事件性驱动:
抛弃OpenAI,Figure推首个VLA模型,一句话让机器人搭伙干家务
美国人形机器人独角兽Figure AI重磅推出了一款通用型视觉语言动作(VLA)模型——Helix,能够将感知、语言理解与学习控制融为一体,首次实现了对人形机器人完整上半身高速连续控制。


2017年Transformer架构是大语言模型(LLM)的最底层的基座,但Transformer不止可以应用于大语言模型中,也可以用于训练其他类型的数据。
在大语言模型(LLM)中,语言被编码为向量,研究员们为模型提供大量的语料,使其具备上下文学习、指令遵循和推理等能力,借此生成语言回答。

2023年7月28日,Google DeepMind推出全球首个控制机器人的VLA模型RT-2(Robotics Transformer 2),可以从网络和机器人数据中学习,并将这些知识转化为机器人控制的通用指令。
而在视觉语言模型(VLM)中,模型可以将图像信息编码为与语言类似的向量,让模型既能理解文字,又能以相同方式理解图像。研究员们为模型提供大量的语料和图像,使其能够执行视觉问答、为图像添加字幕和物品识别等任务。
视觉和语言数据属于被动数据,可由人类提供,而机器人的动作数据属于主动数据,来源于机器人自身,获取难度大、成本高。
RT-1是迈向视觉语言动作(VLA)模型的一个尝试,它的数据集包含了视觉、语言和机器人动作三个维度,但RT-1的能力很大程度上由数据集和任务集决定,对新指令的泛化仅限于以前见过的概念的组合,且要进一步扩大数据集规模是一件非常困难的事。
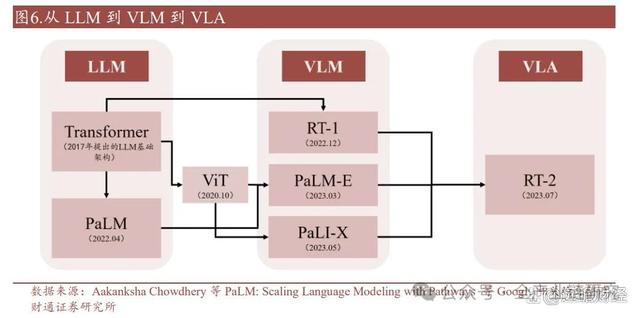
通过从大型的、多样化的、与任务无关的数据集中迁移知识,现代机器学习模型能够以较高的性能解决特定的下游任务,但这种能力在机器人领域仍有待进一步的应用考证。
行业交流
Q&A
Q:Figure推出的Helix模型,模型推出后对机器人通用应用或商业化应用带来了什么影响?
A:在机器人聚生大脑方向,传统采用模块化方案,将感知、决策和执行分开。特斯拉FSD方案转到端到端后,激发大家将模块化方案往端到端迁移,但因端到端方案需大量数据积累,中间出现了分层级模型,目前仍是主流方案。
分层模型利用传统机器人控制算法模块,在感知和执行部分拼接传统算法,有突破的是引入大语言模型,后发展到多模态大模型(VLM模型)。不过VLM模型对算力要求高,面临将模型参数量优化、蒸馏以面向端侧推理的工程问题。Figure AI发布的Helix模型是原来分层级模型端到端大脑的最新研究成果,仍属分层级范畴。

Q:Figure采用VLA和VRM结合的双系统控制方式,其他主机厂在模型控制上将来是否会沿用这种方式?

