在信息爆炸的大数据时代,我们每天都被无数的数据包围。如何在这茫茫的数字海洋中迅速找到自己所需的信息?传统的搜索方式或许已经无法满足我们的需求。此时,一种名为“爬虫”的技术逐渐崭露头角,成为了大数据时代中不可或缺的利器。
下面举个小例子讲讲爬虫可以做什么?以Python工具爬取王者荣耀官网的英雄人物头像为例,将网页上的图片爬取并保存,Python爬虫爬取网页图片可以分为四步:明确目的、发送请求、数据解析、保存数据,具体实例操作如下。
1.爬虫案例1.1 明确目的
打开王者荣耀英雄介绍主页,该主页包含很多种英雄的头像图片,主页网址链接如下。
官网地址:https://pvp.qq.com/web201605/herolist.shtml

1.2 发送请求
使用requests库发送请求,返回状态码显示为200,服务器连接正常。
import requestsu='https://pvp.qq.com/web201605/herolist.shtml'response=requests.get(u)print('状态码:{}'.format(response.status_code))if response.status_code != 200: passelse: print("服务器连接正常")
1.3 数据解析
在数据解析之前,需要提前安装pyquery,pyquery库类似于Beautiful Soup库,初始化的时候,需要传入HTML文本来初始化一个PyQuery对象,它的初始化方式包括直接传入字符串,传入URL,传入文件名等等,这里传入URL,并且查找节点。
