祝大家都能拿到心仪的offer
十二、谈谈悲观锁、乐观锁、可重入锁乐观锁:每次获取数据的时候,都不会担心数据被修改,所以每次获取数据的时候都不会进行加锁,但是在更新数据的时候需要判断该数据是否被别人修改过。如果数据被其他线程修改,则不进行数据更新,如果数据没有被其他线程修改,则进行数据更新。由于数据没有进行加锁,期间该数据可以被其他线程进行读写操作。例如version、cas。
悲观锁:例如for update、sync就是悲观锁。每次都会悲观的认为数据会被修改,所以每次读数据都会加锁。具体强烈的独占和排他性。给我了别人就不能用。
· 共享锁又称为读锁,简称S锁。顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
· 排他锁又称为写锁,简称X锁。顾名思义,排他锁就是不能与其他锁并存,如果一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁,但是获取排他锁的事务是可以对数据行读取和修改。
可重入锁:
简单说就是线程可以进入任何一个他拥有的锁同步着的代码块。
总结:
1、乐观锁并未真正加锁,效率高,一旦锁的粒度掌握不好,更新失败的概率会比较高,容易发生业务失败。
2、悲观锁依赖数据库锁,效率低,更新失败的概率比较低。
参考文档:https://www.jianshu.com/p/d2ac26ca6525
十三、CAS的理解1、cas比较替换,是解决多线程环境下使用锁造成性能损耗的一种机制。
2、CAS操作一般包含三个操作数,内存位置、预期原值、新值。
3、原理
(1) CAS通过调用JNI的代码实现的。JNI:Java Native Interface为JAVA本地调用,允许java调用其他语言
(2) 借助C来调用CPU底层指令实现的
(3) 当前处理器基本支持CAS,只不过不同厂家的实现不一样。
4、Unsafe类是CAS的核心类,JUC下大量使用了unsafe类,但是不建议开发者使用。
5、CAS缺点
(1) 开销大:如果并发量大的情况下,如果反复更新某个值,却一直更新不成功,会给CPU带来较大的压力。
(2) 不能保证代码块的原子性:只能保证一个变量的原子性操作,而多个方法或者代码之间原子性无法保证。
(3) ABA问题:当变量从A修改为B然后再修改为A,无法判断是否修改。CAS操作仍然成功,解决ABA加版本号。
java.util.concurrent包为了解决这个问题,提供了一个带有标记的原子引用类"AtomicStampedReference",它可以通过控制变量值的版本来保证CAS的正确性。
十四、聊一下synchronized关键字的实现原理,以及优化
1、Synchronized是Java中解决并发问题的一种最常用最简单的方法 ,他可以确保线程互斥的访问同步代码。
2、Syn修饰的对象有一下几种:
1. 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
2. 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
3. 修改一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象;
4. 修改一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象。
3、锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁、重量级锁状态,他们会随着竞争的激烈而逐渐升级。锁只可以升级不能降级,这种策略是为了提高获得锁和释放锁的效率。
4、synchronized锁存在于java对象头里面,Hotspot虚拟机对象头主要包含:mark world(标记字段)、类型指针。Mark world存储对象自身的运行时数据,如:哈希码、GC分代年龄、锁状态标志、线程持有的锁、偏向锁ID、偏向时间戳等等。
5、synchronized具有禁止代码重排序功能
参考文档:https://www.jianshu.com/p/3830e5e0a9e2
https://www.cnblogs.com/shoshana-kong/p/10877564.html
十五、谈谈JDK里面的锁(自旋锁、读写锁、可重入锁)自旋锁:
是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环。
获取锁的线程一直处于活跃状态,但是并没有执行任何有效的任务,使用这种锁会造成busy-waiting。
优点:自旋锁不会使线程状态发生切换,一直处于用户态,即线程一直都是active的;不会使线程进入阻塞状态,减少了不必要的上下文切换
