01 产业链全景图

02 最新消息

03 什么是DeepSeek
DeepSeek 是一家人工智能技术公司,中文即“深度求索”。它家的模型在自然语言处理和代码生成等领域相当能打,像DeepSeek-v3在多个数学基准测试和代码能力测试中,就超越了众多竞品。
真正让DeepSeek火出圈的是2024年12月26日,这家公司宣布上线并同步开源的 DeepSeek-V3模型。它以1/11的算力、仅2000个GPU芯片训练出性能超越GPT-4o的大模型。其总训练成本只有557.6万美元,而GPT-4o的约为1亿美元,使用25000个GPU芯片。双方的成本至少是10倍的差距。
在性能上,DeepSeek-V3在数学、代码能力和中文知识问答方面还超过了ChatGPT-4o,以下即为两者的模型参数对比:

04 为什么被称为AI界的拼多多
据公司介绍,在数学、代码、自然语言推理等任务上,DeepSeek-R1性能比肩已经OpenAlo1正式版,这并不是关键,关键它还是开源的,代码全部公开,更关键它还特别便宜,价格相当于使用OpenAlo1的3%,人称价格屠夫,更更关键的是,它的训练成本非常低,只花费了两个月时间、557.6万美元!而ChatGPT-4的训练成本约为1亿美元,更不用说更为先进的OpenAlo1正式版,这样的性价比,无愧成为AI界的拼多多了!
05 怎么实现?
举个通俗的例子,DeepSeek为什么能花更少的钱办更大的事呢?
就像两个学生复习考试:ChatGPT像是一个用笨方法复习的学生,它搞题海战术(消耗大量算力),大力出奇迹,虽然考了高分,但累得精疲力尽。DeepSeek则像是个会找规律的学生:它发现考试重点其实只占书本内容的20%(优化训练数据),通过分析历年真题(算法优化),用更少的时间就掌握了核心考点。从技术层面来说,DeepSeek使用了以下关键技术:

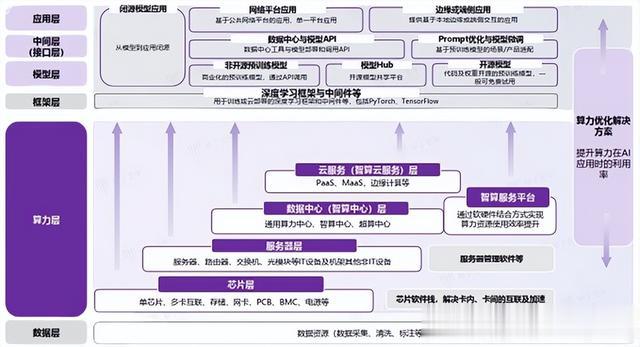
06 上游产业链
虽然DeepSeek通过自身的蒸馏模型降低了对于算力的需求,但是如果想要获得更高的模型精度,训练所需算力消耗并未必会减少,因此上游的算力需求依然强劲。
全球算力主要由通用算力、智能算力和超算算力组成。通用算力作为基础,满足广泛的日常计算需求;智能算力则在新兴技术领域发挥关键作用;超算算力针对特定高端需求提供强大计算能力。数据显示,2023年底全球算力总规模约910EFLOPS,其中,智能算力从2021年的113EFLOPS增长至2023年的335EFLOPS,增速远超其他。

满足大模型需求的算力是一项涉及多层面复杂系统工程,因为它不仅需要在计算能力上实现指数级增长,以应对大模型的庞大惨数量,还要在数据传输、存储和处理等多个维度深度优化。AI算力具备软硬件的复杂性,并且以不同产品/服务/方案为应用赋能
AI技术在实际应用中包括两个环节:训练(Training)和推理(Inference),AIGC的算力需要考虑训练及推理两个方面。
训练是指通过数据开发出AI模型,使其能够满足相应的需求,一般为AI技术的研发。因此参数量的升级对算力的需求影响大。
推理是指利用训练好的模型进行计算,利用输入的数据获得正确结论的过程,一般为AI技术的应用。推理部署的算力主要在于每个应用场景日数据的吞吐量。

06-1 AI芯片
芯片作为算力产业的基石,为智能算法和应用提供了不可或缺的计算能力。在服务器成本中,核心芯片如GPU占据了超过80%的比重。掌握自主可控的AI芯片技术,对于智算产业的持续发展至关重要。
随着人工智能应用场景的不断拓展,市场对高性能AI芯片的需求日益增长。数据显示,2023年中国AI芯片市场规模已达到约652亿人民币。预计到2026年,市场规模将显著增长至1611亿人民币,AI芯片市场正迎来快速发展的黄金时期。

2023年上半年,中国加速芯片的市场规模超过50万张,GPU卡占有90%市场份额,非GPU卡占据10%市场份额。中国本土AI芯片品牌出货量近5万张,占整个市场的10%。
2024年上半年,中国加速芯片市场规模超过90万张。GPU卡占据80%市场份额,非GPU卡占据20%市场份额。中国本土AI芯片品牌出货量近20万张,约占整个市场的20%。

