报告出品方:华创证券
以下为报告原文节选
------
一、动机
时序类数据广泛存在各个领域中,传统基于统计的方法需要专业的先验知识以及人工特征处理,基于机器学习、深度学习的方法减轻了这种负担,它们以数据驱动的方式学习时间序列中的潜在模式,提供了富有吸引力的方案。
近年,许多基于深度时序模型的工作被提出,依托于神经网络强大的表示学习能力以及不断优化的模型设计,深度学习网络在解决长期依赖性和动态变化等问题上有了更强的能力,在多个领域的时序任务展现出了优秀的性能,包括但不限于金融市场、气象、交通等。
尽管许多时序深度模型都声称取得了重大成就,但相关工作的结论是否适用于其研究外的数据集、应用场景,模型的泛化能力,是值得思考的。
在本文中,我们以深度学习模型骨干网络中的所用的基础架构为分类基础:
RNN:循环神经网络是一个经典的处理序列数据的网络架构,它紧凑地“记忆”过去信息并利用更新的数据进行迭代,因此也常被用于时间序列任务。
Transformer:Transformer 模型基于注意力机制,可以同时处理输入序列的所有位置,并能捕捉序列中长距离的依赖关系。Transformer 模型在 NLP 领域取得了巨大成功后,其变体模型被广泛尝试应用于图像、时序等任务中。
CNN:CNN 最初是为处理图像数据设计的,但它也可以用于时间序列数据,例如通过一维卷积操作,CNN 能够实现捕捉序列中的局部特征。
MLP:一些研究指出,通过合理设计的 MLP 架构的简易模型,也能够达到与复杂模型相媲美的性能水平。
在我们之前的报告中采用了基于 RNN 的 GRU 网络进行量价因子挖掘任务,因此在本篇中我们从剩下的三类中——Transformer、CNN、MLP,分别选择近年较为流行的时序模型继续进行探索;事实上,基于 Transformer、CNN、MLP 的时序模型数之不尽,最终我们选择 PatchTST、ModernTCN、TSMixer 作为代表,它们的骨干网络设计思路上相似,采用了近年时序网络流行的做法,有一定借鉴意义;其次,每个模型以对应的基础架构为主体,分别仅用自注意力、卷积、MLP 完成信息提取,而不使用不同类别堆叠;最后,模型设计简洁,便于添加额外组件。
二、模型介绍
在我们之前的报告《GRU 网络在风格自适应中的创新与应用》中,我们尝试了基于 RNN的 GRU 模型,GRU 由 Cho 等在 2014 年提出,它在每个时间点上通过门控单元自适应地捕获序列数据中的依赖关系,在股价序列的因子挖掘任务中是一个常见的基线模型。

本篇介绍的 PatchTST、ModernTCN、TSMixer 模型,它们为多变量时间序列设计,采用了近年时序网络常见的 Patch+通道独立的设计,并在骨干网络中用多个模块分别实现时序信息交互的学习、通道/特征的信息交互的学习。
本篇介绍三个模型的大体流程可以简化为:

上式对应的模型流程为:1、时序嵌入 2、提取时序维度信息 3、提取特征(或通道)维度信息 4、下游具体任务预测头。
其中,第二、第三步在模型骨干网络中体现,PatchTST、TSMixer、ModernTCN 的实现思路相似;第一步的时序嵌入大同小异。
在下面的章节,我们首先介绍时序嵌入方法,再对 PatchTST、TSMixer 、ModernTCN 的骨干网络进行单独介绍。
(一)时序嵌入
Embedding(嵌入)是深度学习中一种表示技术,例如自然语言处理中,通常将单个词转为“词向量”的形式。词被映射为固定维度的向量后,模型能够学习词与词之间的更为复杂的模式和关系。时序数据在输入深度学习模型前同样也需要进行嵌入,获取时间序列的向量表征。和自然语言的不同之处在于,现实中的时序数据大多是多变量时间序列,自然语言可以视为单变量时间序列。
1、Patch
Patch 指将输入数据分为多个局部区域,在视觉领域有较多运用。例如一张图片按一定窗口大小切分成多个子区域,将子区域排列后转为序列数据,每个区域可以看作类似自然语言序列中的一个 token,进而能使用序列模型对图片进行建模:

本篇介绍的时序模型均在 Embedding 时采用了 Patch 的时序处理方式。
Patch 在时间序列类数据的方法类似于图像:在原始时间序列上使用一个固定大小为 P 的窗口进行滑动截取,窗口每次滑动的步长为 S,由此原始时间序列被拆分为若干个子序列,每个子序列包含 P 个时点的数据,子序列被视为一个 token,映射至目标嵌入维度。
使用 Patch 处理的优势在于:
Patch 后新序列长度近似为原序列的 1/S,降低了计算成本;
有研究提出时序类数据单独一个时点的信息量较少,而 Patch 实质上实现了局部信息提取,使单个 token 能包含更多信息;鉴于上述优点,Patch 成为了近年的时序模型中常见的做法。
2、通道独立
对多变量时序任务,“通道”指输入序列的变量,而“特征”表示序列 token 经过 Embedding后在骨干网络中的隐状态维度。通道独立(channel-independent)是近年网络的一类处理方法,表现为将多变量序列拆分多个单变量序列,共享同一个网络,深度学习模型对单变量序列输入产生对应的单变量输出序列。最近相关工作(例如,Nie 等人,2022;Zeng等人,2023)表明,通道独立的模型设计优于通道混合模型。
通道独立的设计在 Embedding 阶段做法为,每个输入的 token 只包含来自单个变量(通道)的信息。与通道独立对应的概念是通道混合,每个输入 token 含有来自多个变量的信息。下图简单对比了通道独立以及通道混合的时序 Embedding 方法,二者差异最明显之处在于一个 token 构成来自多个变量还是单个变量:

假设原始序列的长度为 T,变量数为 M,目标嵌入特征维度为 D;
上图左半部分是通道混合处理方法,输入数据形状为(𝑀, 𝑇),每个时点上 M 个变量的取值被视为一个 token,Embedding 步骤后,数据形状变为(𝐷, 𝑇);
右图是本篇报告涉及模型的通道独立处理方法,输入数据形状为(𝑀, 𝑇),经过 Patch 处理后,新序列长度为 N,每个变量的每个子序列被视为一个 token 进行映射,因此 Embedding步骤后数据形状为(𝑀,𝐷, 𝑁)。

在通道独立下,多变量序列被拆分为多条“单变量”序列并输入共同的骨干网络(backbone)中,骨干网络学习时序、特征、通道(变量)间的依赖关系。每条“单变量”序列输入骨干网络后产生对应预测输出,在骨干网络输出保留了一个通道维度(如图(4)所示)。在下面的章节,我们继续介绍不同骨干网络如何实现上述的信息提取流程。
(二)PatchTST
PatchTST 由 Nie 等 2022 年提出,是一种基于 Transformer 的时序模型,它将同样基于Transformer 的视觉模型 ViT 的思想运用在了时序类数据上。
1、Transformer
Transformers 在论文 Vaswani, Ashish, et al. "Attention Is All You Need."中首次提出,首先被广泛应用于 NLP 任务,近年模型的核心之一是自注意力机制(Self-Attention),它通过自注意力机制使序列中的任何部分进行交互,从而有效地捕获长距离依赖关系。

关于 Transformer 中涉及的自注意力机制的原理此处不再赘述。
若我们希望将 Transformer 用于时序任务,最为简单的流程是将每一天的 M 个变量作为一个 token 进行 Embedding(即通道混合),使用 encoder 部分的自注意力机制进行时序信息提取,最后取整个序列的表征,输入下游任务的预测头得到最终输出。
2、PatchTST
PatchTST 采用了 Patch、通道独立的设计,整体流程如下图所示:

经过 Patch Embedding 后,PatchTST 模型将多变量序列中的每一个序列看作一个独立样本,将单变量序列输入模型 backbone(Transformer encoder)中,通过注意力机制学习时序的依赖关系,最后拼接不同变量的输出。
以一个多变量时序预测任务为例,假设输入序列变量数为 M,输入每个变量过去 L 天的数据、目标为预测每个变量未来 T 日,模型对一个输入的样本的处理流程如图(6)所示;从一个 batch 数据形状的角度看,输入数据形状为(𝐵, 𝑀, 𝐿),其中 B 为 batch 大小,M 为变量数,L 为原始序列长度;patch embedding 后数据形状变为 (𝐵, 𝑀,𝐷, 𝑁),其中 N 为新序列长度,D 为每个 token 的嵌入特征维度;在进入模型 backbone 之前,PatchTST 模型将 B、M 维度合并,数据形状变为 (𝐵𝑀,𝐷, 𝑁),表示将每个变量视为一个单独的样本,一个 batch 中的样本数量变为 (𝐵𝑀) ,encoder 接受单变量输入,输出形状同样为(𝐵𝑀,𝐷, 𝑁),经过预测头、拼接合并后得到预测输出形状为(𝐵, 𝑀, 𝑇),即得到了每个输入样本的多变量预测结果。
(三)TSMixer
在上文的 PatchTST 中,模型将一个多变量时间序列视为多个独立的单变量时间序列,缺少考虑不同通道(变量)之间的交互作用。在后续的工作中,一种常见的流程是保留通道独立的同时,在骨干网络中加入通道交互模块,让模型进行预测时能考虑到不同变量之间的交互信息,更符合直觉。TSMixer 由 Ekambaram 等于 2023 年提出,通过基于 MLP的模块完成时序、特征、通道间的交互信息提取。
1、门控注意力
TSMixer 作者在 MLP 块后添加了一个简单的门控注意力(Bahdanau 等,2014)加强 MLP信息抽取能力,它比自注意力机制简单,起到特征加权的作用。

上图为 TSMixer 中的门控注意力流程图,其中 b、c、n、hf 分别表示 batchsize、通道、序列长度、嵌入维度;TSMixer 的门控注意力使用一个 Linear+Softmax 获取权重矩阵,类似自注意力机制 Query、Key 的操作;最后权重矩阵对初始的输入特征进行放缩,整个门控注意力的实现只基于 MLP。
2、TSMixer Backbone
TSMixer 同样先对数据进行 patch embedding,骨干网络由时序信息提取模块、特征信息提取模块、通道信息提取三个模块组成,三个模块则均由 MLP、门控注意力、残差连接构成,通过调整输入 MLP 层的数据形状实现不同类型的信息抽取。TSMixer 同样使用了Patch+通道独立的设计,相比于 PatchTST,它的骨干网络包含了通道信息交互提取。

(四)ModernTCN
ModernTCN 在骨干网络中同样包含时序、特征、通道的信息提取模块,流程同 TSMixer类似,区别在于各个模块采用了卷积网络实现。
在 Patch Embedding 步骤,ModernTCN 与上述模型略有不同,它采用 1D 卷积实现,kernel size 对应 Patch 的窗口大小 P,stride 对应为 Patch 的步长 S,输出通道数对应目标嵌入维度 D。
对一条原始时序样本输入:

其中,M 为变量维度,L 为时间维度,经过上述 1D 卷积处理后,得到输出为:

其中,M 是变量维度,D 为特征维度,N 为 patch 后新的时序维度。
1D 卷积得到了和 PatchTST、TSMixer 滑动窗口截取+映射方法相同的数据形状;经过Patch 处理后,时序数据进入 ModernTCN 骨干网络中,下面我们首先简要介绍其中所用的相关卷积技术。
1、分组卷积
自 AlexNet 在 2012 年赢得 ImageNet 比赛后,更大、更深的神经网络逐渐成为研究主流。
虽然模型深度对于提高性能有重要影响已经成为了共识,但这些更大更复杂模型始终不可避免需要面对一个现实应用的问题——如何在计算资源有限的硬件平台上执行算法。
分组卷积技术提供了一种可行的方案以缓解上述问题,它在不显著影响准确性的同时,减少了计算成本和参数数量。
传统 CNN 中,若卷积层将输入数据的通道数从𝑐1转为𝑐2,需要𝑐2个卷积核(每个卷积核通道数为𝑐1)如下图(a)所示;分组卷积将输入的特征图和卷积核进行分组,每组的卷积核仅与本组内的通道进行卷积计算,如下图(b)所示;
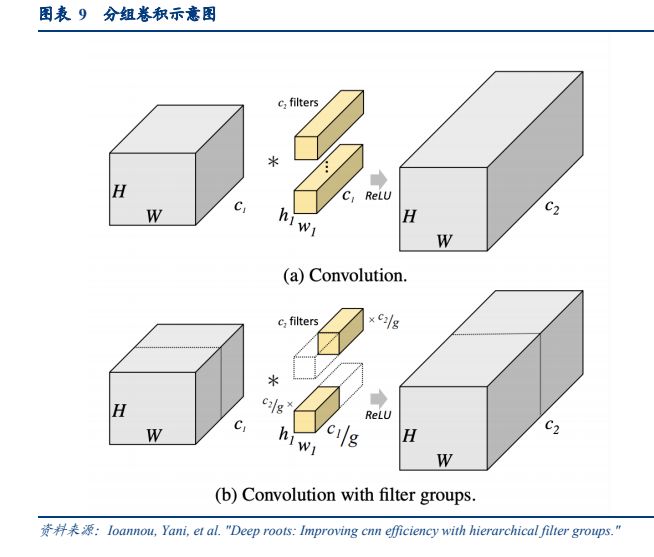
假设我们输入数据的通道数从𝑐1转为𝑐2:
在传统 CNN 下,可以看作每一个输入通道对应𝑐2/𝑐1个卷积核(每个卷积核的通道数为𝑐1);
在分组卷积下,定义一个分组数量𝑔,将输入的𝑐1个通道分为𝑔组(每组通道数量为𝑐1/𝑔),每一组对应𝑐2/𝑔个卷积核(每个卷积核的通道数为𝑐1/𝑔)。
假设卷积核长宽均为𝑘,不使用分组卷积时,参数量为:

使用分组卷积后,卷积核的参数数量为:

由此可见,分组卷积显著减少模型的参数量和计算量。
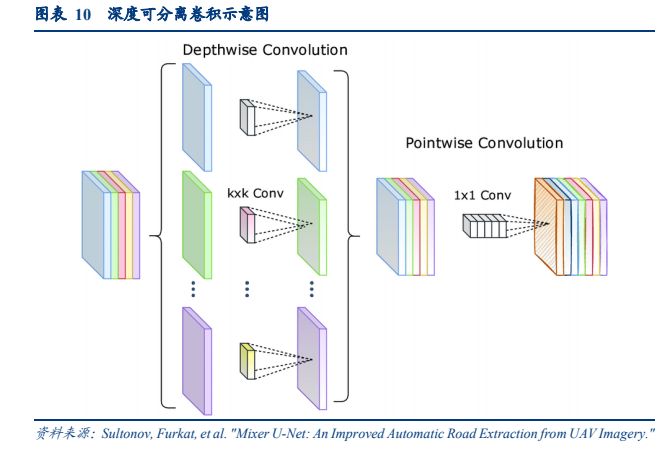
2、深度可分离卷积深度可分离卷积(Depthwise Separable Convolution)最早由 Sifre 提出,在 MobileNets 和Xception 等模型中有应用。深度可分离卷积对图像的空间特征、通道特征进行单独、分步的学习,它将标准的卷积核分解为两步:深度卷积(Depthwise Convolution)和点卷积(Pointwise Convolution):
深度卷积对每个输入通道单独对应一个卷积核(每个卷积核的通道数为 1),可以看作分组卷积的一种形式(分组数等于输入数据的通道数),一个通道数为 c 的输入数据经过深度卷积后,输入数据的通道数同样为 c;
在上一步的深度卷积中,相当于对每个通道进行了单独学习,没有考虑不同通道之间的交互;深度可分离卷积的第二步为点卷积,采用了 1×1 的卷积,组合不同通道得到最终输出。
3、ModernTCN Backbone ModernTCN 的 Backbone 由 DWConv、ConvFFN 两个子模块组成,通过残差连接层数堆叠,如下图所示:

在之前的部分我们简单介绍了深度可分离卷积,它由深度卷积(Depthwise,简写为 DW卷积)和点卷积(Pointwise,简写为 PW 卷积)两步组成,深度可分离卷积的特点是将图像的空间信息、通道信息抽取单独处理。
经过 ModernTCN 的 Patch 处理后,一个样本的形状为(𝑀,𝐷, 𝑁),其中 M 为变量维度、D 为 Embedding 后的特征维度,N 为序列维度。进行卷积操作前需要将 M 和 D 维度合并为通道维度,变为(𝑀 × 𝐷, 𝑁)。
ModernTCN 也用了其解耦的方案,将变量/特征的时序信息学习、通道交互两个步骤用单独的模块进行处理。
DWConv 模块实现了深度可分离卷积中的第一步——深度卷积,深度卷积不提取通道之间的交互,输入通道数量等于输出通道数量(𝑀 × 𝐷)。在时间序列的语境下,它表示对每个变量进行了时序信息提取。
接下来,类似深度可分离卷积的第二步的点卷积,后续的两个 ConvFFN 模块(按顺序记为 ConvFFN1、ConvFFN2)被设计用于对不同通道维度的信息进行学习。
ConvFFN 模块由两个1 × 1点卷积(PWConv)构成,如下图所示。

点卷积采用了分组卷积技术,两个 ConvFFN 采用不同的分组逻辑:
ConvFFN1 分组数设置为 M,此时分组点卷积表示学习同一个变量的特征交互; ConvFFN2 分组数设置为 D,此时分组点卷积表示学习同一特征维度不同变量的交互。
经过 2 个 ConvFFN 后,通过残差连接便得到一个 Block 的输出结果。
此外,ModernTCN 还在 DWConv 中采用了大核卷积技术,在此不再展开。
(五)小结上
文我们介绍了 PatchTST、TSMixer、ModernTCN 时序深度学习模型,它们的大致流程相似,如下图所示;

