
DeepSeek 的横空出世引发了 AI 产业的深刻讨论。本文就 DeepSeek 对算力需求、芯片市场、技术创新、端侧智能、出口管制、投资逻辑、软件生态、开源生态以及中国科技资产估值等十个关键问题进行了深入分析。
问题#1:DeepSeek 是否会抑制算力增长?
据 DeepSeek V3 技术报告,V3 模型的训练总计只需要 278.8 万 GPU 小时,相当于在 2048卡的 H800GPU 集群上训练约 2 个月,合计成本约 557.6 万美金,相较而言,Llama 3 系列模型的计算预算则多达 3930 万 H100 GPU 小时,DeepSeek 训练成本约相当于 Llama 3系列模型的 7%。
我们认为,DeepSeek 对算力需求的影响呈现出短期抑制、长期增长的复杂趋势。短期内,DeepSeek 的低成本高效训练方法可能导致训练需求下降。然而,从长远来看,随着模型的普及和应用场景的扩展,推理需求将显著增长。这种趋势类似于"蒸汽机降低煤耗但提升煤炭总用量"的历史现象。
随着 AI 技术成本的下降,其应用范围将大幅扩展,最终可能导致算力需求的大幅增长。微软 CEO 纳德拉认为 AI 效率提升将激发指数级需求。

问题#2:DeepSeek 是否会改变 AI 算力的增长范式
AI 算力大致分为 1)用于研发通向通用人工智能(AGI)的前沿模型相关的探索性算力(AGI方向),2)面向一般消费者的应用性算力(现有模型推理)。过去两年,推动算力增长的主要动力是,探索性算力增速(25x/2 年)远高于摩尔定律(2 倍/年),导致 GPU 需求激增。
只要这个探索工作还在继续产生正向回报, AI 算力的增长范式短期或不会发生变化。
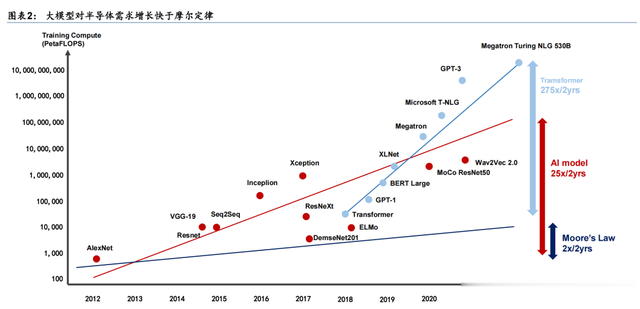
在通用人工智能(AGI)愿景的驱动下,我们看到,主要科技巨头仍然在加大投入,例如:
1)1/24, Meta 宣布计划 2025 年资本支出达 600-650 亿美元,主要用于 AI 基础设施(训练集群和数据中心建设)。
2)1/21,OpenAI 宣布和软银、Oracle 启动的“Project Stargate”计划投资超 1000 亿美元建设 AI 基础设施,显示资本仍集中流向需要海量算力的前沿探索。
根据 Factset 一致预期,微软、谷歌、亚马逊、Meta、苹果等北美五大科技公司合计资本开支 2025 年有望继续增长 19.6%。其中很大部分投入是用在包括 GPT-5、Llama4 等在内下一代模型的算力投资。另一方面,Agent 等应用目前仍处于探索的初期阶段,大规模商用的时间点仍存在不确定性,所以我们认为目前 AI 算力的增长范式没有变化。
问题#3:DeepSeek 会改变市场投资逻辑吗?
DeepSeek 这次的“惊喜”让我们认识到,
1) 未来大模型公司之间的竞争中,"算法效率"的重要性可能上升, 投资重点可能从"算力军备"转向"算法效率"。AI 竞赛正从"算力军备"转向"算法效率"。未来的竞争重点或将更多地集中在算法优化和生态活力上。
2) 开源协议能使中小开发者基于前沿模型二次开发,推动大模型创新从少数科技巨头向分布式社区转移,为中小软件企业创造更多创新机会。从投资角度,我们认为 2025 年是AI 发展进入商业化落地的一年。以 Agent AI 为代表的企业软件有望迅速落地,提升企业工作效率,带动美股软件板块表现或好于硬件。
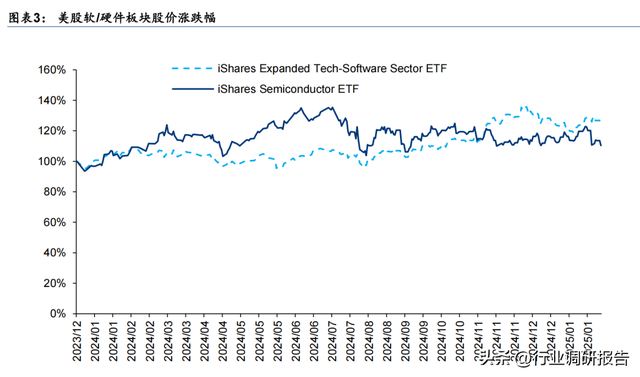