缺点:当线程数不停增加时,性能下降明显,因为每个线程都需要执行,占用CPU时间。
如果线程竞争不激烈,并且保持锁的时间段。适合使用自旋锁
自旋锁不支持可重入。
阻塞锁1、阻塞锁改变了线程状态。Java环境下Thread状态有:新建状态、就绪状态、阻塞状态、死亡状态。
2、阻塞锁让线程进入阻塞状态进行等待,当获得相应的信号(唤醒、睡眠时间到)时,才可以进入就绪状态,就绪状态的所有线程,通过竞争,进入运行状态。
JAVA中,能够进入 / 退出、阻塞状态或包含阻塞锁的方法有 ,synchronized 关键字(其中的重量锁),ReentrantLock,Object.wait() / notify() ,LockSupport.park() / unpart()
3、阻塞锁的优势:不占用CPU,竞争激烈的情况下阻塞锁性能明显高于自旋锁
可重入锁1、可重入锁也交递归锁,指的是同一线程外层函数获得锁之后,内层递归函数仍然可以获取该锁。
2、“独占”,就是在同一时刻只能有一个线程获取到锁,而其它获取锁的线程只能处于同步队列中等待,只有获取锁的线程释放了锁,后继的线程才能够获取锁。“可重入”,就是支持重进入的锁,它表示该锁能够支持一个线程对资源的重复加锁。 在JAVA环境下 ReentrantLock 和synchronized 都是可重入锁。
3、Synchronized和ReentrantLock区别联系
(1) 性能区别:在Synchronized优化以前,synchronized的性能是比ReenTrantLock差很多的,但是自从Synchronized引入了偏向锁,轻量级锁(自旋锁)后,两者的性能就差不多了,在两种方法都可用的情况下,官方甚至建议使用synchronized,其实synchronized的优化我感觉就借鉴了ReenTrantLock中的CAS技术。都是试图在用户态就把加锁问题解决,避免进入内核态的线程阻塞。
(2) 原理区别:
① Synchronized: 进过编译,会在同步块的前后分别形成monitorenter和monitorexit这个两个字节码指令。在执行monitorenter指令时,首先要尝试获取对象锁。如果这个对象没被锁定,或者当前线程已经拥有了那个对象锁,把锁的计算器加1,相应的,在执行monitorexit指令时会将锁计算器就减1,当计算器为0时,锁就被释放了。如果获取对象锁失败,那当前线程就要阻塞,直到对象锁被另一个线程释放为止。
② ReentrantLock: 是java.util.concurrent包下提供的一套互斥锁,相比Synchronized,ReentrantLock类提供了一些高级功能,主要有以下3项:等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待(避免死锁)、公平锁、锁绑定多个条件。
读写锁(ReadWriteLock)1、适用于读多少写场景。
2、读写锁允许同一时刻被多个读线程访问,但是在写线程访问时,所有的读线程和其他的写线程都会被阻塞。
3、公平性选择:支持非公平性(默认)和公平的锁获取方式,吞吐量还是非公平优于公平;
4、重入性:支持重入,读锁获取后能再次获取,写锁获取之后能够再次获取写锁,同时也能够获取读锁;
5、锁降级:遵循获取写锁,获取读锁再释放写锁的次序,写锁能够降级成为读锁
6、JUC下的读写锁坑点:当持锁的是读线程时,跟随其后的是一个写线程,那么再后面来的读线程是无法获取读锁的,只有等待写线程执行完后,才能竞争。
这是jdk为了避免写线程过分饥渴,而做出的策略。但有坑点就是,如果某一读线程执行时间过长,甚至陷入死循环,后续线程会无限期挂起,严重程度堪比死锁。为避免这种情况,除了确保读线程不会有问题外,尽量用tryLock,超时我们可以做出响应。
互斥锁
1、互斥 : 就是线程A访问了一组数据,线程BCD就不能同时访问这些数据,直到A停止访问了
2、同步 : 就是ABCD这些线程要约定一个执行的协调顺序,比如D要执行,B和C必须都得做完,而B和C要开始,A必须先得做完。
3、Java中synchronized与lock是互斥锁。
悲观锁
1、假设会发生并发冲突,屏蔽一切可能违反数据完整性的操作(具有强烈的独占和排他性)
2、独占锁是一种悲观锁,synchronized就是一种独占锁,它假设最坏的情况,并且只有在确保其它线程不会造成干扰的情况下执行,会导致其它所有需要锁的线程挂起,等待持有锁的线程释放锁。
3、Mysql中用for update
乐观锁
1、不是真正的锁,而是一种实现
2、假设不会发生并发冲突,只有在提交操作时检查是否违反数据完整性,乐观锁不能解决脏读问题。
上面有讲悲观锁乐观锁,不再细讲。
十六、谈谈AQS