三个模型都采用了通道独立的设计,通过骨干网络学习时间、特征以及通道的交互。下面我们以常见的通道混合设计的 GRU 和 ModernTCN 为例,简单对比两种思路的区别:以一只股票的 5 天价格序列为例,它的变量为高、开、低、收,我们将其嵌入为 D 维向量。
对 GRU 网络(下图左),在 Embedding 阶段,将每一天的高、开、低、收作为一个token,输入模型的每个样本为长度为 5 的 token 序列;每个 token 的维度为 4,我们将其映射到更高的维度得到 D 维特征表征,通过后续的 GRU 网络学习不同时点的信息交互;
对 ModernTCN 网络(下图右),在 Embedding 阶段,用大小为 P 的窗口在每个变量时序上进行滑动截取,得到 4 条长度为 N 的新序列,每个窗口中 P 个时点的数值被视为一个 token,将 token 映射到 D 维后输入骨干网络,骨干网络根据单变量序列输入产生对应输出,最后将每个单变量的输出拼接还原为多变量序列,骨干网络对时序、嵌入隐状态、不同变量间的交互进行了学习。
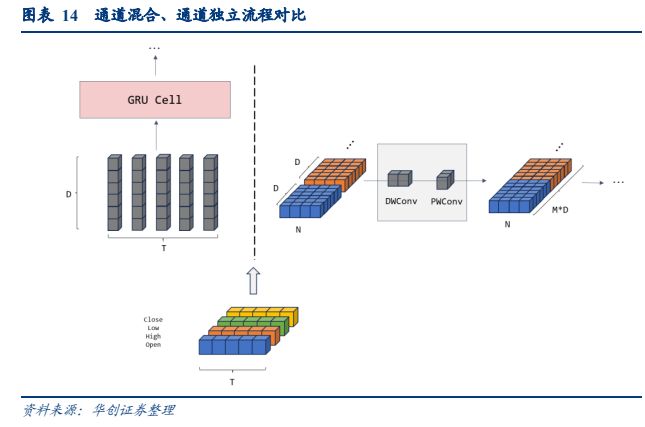
如何实现骨干网络中的时序信息交互、变量/特征信息,PatchTST、TSMixer、ModernTCN分别使用基于多头自注意力、门控 MLP、卷积的模块设计。
我们认为,Patch Embedding、骨干网络的解耦思路具有一定参考意义;从股价或因子类时序数据的特点看,Patch +通道独立的方法或是通道混合的方式,二者均有合理之处,通道混合时表征了每天的蜡烛图,通道独立时表征了单个变量的局部时间特征,无法直接得出孰优孰劣的结论。在后文,我们在上述三个模型的基础上再加入通道混合的Transformer 进行对比,检验上述模型在端到端量价因子挖掘任务中的表现。
三、量价因子挖掘测试
(一)数据集介绍数
据集说明:2007-2024 年 2 月 2 日 A 股日频量价数据,包括高、开、低、收、均价、成交量 6 个序列,我们以每周的最后一个交易日𝑡为截面,回溯截面上𝑁𝑡个股票过去 30 个交易日的数据,作为一个截面(对应𝑁𝑡个标签),以此滚动生成数据截面(𝑁1,30,6)、(𝑁2,30,6)…
(𝑁𝑡,30,6),在第一个维度上进行拼接得到全部训练数据。
同时,我们在周度截面股票进行如下排除:
1、剔除上市不满 120 天的股票;
2、剔除流通市值最小的 10%的股票;
3、剔除有数据缺失的股票。
模型训练参数说明:
训练集划分:按年滚动训练,年底进行重训练;在每年年底回溯过去 11 年作为训练集与验证集(其中最近的一年为验证集),次年为测试集;第一期模型的训练集为 2007.01-2016.12,验证集为 2017.01-2017.12,测试集为 2018.01-2018.12,以此类推,如下图所示:

--- 报告摘录结束 更多内容请阅读报告原文 ---
报告合集专题一览 X 由【报告派】定期整理更新
(特别说明:本文来源于公开资料,摘录内容仅供参考,不构成任何投资建议,如需使用请参阅报告原文。)
精选报告来源:报告派科技 / 电子 / 半导体 /
人工智能 | Ai产业 | Ai芯片 | 智能家居 | 智能音箱 | 智能语音 | 智能家电 | 智能照明 | 智能马桶 | 智能终端 | 智能门锁 | 智能手机 | 可穿戴设备 |半导体 | 芯片产业 | 第三代半导体 | 蓝牙 | 晶圆 | 功率半导体 | 5G | GA射频 | IGBT | SIC GA | SIC GAN | 分立器件 | 化合物 | 晶圆 | 封装封测 | 显示器 | LED | OLED | LED封装 | LED芯片 | LED照明 | 柔性折叠屏 | 电子元器件 | 光电子 | 消费电子 | 电子FPC | 电路板 | 集成电路 | 元宇宙 | 区块链 | NFT数字藏品 | 虚拟货币 | 比特币 | 数字货币 | 资产管理 | 保险行业 | 保险科技 | 财产保险 |