问题#4:DeepSeek 是否会改变芯片市场格局?
根据 Jon Peddie Research,3Q24 英伟达在全球 GPU 市场份额达到 90%。其中,H100等高端 GPU 是主要产品之一。DeepSeek 的成果显示,在面向一般消费者的大模型市场,企业可以通过使用 A100、H800等相对低端的芯片实现类似性能。这可能会影响英伟达 2025年以后,B200 等最先进 GPU 在云计算、主权 AI 等领域的普及Blackwell/Rubin 等最先进的 GPU 的用途,初期可能会被局限在探索下一代超大规模模型(Frontier Model)上。

问题#5:DeepSeek 真的那么便宜吗?
据 DeepSeek V3 技术报告,V3 模型的训练总计只需要 278.8 万 GPU 小时,相当于在 2048卡的 H800GPU 集群上训练约 2 个月,合计成本约 557.6 万美金,相较而言,Llama 3 系列模型的计算预算则多达 3930 万 H100 GPU 小时,DeepSeek 训练成本约相当于 Llama 3系列模型的 7%。但是,SemiAnalysis 在报告中指出,557.6 万美金这个数字主要指的是模型预训练的 GPU成本,并不包括研发、数据收集、清理等其他重要成本。实际上,DeepSeek 的总体投资规模相当可观。据 SemiAnalysis 估计,其 GPU 投资就超过 5 亿美元。考虑到服务器资本支出、运营成本等因素,DeepSeek 的总拥有成本(TCO)在 4 年内可能达到 25.73 亿美元。
DeepSeek 的成本优势主要体现在其高效的训练方法和创新的模型架构上。例如,其推理成本降至 OpenAI 的 1/50,这在实际应用中可以带来显著的成本节约。然而,这种成本优势并不意味着整体 AI 开发和运营成本的大幅降低。

问题#6:DeepSeek 到底有哪些创新?
DeepSeek 在多个方面展现出技术创新,主要包括模型架构创新、训练方法突破、蒸馏优化、推理效率提升等。其中,混合专家(MoE)架构和多头潜在注意力(MLA)的引入显著提升了模型性能和效率。R1-zero 模型采用纯强化学习(RL)训练,跳过监督微调,验证了 RL 在 AI训练中的优先级和有效性。这些创新使 DeepSeek 在性能、效率和成本方面都取得了显著进展,为 AI 技术的发展提供了新的方向。特别是在解决复杂数学、物理和推理问题时,其速度是 ChatGPT 的两倍,且在编程问题上提供了迅速而全面的答案。
1)采用混合专家(MoE)架构,动态调用子模型降低计算量;
2)引入多头潜在注意力(MLA)压缩内存,支持长文本处理;
3)强化学习(RL):R1-zero 模型跳过监督微调,通过纯 RL 直接训练,验证了 RL 的优先级和有效性;
4)蒸馏优化:利用 R1 生成数据微调小模型,提升特定场景性能(如数学、代码任务)模型架构创新、训练方法突破、蒸馏优化、推理效率提升等。