AQS全称AbstractQueuedSynchronizer,是java并发包中的核心类,诸如ReentrantLock,CountDownLatch等工具内部都使用了AQS去维护锁的获取与释放。
AQS内部结构
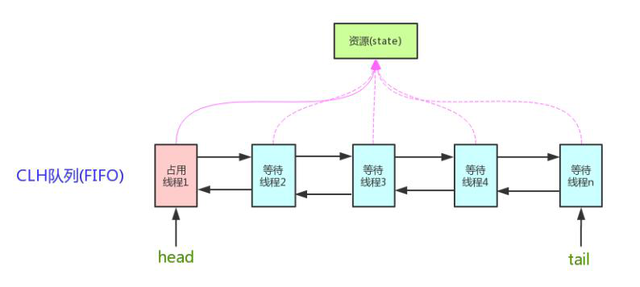
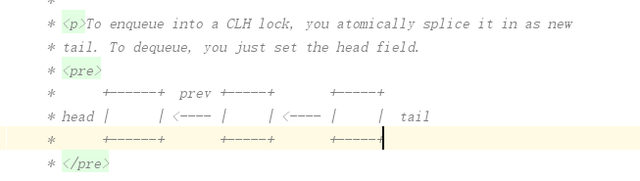
类似一个阻塞队列,当前持有锁的线程处于head,新进来的无法获取锁,则包装为一个node节点放入队尾中。
核心属性:
head:当前持有锁的线程。
tail:阻塞队列中未获取锁的线程。
state:0表示没有线程持有锁,当大于0(锁可重入每次获取锁+1)时表示有线程持有锁。
waitSatus:当大于0时表示当前线程放弃了争取锁。
prev:前一个节点
next:后一个节点
thread:所封装着的线程
内部实现采用模板模式。
下面几个方法都是钩子方法,需要子类去实现。
· tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。没有实现需要子类去实现。
· tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。没有实现需要子类去实现。
· tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。没有实现需要子类去实现。
· tryReleaseShared(int):共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回true,否则返回false。没有实现需要子类去实现。
· isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。没有实现需要子类去实现。
总结AQS内部通过一个CLH阻塞队列去维持线程的状态,并且使用LockSupport工具去实现线程的阻塞和和唤醒,同时里面大量运用了无锁的CAS算法去实现锁的获取和释放。
十七、谈谈java内存模型 JMM
JMM是java虚拟机规范定义的,用来屏蔽掉java程序在各种不同硬件和操作系统对内存访问的差异。
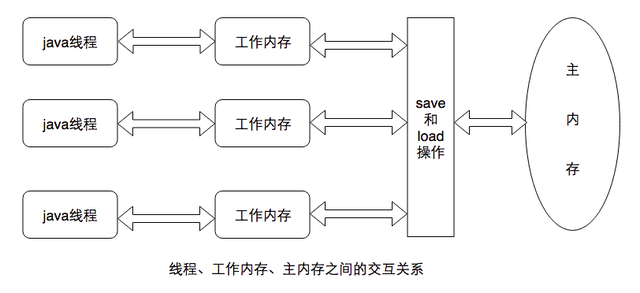
JMM内存模型
· 主内存:java虚拟机规定所有的变量(不是程序中的变量)都必须在主内存中产生,为了方便理解,可以认为是堆区。可以与前面说的物理机的主内存相比,只不过物理机的主内存是整个机器的内存,而虚拟机的主内存是虚拟机内存中的一部分。
· 工作内存:java虚拟机中每个线程都有自己的工作内存,该内存是线程私有的为了方便理解,可以认为是虚拟机栈。可以与前面说的高速缓存相比。线程的工作内存保存了线程需要的变量在主内存中的副本。虚拟机规定,线程对主内存变量的修改必须在线程的工作内存中进行,不能直接读写主内存中的变量。不同的线程之间也不能相互访问对方的工作内存。如果线程之间需要传递变量的值,必须通过主内存来作为中介进行传递。
十七、内存溢出
1、栈溢出:方法死循环递归调用(StackOverflowError),不断简历线程OutOfMemoryError。
2、堆溢出:不断创建对象,分配对象大于最大堆大小OutOfMemoryError。
3、直接内存溢出:分配内存大于JVM限制。
4、方法区溢出:
十八、JVM内存结构
内存结构分为:程序计数器、本地方法栈、虚拟机栈、方法区、堆、直接内存。
程序计数器:较小的内存空间,当前线程执行的字节码的行号指示器,不会OOM。
本地方法栈:native方法。
虚拟机栈:每个线程私有的,在执行某个方法的时候都会打包成一个栈帧,存储了局部变量表、操作数栈、动态链接、方法出口等信息。栈大小缺省1M,用-Xss设置。
方法区(1.8改为元空间metaDataSpace):包含类信息、常量、静态变量、即使编译器编译后的代码。
堆:对象存放区域。所有对象以及数组都在堆上分配,内存中最大的一块,也是GC最重要的一块区域。结构:新生代(Eden区+2个Survivor区) 老年代 永久代(HotSpot有)。
新生代:新创建的对象先放入Eden区。
GC之后,存活的对象由Eden区 Survivor区0进入Survivor区1
再次GC,存活的对象由Eden区 Survivor区1进入Survivor区0
老年代:对象如果在新生代存活了足够长的时间而没有被清理掉(即在几次Young GC后存活了下来),则会被复制到老年代。
如果新创建对象比较大(比如长字符串或大数组),新生代空间不足,则大对象会直接分配到老年代上(大对象可能触发提前GC,应少用,更应避免使用短命的大对象)。
老年代的空间一般比新生代大,能存放更多的对象,在老年代上发生的GC次数也比年轻代少。
