
去年,在OpenAI刚刚横空出世的时候,国内的大语言模型还不多见。然而,仅仅一年多后的今天,中国的大语言模型领域可谓“江湖门派林立”,已开始出现“过剩的趋势”。
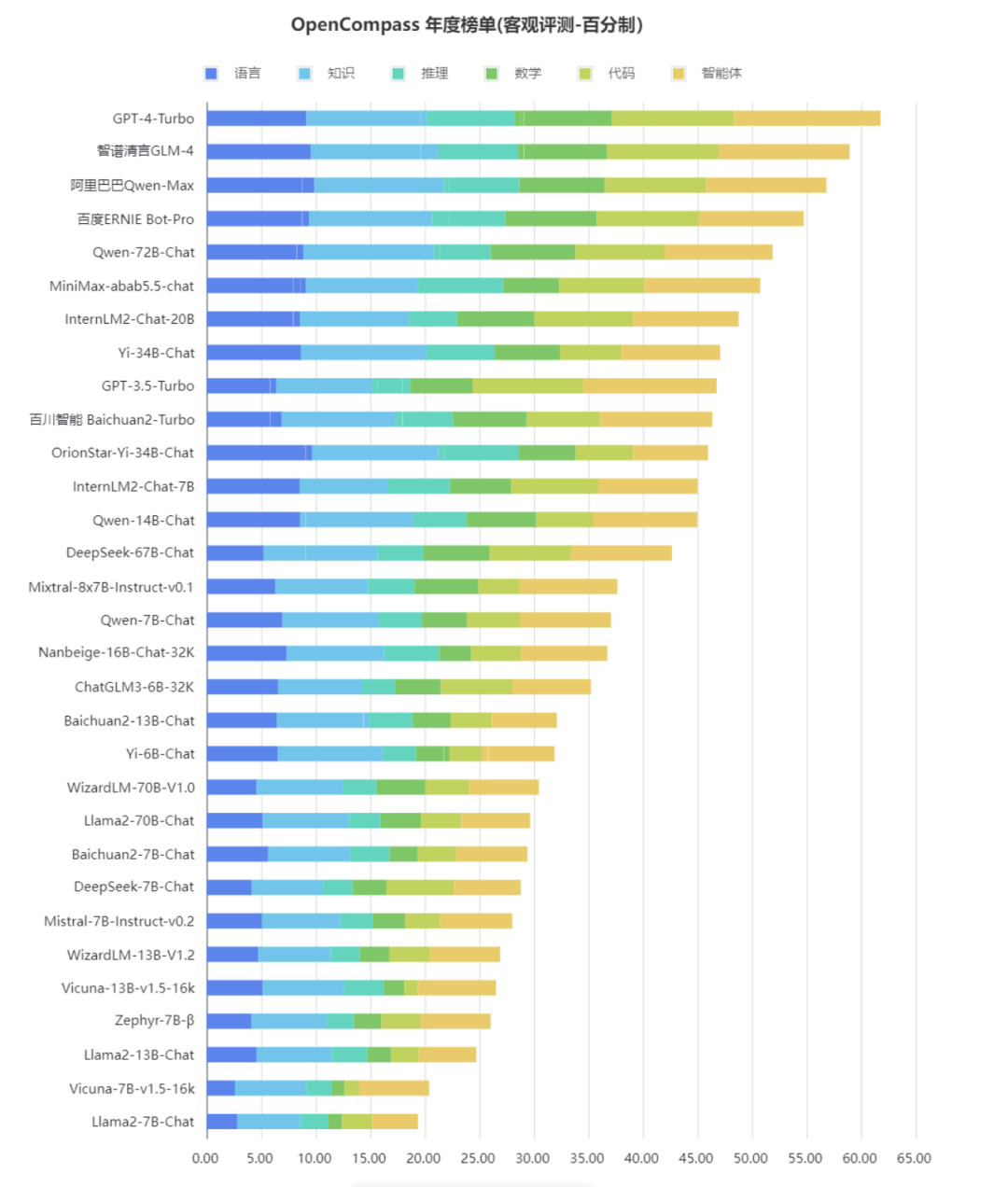
年初时,大模型开源开放评测体系司南(OpenCompass2.0)揭晓了2023年度大模型评测榜单,对过去一年来的主流大模型进行了全面评测诊断。结果显示,GPT-4-Turbo在各项评测中均获最佳表现,而国内厂商近期发布的模型则紧随其后,包括智谱清言GLM-4、阿里巴巴Qwen-Max、百度文心一言4.0。而近日亦有聊天机器人相关研究机构对全球大语言模型的性能进行了排名,有5个中国的大语言模型进入了世界前20名,并且在某些指标上——比如上海的商汤科技开发的Sensenova 5.0模型,在逻辑推理和创意写作方面的评分甚至超过了chatGPT-4。
下图:2023年度中英双语客观评测榜单(图片来源:澎湃新闻)
一
“百模”价格大战
《经济学人》在今年6月中旬预测了中国大语言模型的相关收入,将从2023年的不到200亿元人民币增加到今年的220亿元人民币,并且在2028年翻5-6倍。因此,技术的快速迭代所推动的财富前景激励了很多领域的有识之士纷纷加入这一“大模型战场”。去年,百度的CEO李彦宏曾表示:“中国每天都在出现一个大语言模型”,这话虽略显夸张,但也不为过。据估计,中国目前已经拥有100多个模型,参数超过10亿个,并且开发者正在将这些模型转化为各种产品。
下图表:《经济学人》对于中国大语言模型的收入预测(图片来源:21jingji.com)

