自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。未来,随着技术不断进步,其应用前景将更加广阔,为各行业带来更多智能化解决方案。


(1)行业定义
自然语言处理(Natural Language Processing,N)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分 。
自然语言处理主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面 。
图表1 自然语言处理的概念
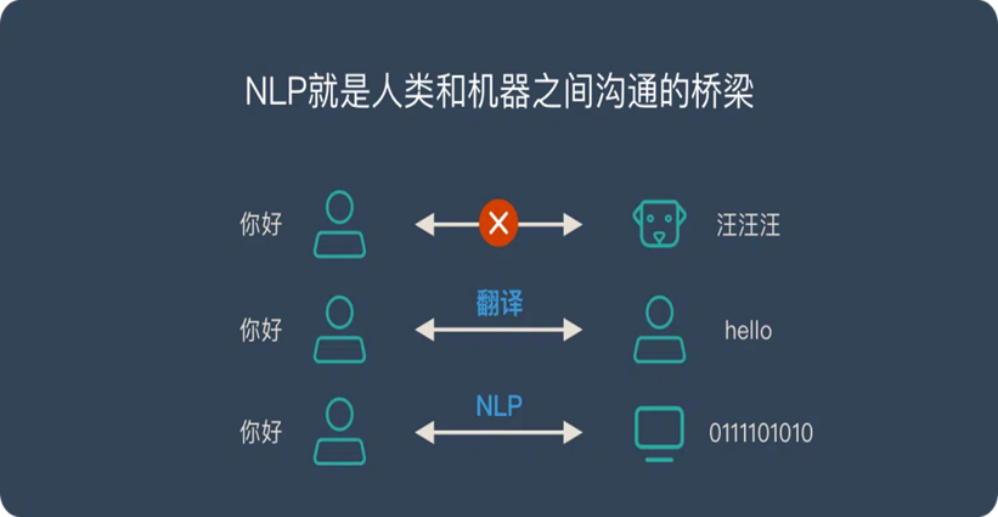
信息来源:CSDN、整理
(2)行业分类
(1)核心路线分类
自然语言处理有两个核心的任务:一是自然语言理解(NLU);二是自然语言生成(NLG)。自然语言理解就是希望机器像人一样,具备正常人的语言理解能力,由于自然语言在理解上有很多难点,所以 自然语言理解是至今还远不如人类的表现。自然语言生成 是为了跨越人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式,如文章、报告等。具体NLP技术路线的发展见发展历程部分。
(2)应用场景分类
图表2 自然语言处理的典型应用场景

信息来源:CSDN、研究整理
自然语言处理的典型应用场景可以分为以下四类:(1)情感分析:根据给定的文本,判断其中的感情是正面、负面还是中性,应用于社交网络分析、客户反馈、金融领域市场情绪分析等。(2)聊天机器人:智能聊天机器人是自动化客服的一种高级形式,通过自然语言处理技术,模拟与客户的真实对话。聊天机器人不仅能够处理客户的常见问题,还可以根据客户的个性化需求推荐相应的产品或服务。(3)语音识别与合成:语音识别可以将语音转换为文本,音乐合成技术可以将文本转换为语音,可以应用于语音助手、语音搜索、语音导航等,(4)机器翻译:将一种语言翻译成另一种语言,应用于跨语言沟通、跨语言搜索等。
(3)行业特征
(1)多学科交叉
自然语言处理是典型边缘交叉学科,涉及到语言科学、计算机科学、数学、认知学、逻辑学等,关注计算机和人类(自然)语言之间的相互作用的领域。
(2)行业应用广泛
除前面提及的四个典型场景外,自然语言处理技术在文本挖掘与信息提取、语义网与智能搜索、自动化写作与摘要、社交媒体监控与分析、知识图谱与问答系统、个性化推荐系统等领域均有广泛的应用。
文本挖掘与信息提取:NLP技术可以帮助我们从大量的文本数据中提取关键信息,如人物、事件、时间等,这在新闻报道、历史研究等领域具有重要意义。
语义网与智能搜索:NLP技术使得搜索引擎能够理解查询的真正含义,从而提供更精确的结果。语义网则是通过机器可读的格式描述网络内容,使得机器能够更好地理解网页内容。
自动化写作与摘要:利用NLP技术,我们可以自动生成文章、摘要或其他形式的文本内容,这在新闻报道、广告文案等领域有广泛的应用。
社交媒体监控与分析:通过分析社交媒体上的文本,可以了解公众的观点、知识图谱与问答系统:知识图谱是一种结构化的知识表示方法,它使得计算机能够理解和回答各种问题。问答系统是知识图谱的一个重要应用,它可以帮助用户快速找到所需的信息。
个性化推荐系统:NLP技术可以帮助推荐系统更好地理解用户的需求和兴趣,从而提供更加个性化的推荐服务,这在我们日常生活中的应用非常普遍,例如音乐推荐、新闻推荐等。
(4)发展历程
NLP发展主要分为五个阶段:
图表3 肺部疾病医学影像软件获批情况