直接内存:直接内存并不是JVM管理的内存,可以这样理解,直接内存,就是JVM以外的机器内存,比如,你有4G的内存,JVM占用了1G,则其余的3G就是直接内存;JDK中有一种基于通道(Channel)和缓冲区(Buffer)的内存分配方式,将由C语言实现的native函数库分配在直接内存中,用存储在JVM堆中的DirectByteBuffer来引用。由于直接内存收到本机器内存的限制,所以也可能出现OutOfMemoryError的异常。
参考文档:https://www.toutiao.com/i6789216144449339912/
https://blog.csdn.net/rongtaoup/article/details/89142396
十九、JAVA代码编译过程1.源码编译:通过Java源码编译器将Java代码编译成JVM字节码(.class文件)
2.类加载:通过ClassLoader及其子类来完成JVM的类加载
3.类执行:字节码被装入内存,进入JVM虚拟机,被解释器解释执行
二十、JVM垃圾收集算法与收集器
标记清除算法:第一阶段为每个对象更新标记位,检查对象是否存活,第二阶段清除阶段,对死亡的对象执行清除。
标记整理算法:
复制算法:
单线程收集器
多线程收集器
CMS收集器
G1收集器(1.8可以配置)
串行处理器:
-- 适用情况:数据量比较小(100M左右),单处理器下并且对相应时间无要求的应用。
-- 缺点:只能用于小型应用。
并行处理器:
-- 适用情况:“对吞吐量有高要求”,多CPU,对应用过响应时间无要求的中、大型应用。举例:后台处理、科学计算。
-- 缺点:垃圾收集过程中应用响应时间可能加长。
并发处理器CMS:
-- 适用情况:“对响应时间有高要求”,多CPU,对应用响应时间有较高要求的中、大型应用。举例:Web服务器/应用服务器、电信交换、集成开发环境。
二十、JVM调优怎么做
1 栈是运行时的单位 , 而堆是存储的单元。
2 栈解决程序的运行问题,即程序如何执行,或者说如何处理数据,堆解决的是数据存储的问题,即数据怎么放,放在哪儿。
调优步骤:
1、修改GC收集器,选择G1、CMS
2、打印GC信息,调整新生代、老年代参数减少GC收集频率
3、另外尽量减少老年代GC回收。
常见配置汇总
堆设置
-Xms:初始堆大小
-Xmx:最大堆大小
-XX:NewSize=n:设置年轻代大小
-XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5。
-XX:MaxPermSize=n:设置持久代大小
收集器设置
-XX:+UseSerialGC:设置串行收集器
-XX:+UseParallelGC:设置并行收集器
-XX:+UseParalledlOldGC:设置并行年老代收集器
-XX:+UseConcMarkSweepGC:设置并发收集器
垃圾回收统计信息
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:filename
并行收集器设置
-XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
-XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+N)
并发收集器设置
-XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
-XX:+ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
二十一、final、finally、finalize关键字的理解
final:用于修饰类、成员变量和成员方法。final修饰的类,不能被继承(String、StringBuilder、StringBuffer、Math,不可变类),其中所有的方法都不能被重写(这里需要注意的是不能被重写,但是可以被重载,这里很多人会弄混),所以不能同时用abstract和final修饰类(abstract修饰的类是抽象类,抽象类是用于被子类继承的,和final起相反的作用);Final修饰的方法不能被重写,但是子类可以用父类中final修饰的方法;Final修饰的成员变量是不可变的,如果成员变量是基本数据类型,初始化之后成员变量的值不能被改变,如果成员变量是引用类型,那么它只能指向初始化时指向的那个对象,不能再指向别的对象,但是对象当中的内容是允许改变的。
finally:通常和try catch搭配使用,保证不管有没有发生异常,资源都能够被释放(释放连接、关闭IO流).当try中有return时执行顺序:return语句并不是函数的最终出口,如果有finally语句,这在return之后还会执行finally(return的值会暂存在栈里面,等待finally执行后再返回).