然而,由于目前国内市场还缺乏像OpenAI这样在技术上处于明显领先地位的头部“标杆式”大模型,即还没有任何一款模型能够在技术上形成明显的竞争优势,因此大多只能在价格上开展竞争。
于是,大家可以看到,在短短一年左右的时间里,国内大模型的“赛制”已经从“资格赛”转变到了“淘汰赛”。那些刚刚迈过资金门槛的大模型厂商,立刻又被卷入价格战的漩涡。而打响这场价格战第一枪的“斗士”则是今年5月6号,建立了自己的AI模型的量化对冲基金幻方资本,将其最新版本的模型价格下调至“每百万token输入1元,输出2元”,这大约是GPT-4收费的近百分之一的水平。业内人士给出了“性价比高得难以置信”的评价。
由此,一场声势浩大的“百模大战”拉开序幕:
——5月15号,抖音的母公司字节跳动打出了“低于行业平均价99.3%”的旗号开始出售他的最新模型豆包Pro 32k,并宣告“用户花费1块钱就可以获取与5本《新华字典》相当的数据量”;
——一周后,阿里巴巴的通义千问的9款模型一起降价,其中主力模型Qwen-Long的价格直降97%;
——紧随其后的几个小时,百度智能云则直接宣布文心大模型两大主力模型ERNIE Speed和ERNIE Lite免费;
——腾讯云则称,其主力模型之一混元-lite模型的价格从0.008元/千tokens调整为全面免费,其他模型降幅最高达87.5%;
——科大讯飞则表示轻量级模型API永久免费。
下图:豆包通用模型 pro是字节跳动自研 LLM 模型专业版,具有理解、生成、逻辑和记忆等综合能力(图片来源:m.36kr.com)

下图:阿里的通义千问在5月21日宣布的降价共覆盖9款商业化及开源系列模型(图片来源:m.ebrun.com)

下表:腾讯云在5月22日全面下调大模型价格(图片来源:wap.eastmoney.com)

二
大战下半场,如何卷出真“刚需”?
显然,所谓“百模大战”其实是各大模型厂商之间的数据竞争,这种现象有点类似于当年滴滴和快的之间的打车竞争格局,即从商业策略角度而言,现阶段大模型降价的主要目的还是收集数据。
不过正如科技投资者李开复所言:“国内大模型市场疯狂降价是双输的打法”。低价或者免费虽然可以暂时吸引更多的使用者,从而累积更多的数据来训练更加智能的算法,但是如果由此导致收入下降,那么也就意味着企业训练机器人所需的大量资金也将会大大减少,那么收集到更多用户数据的作用就微乎其微了。而且,在大型模型厂商前期烧掉的资金还没有收回时就开始投身价格战,这无疑大大加剧了资金风险。
根据亿欧智库发布的《2024中国“百模大战”竞争格局分析报告》,通用大模型历经创业爆发期后,预计市场将于2025至2026年逐渐出清,优势企业坚守战场,剩余企业陆续退出竞争;2027至2028年,通用大模型市场将呈现寡头竞争格局。因此,从长远来看,“价格战”最有可能导致的后果就是——中国人工智能产业被整合到阿里、百度、字节跳动和腾讯等少数财大气粗的科技巨头手中,因为这些大公司都是具备“云服务”的,所谓“醉翁之意不在酒、模翁之意正在云”,他们真正的目的是通过大模型来扩大云客户的基数和规模,进而提升云计算的市场渗透率。
下图:2024 阿里云战略发布会上,刘伟光介绍对云计算的趋势判(图片来源:m.36kr.com)

由此可见,这一场正在进行中的成本奇高的顶层千亿大模型的角逐,不管是对企业用户还是对个人用户来说,都尚未形成一种“刚需”,这或许才是“百模大战”的下半场建立在“用户使命”之上的制胜法宝——即“做好应用,才是大模型创业的核心!”
正如OpenAI首席执行官萨姆奥特曼(Sam Altman)在接受《麻省理工学院技术评论》采访时表示:“人工智能应该比最勤奋的人类行政助理更加努力地为用户服务”。本质上,今天的AI是把“电能转换成了智能,把人口红利转换成了算力红利”,这必然走向一场巨大的生产力变革。这也是为什么去年9月,当微软把GPT集成到Copilot并公布定价的一刻,其股价在盘中涨了6%!虽然这仅仅是一个30美金/月的产品,但却让资本市场看到了“强应用”!
当年电力刚出现的时候,第一个用电的面包厂就是高科技面包厂,因为它的工作效率是用驴拉磨的面包厂的百倍,那么它就有了比别人高百倍的利润,这就是所谓的竞争优势。如今的大语言模型在应用层面还有待无限发挥的创造力来开发各种垂直领域的解决方案,如各行各业的专业教练、如机器人流程自动化等等。只有真正抓住有市场价值的应用,并提供高质量的解决方案,这样的大模型(和小模型)产品才能在竞争中脱颖而出。
下图:微软Copilot发布,多平台联动全面优化用户体验(资料来源:中航证券研究所)




作者:上海产业转型发展研究院常务副院长
编辑:林欣蓝
审核:夏 雨