#解析数据from pyquery import PyQuerydoc=PyQuery(html)items=doc('.herolist>li')#.items()print(items)
同时遍历,使用find函数查找子节点,遍历爬取图片URL和图片名。
for item in items: url=item.find('img').attr('src') #print(url) urls='http:'+url name=item.find('a').text() #print(name) url_content=requests.get(urls).content1.4 保存数据
最后保存数据,需要提前新建一个文件夹用于数据存储,同时,存储数据的代码需要写在for循环里面,不然只会保存一张图片。
with open('C:/Users/尚天强/Desktop/王者荣耀picture/'+name+'.jpg','wb') as file: file.write(url_content) print("正在下载%s......%s"%(name,urls))同时加一个计时器,用于计时图片爬取的时长,这里显示图片爬取共计耗时7.03秒。
import timestart=time.time()…end=time.time()print('图片爬取共计耗时{:.2f}秒'.format(end-start))
爬取过程动态演示如下,运行过程很快。
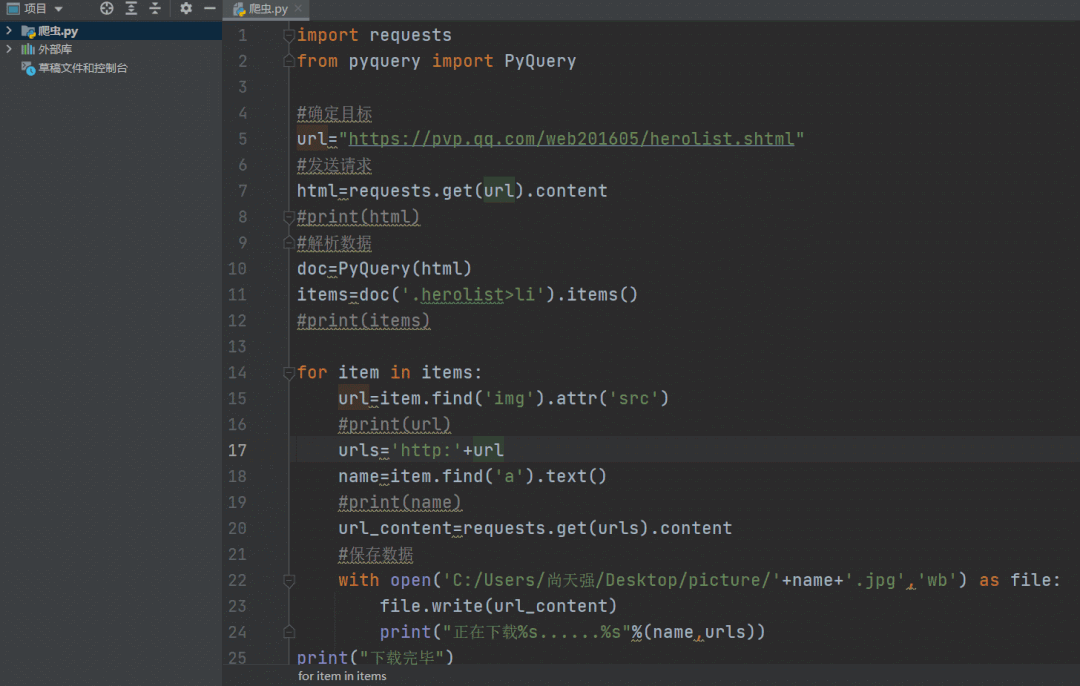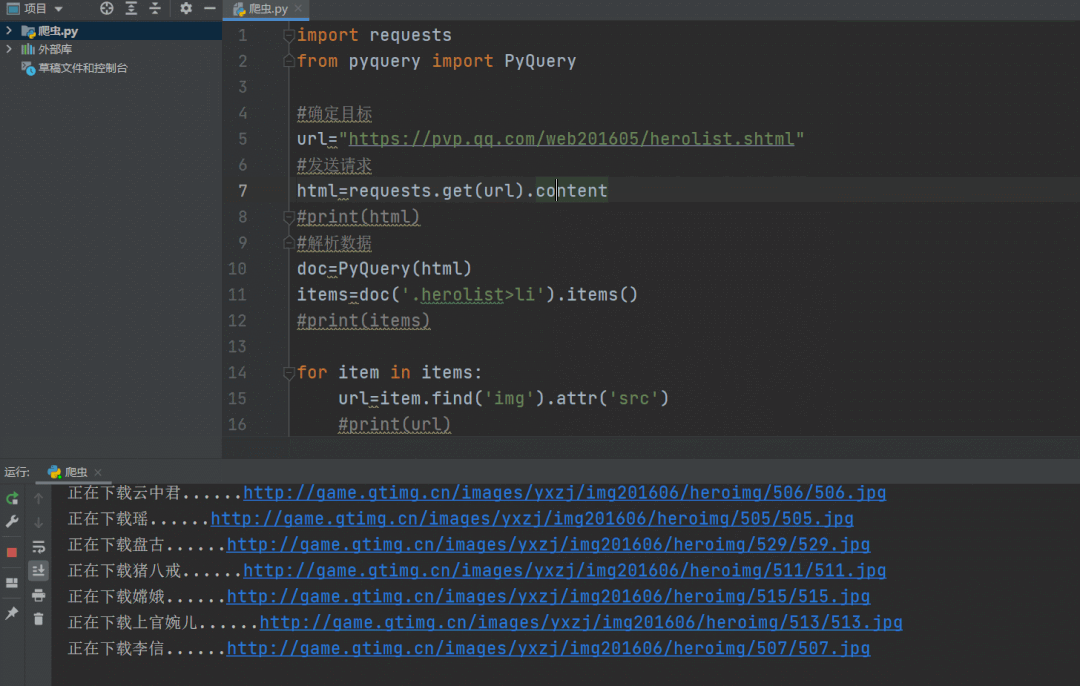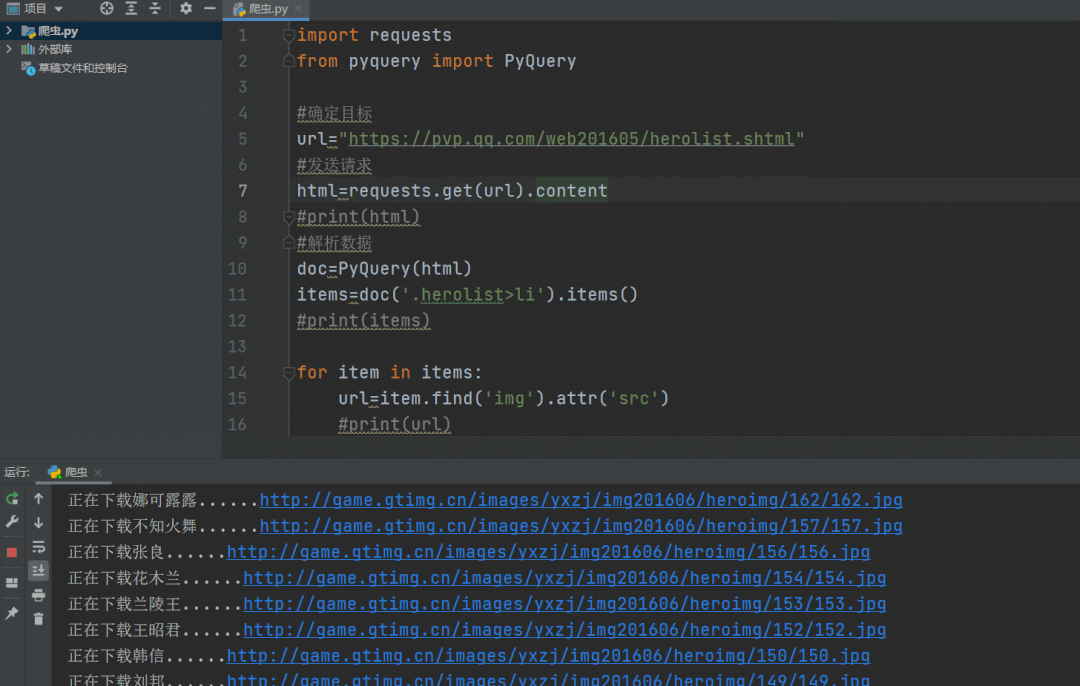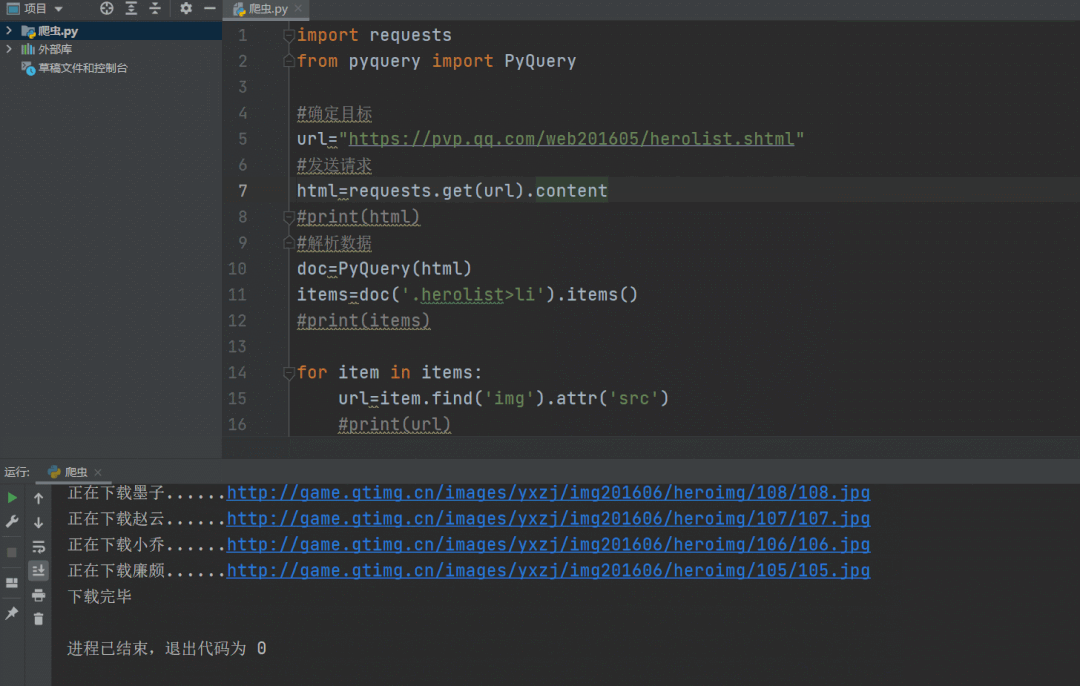
以上我们成功将王者荣耀的英雄人物头像爬取下来,代码文件中有高清头像。
 Bright Data
Bright Data爬虫,这个看似高深莫测的词汇,实则却是我们应对大数据挑战的得力助手。在这个数据无限增长的时代,爬虫为我们开辟了一条快速、高效获取信息的道路,上面的实例需要编程基础,这里给大家介绍使用Bright Data无编程爬取数据。
2.1 Bright Data 注册
要使用Bright Data的功能,首先我们要在其官网注册,使用个人邮箱即可注册,注册完成后的界面如下所示。
官网地址:https://get.brightdata.com/dhsjfx

2.2 主要功能
登录官网后,可以看到在主界面中已经展示了常用的功能:代理&爬虫基础设施与数据集和Web Scraper IDE,分别介绍其功能。
代理&爬虫基础设施:最快且稳定的代理网络,静态动态IP覆盖全球195个国家,告别反爬限制和封锁。包括:
代理网络:动态住宅,静态住宅ISP,机房代理和移动代理。亮网络解锁器:全方位自动解锁试用SERP API轻松解锁搜索引擎结果数据集和Web Scraper IDE:不管是完整丰富的大数据集,还是大规模轻松开发数据挖掘抓取工具,都能在此找到。包括:
数据集订制数据集Web scraper IDE/网页爬虫IDE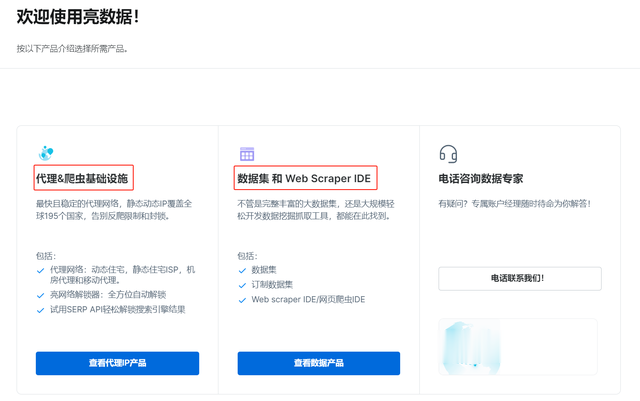
2.3 代理&爬虫基础设施