finalize是object类中的一个方法,子类可以重写finalize()方法实现对资源的回收。垃圾回收只负责回收内存,并不负责资源的回收,资源回收要由程序员完成,Java虚拟机在垃圾回收之前会先调用垃圾对象的finalize方法用于使对象释放资源(如关闭连接、关闭文件),之后才进行垃圾回收,这个方法一般不会显示的调用,在垃圾回收时垃圾回收器会主动调用。
二十二、Java线程启动方式
1、实现Runnable接口优势:
1)适合多个相同的程序代码的线程去处理同一个资源
2)可以避免java中的单继承的限制
3)增加程序的健壮性,代码可以被多个线程共享,代码和数据独立。
2、继承Thread类优势:
1)可以将线程类抽象出来,当需要使用抽象工厂模式设计时。
2)多线程同步
3、在函数体使用优势
1)无需继承thread或者实现Runnable,缩小作用域。
4、线程池方式
5、实现callable接口允许有返回值
Future:首先,可以用isDone()方法来查询Future是否已经完成,任务完成后,可以调用get()方法来获取结果
如果不加判断直接调用get方法,此时如果线程未完成,get将阻塞,直至结果准备就绪
注:多次start线程会报错。(线程状态不对)
二十二、聊聊线程池线程池就是首先创建一些线程,它们的集合称为线程池。使用线程池可以很好地提高性能,线程池在系统启动时即创建大量空闲的线程,程序将一个任务传给线程池,线程池就会启动一条线程来执行这个任务,执行结束以后,该线程并不会死亡,而是再次返回线程池中成为空闲状态,等待执行下一个任务。
为什么使用线程池:
多线程运行时间,系统不断的启动和关闭新线程,成本非常高,会过渡消耗系统资源,以及过渡切换线程的危险,从而可能导致系统资源的崩溃。这时,线程池就是最好的选择了。池化技术举例:数据库连接池、httpClient连接池、tomcat线程池。池化技术主要就是复用资源。
ExecutorService是Java提供的用于管理线程池的类。该类的两个作用:控制线程数量和重用线程
四种线程池(不推荐使用,尽量自己创建):
Executors.newCacheThreadPool():可缓存线程池,先查看池中有没有以前建立的线程,如果有,就直接使用。如果没有,就建一个新的线程加入池中,缓存型池子通常用于执行一些生存期很短的异步型任务
Executors.newFixedThreadPool(int n):创建一个可重用固定个数的线程池,以共享的无界队列方式来运行这些线程。
Executors.newScheduledThreadPool(int n):创建一个定长线程池,支持定时及周期性任务执行。
Executors.newSingleThreadExecutor():创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
线程池参数详解:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime,
TimeUnit unit, BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory, RejectedExecutionHandler handler) {
}
corePoolSize:核心线程数。
maximumPoolSize:线程池最大线程数。
keepAliveTime: 空闲线程存活时间
unit: 时间单位
workQueue: 线程池所使用的缓冲队列
threadFactory:线程池创建线程使用的工厂
handler: 线程池对拒绝任务的处理策略
执行原理详细描述:
1、创建一个线程池,在还没有任务提交的时候,默认线程池里面是没有线程的。当然,你也可以调用prestartCoreThread方法,来预先创建一个核心线程。
2、线程池里还没有线程或者线程池里存活的线程数小于核心线程数corePoolSize时,这时对于一个新提交的任务,线程池会创建一个线程去处理提交的任务。当线程池里面存活的线程数小于等于核心线程数corePoolSize时,线程池里面的线程会一直存活着,就算空闲时间超过了keepAliveTime,线程也不会被销毁,而是一直阻塞在那里一直等待任务队列的任务来执行。
3、当线程池里面存活的线程数已经等于corePoolSize了,这是对于一个新提交的任务,会被放进任务队列workQueue排队等待执行。而之前创建的线程并不会被销毁,而是不断的去拿阻塞队列里面的任务,当任务队列为空时,线程会阻塞,直到有任务被放进任务队列,线程拿到任务后继续执行,执行完了过后会继续去拿任务。这也是为什么线程池队列要是用阻塞队列。
