原创 李浩杰 CodeIsPower
2025年03月01日 22:54 广东
周四去深圳市政府见一个客户A,说是技术交流,但是提问的是个不懂技术的领导,当我们开始说技术实现相关细节时,就被打断,最后接受了一堆需求。其实这个活应该售前去,毕竟是吹牛逼大会,做技术的都比较现实一些,能做我会说一定完成,不一定能做的就不会乱说,导致客户说我们技术不行,我就笑了。
今天加了个班,去拜访了另一个客户B,果然人与人之间的沟通还是要有话共同的话题才行,客户B是纯纯的技术大佬,我们都在做AI相关的实践,有着很多的共同话题,交流了“如何使知识库检索更准确”、“在知识库检索之前应该做哪些事情”、“大模型在公文领域的实践及相关问题解决方案”、“知识图谱对于知识库检索准确度的提升”等话题,大佬在海量公文政策的AI实践中得到了很多经验,这次交流不仅验证了我们的技术可行性,同时也得到了很多不一样的想法。
加完班就赶紧回家里,准备写这篇文章,毕竟这是实践得到的真知,十分难得。如果你觉得这篇文章对于你的实践有用,请关注+点赞+推荐+转发支持一下。
政务领域AI实践遇到的问题•大量公文检索容易不准,且会出现AI幻觉•政务服务事项指南检索不准•几百页的文件如何提取信息,并导入知识库•意图识别不准确该如何解决
常见操作及问题我们在说检索问题之前要先了解下知识库检索的大致流程:
(1)用户输入了一句话
(2)在知识库中检索相关内容
(3)大模型进行RAG增强输出

同时我们也要审视下自己在使用知识库(比如Dify的知识库)时,是不是存在以下几个问题:
(1)直接上传文档,管它是PDF、Word、Excel
(2)上传文档之后,直接在工作流中配置知识库,没有任何前置和后置的工具
(3)当检索不准确的时候,就开始疑惑:为什么它不准啊,查找各种资料,都找不到方法解决。
准确度影响因素-文件类型
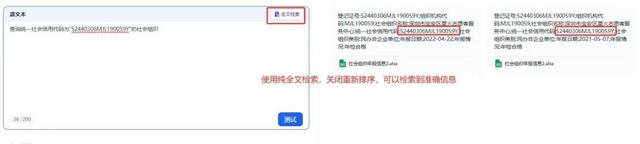
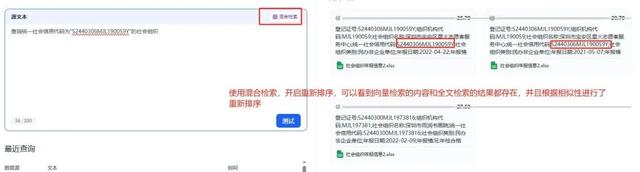
在我做具体实践时,发现Excel中的数据记录相互之间是没有语义关联的,对于向量检索不是很友好,对于这种问题有几种说法:
(1)向量数据库通过多维度特征转换数据,可能更适合非结构化数据。如果Excel表格中的数据结构不够丰富,或特征提取不当,转换后的向量可能无法准确反映语义信息,影响检索效果;
(2)向量检索在处理非语义内容(如编号)时效果不佳,而全文检索可能也不适合这种情况,如果Excel中包含大量非语义的字段,单纯依赖向量检索可能无法准确匹配,需要结合其他方法(如混合检索);
(3)如果用户的需求是精确查询,使用向量检索可能不适合。在Excel中添加标签辅助RAG检索,可能用户未对数据做足够的预处理或标签优化,导致向量库的检索效率低下;
 准确度影响因素-分段
准确度影响因素-分段我们在Dify中使用知识库时,有时候搞不懂他的分段规则,就直接选择了自动分段与清洗,如果你的文本是提前准备好的,有良好的分段标准,这样是可以的,但是如果你的文本没有什么格式,还要使用自动分段,就要看下分段结果了。
自动分段可能存在两个问题:
(1)上下文割裂:自动分段可能会过度切割,这样会导致关键的上下文丢失(比如错误的解决方案要依赖前置场景的描述)
(2)语义碎片化:短段落可能会丢失逻辑关联(如多步骤操作说明被拆散),导致找回结果不完整
这个时候,如何分段就比较重要了,结合我们的实践,有以下几点分段建议
段落长度控制:
(1)推荐段落保持在50-500字,太短会导致信息被拆散,太长则容易引入噪声(和段落主意不相关的内容)。论文研究表明,200-300字段分段效果较好。
(2)提前整理好文本,按照一定格式分段,比如自然段落、换行符、特定符号等,而非固定长度。
结构化分割方法:
(1)根据内容不同处理方案不同,比如技术文档就可以按照功能模块和章节进行拆分(比如接口参数定义和示例分开放置);对话日志一单词对话伦茨为单元,保留提问与答复的关联性。;再比如长图文内容,可以拆分文字和独立图注,避免跨模态混合检索混淆。
(2)结合NLP技术,使用分段模型识别语义边界,对文本进行分割。
上下文增强设计:
(1)使用分层嵌套结构,比如大标题段落下保留字段索引(如【安装步骤→步骤一→注意事项】),检索时允许跨层级关联。这个简单理解就是先总结文本,再对文本分段,总分结构。
(2)根据文本内容提取标签(客户现场使用了这种方案),通过大量的标签来拼接内容,同时使用标签缩减内容的长度,避免内容长度过大导致AI幻觉。
实际案例对比:
分段方案
召回率
准确率
问题示例
整篇文档直接搜索
高
低
搜【公文摘要】,返回整篇公文
固定200字强制分段
中
中
答案被切到两个段落导致遗漏
按自然段落动态分段
中高
高
精准匹配FAQ独立问答块
NLP语义分段+结构标记
高
高
跨段落【公文标签+公文详情】
准确性影响因素-大模型的节点位置在知识库的应用中,大模型常常是在知识库检索完成之后,对检索内容进行RAG增强输出,但实际上如果想要知识库检索准确,也可以先让大模型对语义进行一层转换,举个例子:
政务服务事项中有一项是《企业职工个人缴费历史更正》,其中有段描述是重复缴费,当我作为一个普通人去办理相关事项时,根本不知道重复缴费的概念,就问了一句大白话”我缴了两次费怎么办“,此时向量匹配的结果命中率还比较低。
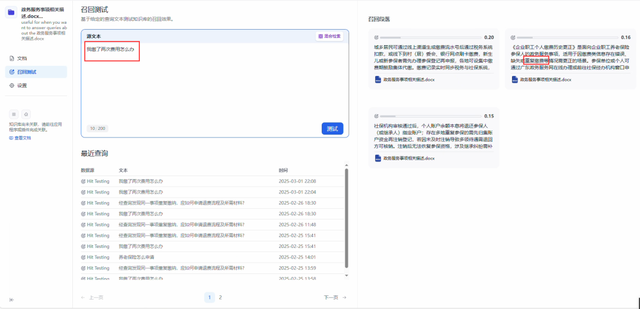
那么,我为了让它更精准,在知识库检索之前,让大模型对”我缴了两次费怎么办“这句话进行了调整,我给的提示词是”以政务服务办理的场景重新描述下这句话:我缴了两次费用怎么办,要求字数相当,语义不变,符合政务服务办理标准场景“