Q:视频中展示的一个模型控制多个智能体实现多机协作的动作,对模型要求难度提升大吗?对于现实应用和工程学来讲,是否是人工智能比较大的进步?
A:一个模型控制多个智能体在人形机器人上是很超前、突破性的方式。此前在学术领域,控制无人机群、机器狗等实现多个智能机器人群体控制的算法已较成熟,也是用一个模型在云端或远端云端大脑进行控制。Figure X把它应用到人形机器人上虽让人感觉惊艳,但目前来看不属于难度非常高的事情。因为做好VLA模型,天然就可以进行多智能体的协作和协同,其在互相交互上能准确识别和交互对方动作,单个模型分开协作也可行。估计是用两个机器人协作的数据进行训练,就能让两个机器人很好地协同,本质上不是难度极大的事情,就像人进行群体协作也需要大量训练和试错。
Q:国内外人形机器人厂商在模型端的情况,包括发展阶段差异,以及基于自有模型和通用大模型这两种方式的对比
A:目前国内外在端到端模型上的发展不存在非常明显的差异,大家基本在同一起跑线,很多国内发布的方案或开源版本的模型在操作性能上可能比国外的还好。国内做VLA的公司,如智源、银河通用、新动力纪元、新海图等,将VLA模型作为未来研发突破的核心,这是其技术壁垒。
而一些本体或运动控制公司可能因自身能力或投入问题,会找专门研究VLA模型的公司合作,如穹初、千珏科技等,它们只专注于大脑方案。目前大家能参考使用较多开源模型和方案,比拼的是工程落地能力和模型架构或方向的创新能力,很难拉开大差距。特斯拉擎天柱机器人未公开大脑方案,其技术源于自动驾驶的FSD端到端系统,若其实力强、数据量多,可能直接用视觉、文本、动作输出训练模型,无需参照成熟文本大模型做预训练的token输出。
创业型或实力不够强大的公司只能用预训练好的模型对视觉和文本编码,结合本体微调数据做本体的VLM模型。未来大家比拼的重点是能否基于本体采集到足够精细化或训练微调的数据,训练出更适用于本体的VLM或VLA模型,这可能会进入类似大模型比拼时,比拼资金资源、算力和数据量的军备竞赛阶段,模型架构或方式的创新对最终好用的基于本体的VLM模型的作用和影响可能会越来越弱。
Q:在目前硬件版本存在差异,各类关节设计方式、自由度设计方式有较大不同的情况下,模型在不同硬件设计方式上的使用有无较大差别,是否都可以适配?此外,定位通用场景(如家庭服务)和工业场景的机器人,在工业场景使用时对模型的要求是否会降低?
A:首先,目前硬件结构或架构与VLA模型有一定耦合度,但没有想象中那么高。以Figure AI的Helix模型为例,其System 2的70亿参数的VLM模型与硬件本体不绑定,可随意迁移;System 1的8000万参数模型,若迁移到别的人形机器人上,只需重新训练这8000万参数即可。从训练VLA的数据集和方法来看,开源数据集包含各种不同结构的机器人数据,如斯坦福和伯克利的DROID Drive数据集、Open X Embodiment数据集、北京人形创新中心与北大、北苑智源AI研究院采集的数据集等,用这些异构数据能成功训练出预训练模型,之后基于本体硬件结构收集微调数据集进行训练,成功率和效率都不错。在工业领域和家庭领域落地方面,从软件或模型的架构、参数量上看是一样的。但工业场景的数据标准化更简单、统一,场景更“干净”,不需要考虑复杂的极端情况;而家庭场景会面临众多极端情况,每个人家里环境不同,难以收集覆盖所有家庭场景的数据进行微调训练,未来比拼的是模型的泛化能力。泛化能力好的模型适合家庭等复杂场景,泛化能力差的模型只能用于工业等简单重复劳动场景。
Q:从目前各家厂商模型的发展阶段来看,真正能够落地到工业端或其他场景端的时间节点大概是什么时候?
A:今年在VLA模型上会有较大的落地场景或推动,不过不是在工业场景,而是在商业服务领域,如商超服务人员、24小时连锁便利店、商业性咖啡店、奶茶店、快餐店等,这些场景内部装修风格统一,使用的设备机器标准化,容易落地且能泛化,可实现与人交互并提供场景服务。今年下半年或一两年内商业上会有较大突破。往后五年左右,会进入家庭中的特殊照顾场景,如孤寡老人或独居老人的看护、情感陪伴等。工业领域其实已经开始渗透,当成本和价格达到一定阶段,会出现大批量机器人替换人工的情况。
Q:目前海外在机器人专用大模型上走得比较领先的公司以及国内走得比较靠前的公司分别有哪些?
A:很难评判谁的模型做得好。海外的Figure AI的派林(Paling)专注于做端到端的大脑,为他人赋能。国内与之对应的有琼策、千珏等公司,它们因派林获得融资刺激而成立。派林发布的模型架构未超出预期,最早用UR机械臂做训练,没有完整的人形机器人,还为国内星辰提供上半身的VLA模型算法。国内在第一梯队往产品级落地方向发展的公司有新海图、银河通用,它们有仿真作为合成数据来源;智远有上海人工智能研究院及北大合作联合实验室的资源支持。此外,中科院自动化所下面的公司发展势头很猛,如中科汇灵的灵宝机器人,依托强大的算法模型和师资力量团队,未来有可能后来居上。其他公司主要集中在小脑和本体方面做商业落地,多用于教育、科研。
Q:模型端不断演变,除了加速产品应用外,对于行业端是否会有其他变化,是否会带来其他方向的投资机会?
A:专门做VLA模型的公司目前核心重点放在软件端,认为未来比拼人形机器人在于大脑端、软件端,他们可能会找大的上市公司代工厂合作做本体硬件。一些公司如索辰科技基于物理引擎算法、CCAE软件与上海交大合作做原型机子公司,在未来的世界模型方面会有独特之处。未来将VLA模型和世界模型结合,涉及世界模型的上市公司或未来可能出现的公司爆发可能性会大大增强。世界模型能让机器人不仅有更好的泛化能力,还能预测动作结果,此时在世界模型算力上有优势且能结合的公司值得关注。此外,一些原来做游戏的公司,如上海的游族网络,尝试将人形机器人的大脑应用到游戏开发、RPG结合上,未来涉及的方面很多。

















