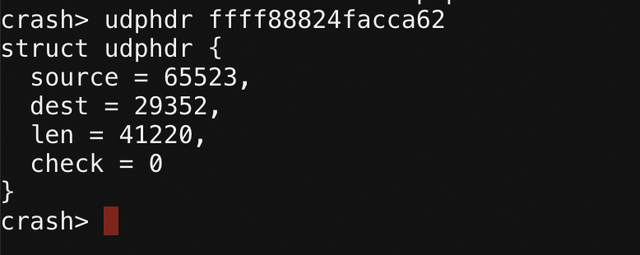
这里表明这一个从端口 62463 发向端口43122,长度 1185 的 UDP 报文,其长度恰好是 IP 报文总长度 1205 - 20 ,这再次印证了我们数据报文的猜测。
现在,我们可以找出是谁在监听端口 43122:

当我们再次分析多例同样问题的 vmcore 后,我们再次发现,触发故障的 skb 总是这个 unbound-anchor 服务。此时勤劳的 baseos 同学告诉我们:

原来如此,零点触发的秘密被解开了。因此在卸载组件后,

至此零点之谜被彻底解决......了吗?
谁杀死了内核
无论如何,应用层的任何操作都不应该导致内核的 panic,要彻底解决这个问题,我们还远远不够。
从上面的分析中,我们知道 skb 目前的 network header 指向的并不是正常的 ip 头部,但观察崩溃的异常栈,我们会发现:

观察到故障发生在 ip_local_deliver_finish 时,意味着崩溃必然发生在 IP 协议栈处理完成之后,否则异常的数据包根本无法被投递到下一层。这说明至少在IP协议层处理时,skb 一定是正常的。

因此故障基本可以被锁定在 IP层处理 和 ip_local_deliver_finish之间。内核故障的老朋友 --- netfilter ,终于粉墨登场了。接下来,我们只需找到挂载在 NF_INET_LOCAL_IN 下的钩子,就能知道到底是谁在修改 skb。

很幸运的是,当前只挂载了一个钩子。经常写 netfilter 的同学都知道,hook 是一个函数,既然符号在 vmcore 没显示出来,那么这大概率是一个内核模块,搜索内核模块的地址,我们会发现:
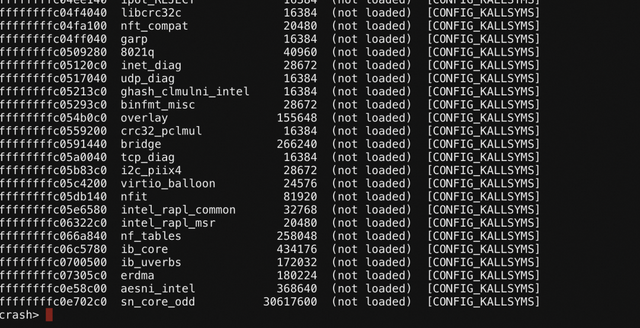
注意:这里输出的地址是内核模块地址而不是基地址,因此判断 func 是由何模块引入的需要再进一步判断。
因为地址0xffffffffc0e6b260在:
[0xffffffffc0e58c00, 0xffffffffc0e702c0]之间,这意味着这个钩子要么是由 aseni_intel 模块引入或者是由sn_core_odd模块引入。
因此我们只需要检查两个模块的 base 地址即可:

很明显0xffffffffc0e6b260在0xffffffffc0e6600之后,这意味着这个钩子是由 sn_core_odd 这个模块引入,其也正好是一个 netfilter 模块。自此,成功锁定第三方内核模块 sn_core_odd 为本次故障的真凶。
最终相关同学排查到是因为内核 5.10 中 skb_make_writable 接口发生了一些变化,此前会帮调用者将要访问的数据从frag区拷贝到线性区,而在内核 5.10 中相关逻辑被删去了,因此导致了第三方内核模块在内核 5.10 上触发了异常。
写在后面的话
第三方内核模块的治理一直是阿里云操作系统团队遇到的老大难问题。去年,网络小组还处理了一起因第三方商业网卡驱动模块踩内存导致的异常,避免了一场线上危机。作为一枚阿里云内核小白,这些问题由于代码不开放、针对性适配不足,测试不充分导致稳定性问题很多。对于内核团队,一起故障,四处求索,难,难,难!
为此,我们一直在积极推进部分网络第三方模块的 eBPF 化,降低维护成本的同时,利用 eBPF 来避免稳定性风险。另一方面也正在推进第三方内核模块的模块签名机制。相信未来,和笔者一样的内核小白们,再也不用在这种故障中艰难寻踪了。