转换之后的结果为”经查询发现同一事项重复缴纳,应如何申请退费流程及所需材料“,再次看看知识库检索的效果吧。


转换之后的结果查询更准了,且匹配度更高,这就是换一种说法的重要性。
几百页的文档如何提取信息并导入知识库其实这个也没有什么更好的办法,比如纯文字的word文档,很容易提取信息,但如果word中有表格,就需要对表格进行处理,甚至如果表格横跨多页,就更难处理了。针对于现在的文档,客户现场是使用OCR识别提取,而我们用的是多模态大模型提取,都有同样的问题,如果少量的文档还好,如果是几百页的文件,可以拆分成单页进行处理,此时头疼的事情应该是分页提取完成之后的数据如何整合。
意图识别不准确应该怎么解决意图识别是整个处理过程的第一步,对于后续的处理效果和效率非常重要。常见的有几个方法:
(1)添加领域近似关键词,比如户口本、户口簿、户口等
(2)上下文联动,比如我上一句刚问完出生医学证明,下一句就问了社保怎么办,应该要对连续意图进行关联分析,得到我是要办理新生儿社保。
(3)数据扩充,比如刚刚说的大模型对白话进行专业领域语义的改写扩充
以上仅包含交流的部分成果,还有一些新内容,我个人也得消化一下再输出,毕竟输入才会有输出,好文章绝对需要实践才能有价值,浅显的概念价值太低。
交流过程中,大佬还提了下DeepSearch,嘱咐我要深入研究下这个,我寻思着,这不是前几天的清华大学第四弹的内容吗,看来我要认真看下里面的内容了,如果你也需要,我给你准备好了
清华大学第一弹:DeepSeek从入门到精通.pdf
链接:https://pan.quark.cn/s/ebd4eee8353d
清华大学第二弹:DeepSeek赋能职场.pdf
链接:https://pan.quark.cn/s/4b5169b97b49
清华大学第三弹-普通人如何抓住DeepSeek红利.pdf
链接:https://pan.quark.cn/s/c6111c89b5ba
清华大学第四弹:DeepSeek+DeepResearch:让科研像聊天一样简单.pdf
链接:https://pan.quark.cn/s/0d7b2cc3227e
清华大学第五弹:DeepSeek与AI幻觉.pdf
链接:https://pan.quark.cn/s/2080be4339b7
北京大学 - DeepSeek内部研讨系列:DeepSeek与AIGC应用.pdf
链接:https://pan.quark.cn/s/4fda5d5a6058
北京大学-DeepSeek系列-提示词工程和落地场景.pdf
链接:https://pan.quark.cn/s/1173af4d6a1f