问题#7:DeepSeek 会带动中国科技资产价值重估吗?
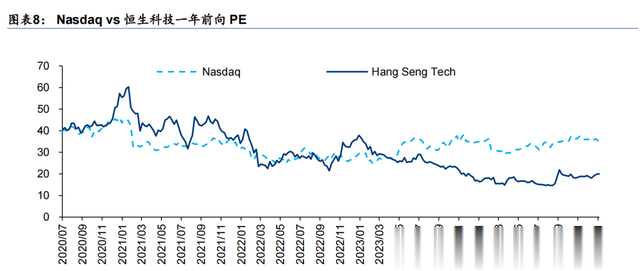
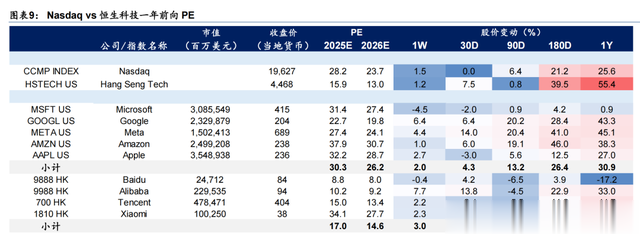
目前(2025/2/3),恒生科技指数12月前向PE 20.0倍,远低于纳斯达克的35.4倍。DeepSeek的成功可能提高投资者对中国 AI 公司产业链的估值预期,吸引更多资本投资中国 AI 领域。
问题#8:DeepSeek 会推动端侧智能发展吗?
DeepSeek 很可能会显著推动端侧智能的发展,其高性价比模型使得更多企业可能考虑在端侧设备上部署 AI 应用,推动智能设备的智能化进程。微软推出的专为 NPU 设计的DeepSeek-R1 模型,支持 Copilot+PC 等设备,实现半连续运行的主动智能体验,为智能手机、汽车等端侧设备提供了高效本地化部署方案。DeepSeek 的技术进步可能加速端侧智能的普及和发展,推动 AI 技术向更广泛的终端设备渗透,从而改变现有的计算范式和用户交互方式。这不仅提升了端侧 AI 性能,还有助于保护用户隐私,降低了 AI 应用部署的技术门槛。
但是,从 Apple Intelligence 过去一年的发展历程中,我们看到,智能硬件的迭代是循序渐进过程,不会一蹴而就。模型能力提升只是其中一环,还存在生态链协调等很多挑战,对2025 年 AI 手机等端侧智能的发展不应抱过高预期。

问题#9:DeepSeek 会导致美国提升出口管制压力吗?
DeepSeek 发布后,美国媒体进一步限制中国发展 AI 声音抬头。我们看到以下几个风险:
1)芯片出口管制收紧:美国可能会加强对高端 AI 芯片的出口管制;
2)开源限制:美国政府可能会限制科技公司开源大模型,以防止技术扩散;
3)模型回传限制:在 2024 年年底发布的出口管制政策中,美国政府已经限制在新加坡等第三国训练好的模型回传中国,阻止技术转移;
4)数据获取限制:美国可能会限制用于 AI 训练的大规模数据集的获取;
5)算力资源限制:除了芯片管制,还可能限制美国云服务提供商的高性能计算资源的使用。

问题#10:DeepSeek 会改变开源软件生态吗?
全球主要大模型公司中,OpenAI、Google、Anthropic、字节、百度等采用闭源模式,Meta、阿里等采用开源模式。如下图所示,闭源模型一直保持对开源模型的性能优势。

这次 DeepSeek 通过开源接近最先进的闭源的高性能模型,可能降低 AI 技术的使用门槛。
开源模式带来边际成本持续下降的技术红利,为 AI 技术的真正普及奠定了基础。此外,DeepSeek 的做法也可能推动其它 AI 公司重新思考其商业模式。

本文来源:华泰证券丨研究员:黄乐平、陈旭东