4、当线程池里面存活的线程数已经等于corePoolSize了,并且任务队列也满了,这里假设maximumPoolSize>corePoolSize(如果等于的话,就直接拒绝了),这时如果再来新的任务,线程池就会继续创建新的线程来处理新的任务,直到线程数达到maximumPoolSize,就不会再创建了。这些新创建的线程执行完了当前任务过后,在任务队列里面还有任务的时候也不会销毁,而是去任务队列拿任务出来执行。在当前线程数大于corePoolSize过后,线程执行完当前任务,会有一个判断当前线程是否需要销毁的逻辑:如果能从任务队列中拿到任务,那么继续执行,如果拿任务时阻塞(说明队列中没有任务),那超过keepAliveTime时间就直接返回null并且销毁当前线程,直到线程池里面的线程数等于corePoolSize之后才不会进行线程销毁。
5、如果当前的线程数达到了maximumPoolSize,并且任务队列也满了,这种情况下还有新的任务过来,那就直接采用拒绝的处理器进行处理。默认的处理器逻辑是抛出一个RejectedExecutionException异常。你也就可以指定其他的处理器,或者自定义一个拒绝处理器来实现拒绝逻辑的处理(比如讲这些任务存储起来)。
JDK提供了四种拒绝策略处理类:AbortPolicy(抛出一个异常,默认的),DiscardPolicy(直接丢弃任务),DiscardOldestPolicy(丢弃队列里最老的任务,将当前这个任务继续提交给线程池),CallerRunsPolicy(交给线程池调用所在的线程进行处理)。
执行原理简要描述:
1.核心线程是否已满 没有满则继续执行任务,如果满了,再来的请求将存储到队列里
2.队列是否已满 没有的话核心线程继续执行任务,如果满了,线程池增加线程数
3.线程池是否已满,没有的话线程池继续处理任务,如果满了,将启动拒绝策略
核心数 --> 队列 --> 线程池
如何确定线程池参数:
需要根据几个值来决定:
tasks :每秒的任务数,假设为500~1000
taskcost:每个任务花费时间,假设为0.1s
responsetime:系统允许容忍的最大响应时间,假设为1s
1、corePoolSize
(1) threadcount = tasks/(1/taskcost) =tasks*taskcout = (500~1000)*0.1 = 50~100 个线程。corePoolSize设置应该大于50。
(2) 根据8020原则,如果80%的每秒任务数小于800,那么corePoolSize设置为80即可
2、queueCapacity = (coreSizePool/taskcost)*responsetime
(1) 计算可得 queueCapacity = 80/0.1*1 = 80。意思是队列里的线程可以等待1s,超过了的需要新开线程来执行
(2) 切记不能设置为Integer.MAX_VALUE,这样队列会很大,线程数只会保持在corePoolSize大小,当任务陡增时,不能新开线程来执行,响应时间会随之陡增。
3、maxPoolSize = (max(tasks)- queueCapacity)/(1/taskcost)
计算可得 maxPoolSize = (1000-80)/10 = 92
(最大任务数-队列容量)/每个线程每秒处理能力 = 最大线程数
4、rejectedExecutionHandler:根据具体情况来决定,任务不重要可丢弃,任务重要则要利用一些缓冲机制来处理
5、keepAliveTime和allowCoreThreadTimeout采用默认通常能满足
二十三、线程状态
1.初始(NEW):新创建了一个线程对象,但还没有调用start()方法。
2.运行(RUNNABLE):Java线程中将就绪(ready)和运行中(running)两种状态笼统的称为“运行”。线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取CPU的使用权,此时处于就绪状态(ready)。就绪状态的线程在获得CPU时间片后变为运行中状态(running)。
3.阻塞(BLOCKED):表示线程阻塞于锁。
4.等待(WAITING):进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。
5.超时等待(TIMED_WAITING):该状态不同于WAITING,它可以在指定的时间后自行返回。
6.终止(TERMINATED):表示该线程已经执行完毕。