在进行网络爬虫工作时,许多网站会采取一些措施来限制或阻止来自特定 IP 地址的访问。这主要是为了防止过度抓取和保护网站数据的隐私。因此,如果你使用的是固定的 IP 地址进行爬虫操作,很可能会遇到访问受限的问题。
为了避免该情况,许多爬虫开发者选择使用代理 IP。代理 IP 是一种隐藏真实 IP 地址的方法,通过代理服务器进行数据传输。当你使用代理 IP 进行爬虫操作时,网站服务器接收到的请求会显示为代理服务器的 IP 地址,而不是你的真实 IP,Bright Data含有多种代理IP功能。
使用代理 IP 的好处在于,你可以更换不同的代理 IP 来访问目标网站,这样即使某个代理 IP 被限制或封禁,你仍然可以通过其他可用的代理 IP 继续进行爬虫操作。此外,使用真实的代理 IP 还可以帮助你更好地模拟真实用户的访问行为,提高爬虫的效率和成功率。

2.4 数据集和Web Scraper IDE
在数据科学和机器学习的世界里,一个庞大的数据集是必不可少的。有时候,为了获得所需的数据,我们需要从网站上抓取信息。而这个过程,虽然必要,但往往也是耗时和复杂的。幸运的是,一些平台和工具已经为我们提供了方便的解决方案。
在Web Scraper IDE中,官方为我们提供了许多知名站点的爬取数据。这意味着,你不需要从零开始,手动地抓取每一个网站。你可以直接使用这些已经爬好的数据集,节省大量的时间和精力。

这些数据集通常覆盖了各种领域,从社交媒体、新闻网站到电子商务平台等。无论你是在进行市场分析、内容生成还是模式识别,都可以在这些数据集中找到你需要的数据。
