在数字化时代,数据是企业决策和创新的基石。网络爬虫作为获取数据的重要工具,其重要性不言而喻。今天,我们将深入探讨Crawlee,一个为Node.js环境设计的先进网络爬虫和浏览器自动化库,它如何帮助开发者构建快速、可靠且易于维护的爬虫。
 Crawlee简介
Crawlee简介Crawlee是由Apify团队开发的一个开源项目,旨在提供一个强大、灵活且易于使用的网络爬虫框架。它支持JavaScript和TypeScript,使得开发者可以使用他们熟悉的语言来构建爬虫。
主要特性多语言支持:Crawlee支持JavaScript和TypeScript,提供IDE中的代码补全功能。无头浏览器集成:Crawlee建立在Puppeteer和Playwright之上,允许开发者轻松切换到无头浏览器进行数据抓取。智能代理轮换:通过智能轮换代理,Crawlee帮助开发者绕过网站的反爬虫机制。数据提取与存储:Crawlee提供了方便的数据提取和存储机制,支持将结果保存为JSON、CSV等格式。社区支持:Crawlee拥有活跃的社区,开发者可以在Discord上与其他用户交流和分享经验。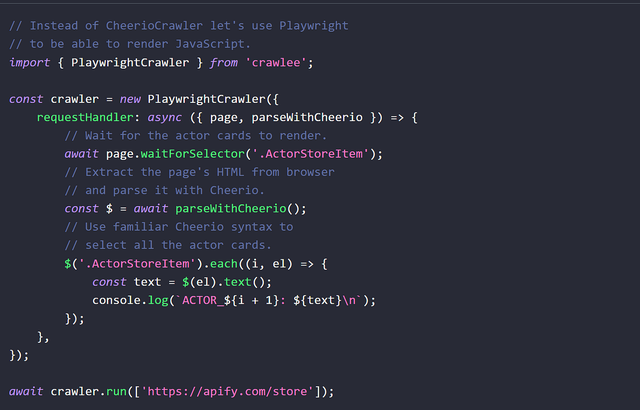 快速上手
快速上手Crawlee提供了CLI工具,使得开发者可以快速开始一个新项目。以下是使用Crawlee CLI创建新项目的步骤:
 安装Crawlee CLI:npm install -g @crawlee/cli创建新项目crawlee create my-crawler案例演示
安装Crawlee CLI:npm install -g @crawlee/cli创建新项目crawlee create my-crawler案例演示将Crawlee添加到我们现有的项目中的时候,我们需要安装Playwright。它没有与 Crawlee 捆绑在一起,因为它的体积过大。
npm install crawlee playwright示例代码
import { PlaywrightCrawler } from 'crawlee';// PlaywrightCrawler crawls the web using a headless browser controlled by the Playwright library.const crawler = new PlaywrightCrawler({ // Use the requestHandler to process each of the crawled pages. async requestHandler({ request, page, enqueueLinks, pushData, log }) { const title = await page.title(); log.info(`Title of ${request.loadedUrl} is '${title}'`); // Save results as JSON to `./storage/datasets/default` directory. await pushData({ title, url: request.loadedUrl }); // Extract links from the current page and add them to the crawling queue. await enqueueLinks(); }, // Uncomment this option to see the browser window. // headless: false, // Comment this option to scrape the full website. maxRequestsPerCrawl: 20,});// Add first URL to the queue and start the crawl.await crawler.run(['https://crawlee.dev']);// Export the whole dataset to a single file in `./result.csv`.await crawler.exportData('./result.csv');// Or work with the data directly.const data = await crawler.getData();console.table(data.items);Crawlee架构Crawlee的架构设计考虑了扩展性和灵活性,允许开发者根据自己的需求定制爬虫。以下是Crawlee的一些核心组件:
Crawler:爬虫的基类,提供了基本的爬取逻辑。Request:表示单个HTTP请求,可以包含URL、方法、头信息等。RequestList:管理爬虫将要处理的请求队列。RequestHandler:处理每个请求的逻辑,可以在这里编写数据提取和页面操作的代码。使用场景Crawlee可以应用于多种场景,包括但不限于:
市场调研:自动收集竞争对手的价格和产品信息。社交媒体分析:抓取社交媒体平台上的数据,进行情感分析或趋势研究。价格监控:监控特定商品的价格变动,及时获取价格下降的通知。数据聚合:从多个网站收集数据,构建自己的数据集。部署与扩展Crawlee可以部署在本地环境,也可以部署到云端。Apify平台提供了便捷的部署选项,允许开发者将Crawlee项目转换为Actor,享受云存储、代理和计算资源。
结语
Crawlee作为一个现代化的网络爬虫工具,为开发者提供了强大的功能和灵活性。无论您是数据科学家、开发人员还是业务分析师,Crawlee都能帮助您高效地获取和处理网络数据。值得注意的是,Crawlee除了JavaScript版本之外,还有一个python版本的,如果你熟悉python,或者习惯python代码,那么你可以选择python版本的Crawlee。