06-2 AI服务器
AI服务器是智能算力的重要载体,在全球范围内迅速扩张。2023年,全球AI服务器市场规模突破500亿美元,增幅高达95.8%,预计到2028年,市场规模有望突破1000亿美元,五年的年复合增长率预计为14.5%。
中国AI服务器在AI及智算产业的高速发展下持续攀升,从2020年的149亿人民币增长至2023年的692亿人民币。随着AI应用的成熟和普及,市场对于AI服务器的需求预计继续增长。预计到2028年,中国AI服务器的市场规模达到1433亿人民币。

06-3 智算中心
智算中心即人工智能计算中心,是基于人工智能理论,采用人工智能计算架构,专门为人工智能应用提供所需算力服务、数据服务和算法服务的一类算力基础设施。
智算中心配备了大量高性能服务器以及 GPU、TPU 等专业加速芯片,能够提供强大的计算能力,可迅速处理大规模的计算任务

06-4 AI云计算
纵观整个行业,我国云计算市场展现出强劲的增长势头。2023年,我国云计算市场规模达6165亿元,同比增长35.5%。随着AI原生带来的云计算技术革新和大模型规模化应用逐步落地,云计算产业预计将开启新一轮增长周期。到2027年,市场规模有望达到21404亿元,增长潜力巨大。
市场格局方面,阿里云、天翼云、移动云、华为云、腾讯云和联通云六大云服务商共占据了我国公有云71.5%的市场份额。

07 中游产业链
从产业规模看,全球人工智能快速增长。2023年全球人工智能市场收入达5381亿美元,同比增长18.5%,到2026年市场规模将达9000亿美元。
从投融资看,2024年Q1全球AI领域完成1779笔融资交易,筹集的风险投资总额达216亿美元。

截至2024年底,我国预计有大大小小的模型240多个,从从客户数量、模型性能和能力,品牌力等出发,国内前十的大模型公司是:文心一言、豆包、Kimi、秘塔、腾讯混元、通义千问、360智脑、百川智能、零一万物、讯飞星火。其中,文心一言、豆包、Kimi是最出名的3款软件。
DeepSeek虽没上磅,但它是后期之秀!国内目前没有哪一款能与之全面媲美,而DeepSeek对标的就是国外Open AI的o1和Claude 3.5。

08 下游产业链

09 背后的人物——梁文锋
其实,在DeepSeek爆火的背后,更有意思的是背后的创始人及团队!
DeepSeek背后的创始人是梁文锋,通过对于公司股权的深度穿透,结构图如右边所示,梁文锋即为公司的实际控制人。
从公开资料来看,DeepSeek团队最大的特点就是名校、年轻,目前共139人。有大模型领域的猎头透露,当下“C9”院校的高端人才各家都在争抢。“DeepSeek更着重宣传,符合他们家年轻化,求知欲的价值观。”

私募界的巨头——幻方量化
如果是从事金融行业的朋友,相比对于幻方量化不会陌生。而Deep Seek的母公司,正是梁文锋在2015年创立、量化基金起家的幻方量化。作为一个“80后”,梁文锋本科、研究生都就读于浙江大学,拥有信息与电子工程学系本科和硕士学位。
2017年,幻方量化宣称实现投资策略全面AI化。2019年,其资金管理规模超100亿,成为国内量化私募“四巨头”之一,也一度是国内首家突破千亿私募的量化大厂。当幻方量化规模节节攀升时,梁文锋却开始转移视野。
在业界,幻方一直以敢于在硬件上投入著称,以支撑其交易系统的实施。2017年前后,梁文锋开始涉足AI相关探索,探索孵化AI项目“萤火虫”。2018年,“萤火虫”超级计算机对外正式亮相,并称计算机占地面积为数个篮球场,前后投入超过10亿元。
2024年10月,幻方量化向投资者公告称,计划逐步将对冲产品投资仓位降低至零。该公司部分对冲系列产品规模已经降至千万元以下。至2025年初,公司资金管理规模已小于300亿,退出了行业前六名。于是,DeepSeek开始火了!
2024年5月6日,DeepSeek推出第二代大模型DeepSeek-V2,以极低的价格策略——每百万 tokens 输入1元、输出2元,引发了行业轰动。其成本仅为GPT-4 Turbo的约1%,迅速搅动AI大模型价格战,推动字节跳动、阿里云、科大讯飞等巨头相继调整定价策略。外界虽有人质疑这是“赔钱赚吆喝”,但梁文锋明确表示,这一策略源于技术进步带来的成本下降,以及其“人工智能应普惠大众”的坚定理念。
事实上,梁文锋并未将与大厂的竞争放在首位。在他看来,云服务并非目标。他真正追求的是实现通用人工智能(AGI)。
为了这个目标,梁文锋选择跳脱模仿的框架,坚持走创新的道路。于是我们看到,DeepSeek-V2不仅在价格上打破行业规则,更在技术上大胆革新。
仅仅半年后,这个被硅谷誉为“来自东方的神秘力量”的团队,于2024年12月26日发布了第三代大模型DeepSeek-V3,采用6710亿参数的混合专家模型(MoE),表现不输GPT-4o和Claude 3.5等闭源模型,而训练成本却仅为557.6万美元,不足OpenAI GPT-4(6300万美元)的十分之一。在这一过程中,DeepSeek始终坚持“开放”与“普惠”的理念。

来源-RunningLu 飞跑的鹿 2025年02月16日 20:30 广东