更令人兴奋的是,这些数据集的质量都是经过严格筛选和清洗的,确保了数据的准确性和完整性。你可以放心地使用这些数据,而无需担心数据的缺失或错误。

使用Web Scraper IDE提供的数据集,可以大大简化数据抓取的过程,使你能够更快地进入数据分析的核心工作。如果你需要快速获取高质量的数据,那么这些官方提供的数据集无疑是你的最佳选择。
2.5 Web Scraper IDE
Bright Data还提供了 web 端的 IDE 工具,并提供了相关的示例代码,你可以直接使用模板和对应的代码!也可以自己自定义爬虫,可以按照你的需求来定制数据集,点击制定按钮即可进入自定义数据集的界面。

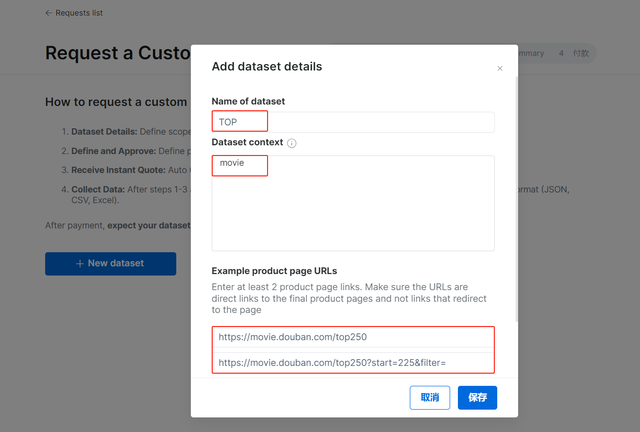
这里以爬取豆瓣电影TOP250的数据为例,按照提示的要求填入对应的信息,填写示例的URL时,需要填写至少两条URL的链接,这样才能爬取数据。
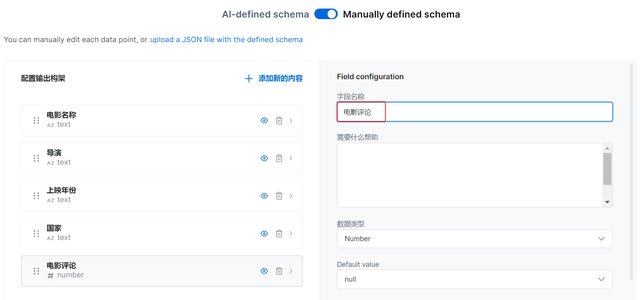
接着,对于网页返回的字段可以编辑字段名称、数据类型等,限于爬取的数据信息,并且,返回的数据字段可以做预览,提前查看爬取的数据结果。
数据字段设置好后,就可以点击下载按钮将数据下来下来,这里有JSON和CSV两种数据保存格式,通过预览我们就可以看到爬取的基本数据信息,使用自定义爬取数据也很简单。

借助爬虫,我们可以轻松抓取和整理数据,无论你是需要大规模收集数据,还是需要突破网站封锁,或需要管理你的代理,Bright Data都能为你提供优质的服务,如果你想学习Bright Data更多数据爬取功能,点击阅读原文,申请还可以免费试用,开启你的爬虫之旅!