信息来源:同济大学、融中研究整理
(1)早期自然语言处理
第一阶段(60~80年代):基于规则来建立词汇、句法语义分析、问答、聊天和机器翻译系统。好处是规则可以利用人类的内省知识,不依赖数据,可以快速起步;问题是覆盖面不足,像个玩具系统,规则管理和可扩展一直没有解决。
(2)统计自然语言处理
第二阶段(90年代开始):基于统计的机器学习(ML)开始流行,很多NLP开始用基于统计的方法来做。主要思路是利用带标注的数据,基于人工定义的特征建立机器学习系统,并利用数据经过学习确定机器学习系统的参数。运行时利用这些学习得到的参数,对输入数据进行解码,得到输出。机器翻译、搜索引擎都是利用统计方法获得了成功。
(3)神经网络自然语言处理
第三阶段(2008年之后):深度学习开始在语音和图像发挥威力。随之,NLP研究者开始把目光转向深度学习。先是把深度学习用于特征计算或者建立一个新的特征,然后在原有的统计学习框架下体验效果。比如,搜索引擎加入了深度学习的检索词和文档的相似度计算,以提升搜索的相关度。自2014年以来,人们尝试直接通过深度学习建模,进行端对端的训练。目前已在机器翻译、问答、阅读理解等领域取得了进展,出现了深度学习的热潮。
(4)预训练语言模型
第四阶段(2017年前后):受到计算机视觉领域采用ImageNet 对模型进行一次预选训练,使得模型可以通过海量图像充分学习如何提取特征,然后再根据任务目标进行模型精调的范式影响,自然语言处理领域基于预训练语言模型(Pre—trained Model,PLM)的方法也逐渐成为主流。2018年ELMo(Embeddings from Language Models)提出通过首先预训练双向LSTM网络,而不是学习固定的单词表示,并进行参数微调来捕获上下文信息。2017年12月6日,Google发布了论文《Attention is all you need》,提出了Attention机制和基于此机制的Transformer架构。这种架构的价值在于其是一种完全基于注意力机制的序列转换模型,而不依赖RNN、CNN或者LSTM。基于Transformer架构以及Attention机制,BERT、T、BART一系列预训练语言模型被不断提出。
(5)大语言模型
第五阶段(2020年前后):在对预训练模型的研究中,研究者很早就关注到了模型参数量对模型性能的影响。在2020年1月23日,OpenAI发表了论文《Scaling Laws for Neural Language Models》,研究了基于交叉熵损失的语言模型性能的经验尺度法则,并且发现:大模型使用样本的效率显著更高,因此最优的高效训练方式是在中等数据集上训练超大模型,并在显著收敛前提前停止。在一系列研究与实证基础上,研究者开始探索语言模型参数规模的上限,以挖掘预训练语言模型的潜力。这种大规模语言模型(Large Language Model,LLM),也就是目前科技公司们都在相继追逐的目标。
图表4 大语言模型发展历程

信息来源:同济大学、融中研究整理
(5)行业规模
根据赛迪顾问的测算,2022年,预计中国NLP市场将保持30%以上的增速,市场规模达174.5亿元。在新业态不断涌现,虚拟人市场、人机交互需求日益扩大的背景下,预计自2026年起,NLP市场将保持35%以上的增速,到2028年,中国NLP市场规模将超过千亿元,到2030年,市场规模将超过2千亿元,2022-2030年均复合增长率达到36.5%。
图表5 2022-2030年中国NLP市场规模与增长预测

信息来源:《NLP技术的产业化应用趋势展望研究报告》、赛迪顾问、融中研究整理

(1)更加注重改善消费者体验
由于互联网和不断发展的沟通、消费和参与渠道,消费者的力量不断增强。因此,企业被迫重新考虑其运营和品牌战略。在当今竞争激烈的市场中,企业必须提供以客户为中心的体验才能赢得现有客户。例如,公司可以使用各种渠道来启用可以响应查询的人工智能聊天机器人。客户互动平台的供应商正在集成自然语言处理等人工智能功能,使用户能够创建可扩展和可定制的客户体验,而无需人工编码或逻辑构建。
(2)多模态融合
未来的NLP技术将不仅仅局限在文本处理,而是会与计算机视觉、语音识别等其他模态的信息融合,形成多模态的自然语言处理。这将使得NLP技术能够更加全面的理解和生成语言,并在智能交互、智能搜索等领域发挥更大作用。
(3)无监督和半监督学习
在自然语言处理(NLP)中,无监督学习(Unsupervised Learning)和半监督学习(Semi-supervised Learning)是两种减少对大量标注数据依赖的学习范式。无监督学习是一种机器学习的方法,它在训练过程中不依赖于标注数据。在NLP中,无监督学习通常用于发现数据中的模式、结构或者分布,而不是直接预测输出标签。半监督学习是一种介于完全监督学习和完全无监督学习之间的方法。在半监督学习中,模型使用少量的标注数据和大量的未标注数据进行训练。这种方法特别适用于标注数据成本高昂,而未标注数据相对容易获得的情况。这两种方法在NLP领域中越来越受到重视,因为它们提供了一种在数据标注资源有限的情况下构建有效模型的途径。
(4)隐私性与安全性的提升
数据是各类人工智能算法的基础,自然语言处理也不例外。特别是在金融、政务、等关键应用场景中,数据安全和隐私保护亟需重视。这需要自然语言处理在应用过程中保持负责任的态度,同时使用在数据安全和隐私保护层面更为先进的算法模型。

(1)百度
……(全篇内容阅读原文获取)
(2)腾讯
……(全篇内容阅读原文获取)
(3)科大讯飞
……(全篇内容阅读原文获取)
(4)拓尔思(300229)
……(全篇内容阅读原文获取)
(5)思必驰
……(全篇内容阅读原文获取)
(6)追一科技
……(全篇内容阅读原文获取)
(7)香侬科技
……(全篇内容阅读原文获取)
(8)出门问问(2438.HK)
……(全篇内容阅读原文获取)
(9)零一万物
……(全篇内容阅读原文获取)
(10)月之暗面
……(全篇内容阅读原文获取)

