一次项目包含非常多的流程,有需求拆解,业务建模,项目管理,风险识别,代码模块设计等等,如果我们在每次项目中,都将精力大量放在这些过程的思考上面,那我们剩余的,放在业务上思考的精力和时间就会大大减少;这也是为什么我们要 总结经验/方法论/范式 的原因;这篇文章旨在建立代码模块设计上的思路,给出了两种非常常用的设计范式,减少未来在这一块的精力开销。
一、领域模型驱动的代码范式
领域模型驱动的代码范式,是围绕着领域知识设计的,需要先理解业务模型,再将业务模型映射到软件的对象模型中来;本章节重点在我们有了业务模型之后的代码模式,具体业务模型如何构建在《》中有详细讨论;
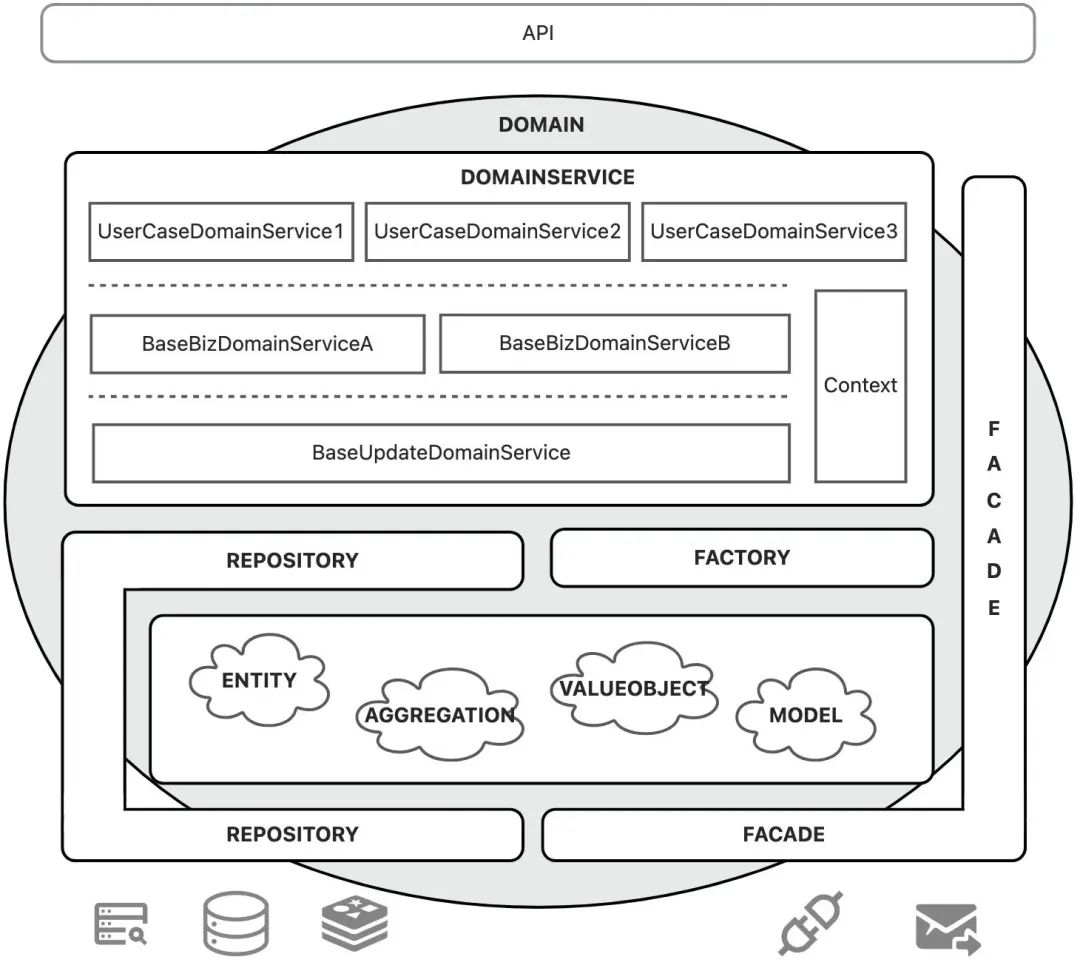
上图中间就是该模式最重要的领域,领域层代码作为系统的最核心资产模块,可以被打包迁移到任何应用上,而不关心具体的三方服务提供方和具体的持久化方案,即外部服务的变化对领域层代码是没有任何侵入的;
从上图来看,领域对象(ENTITY、AGGREGATION、VALUEOBJECT、MODEL)用于描述业务模型,是业务关系最重要的体现;为了屏蔽持久化方案的细节,我们使用仓库(REPOSITORY)来查询和持久化领域对象;有的时候我们期望直接获取到一个非空的领域对象,而不关心这个对象从哪里来,如何构造,那我们就需要工厂(FACTORY)来帮我们生产这个对象;当领域内依赖外部服务能力时,需要门面(FACADE)帮助我们屏蔽具体的服务提供方;
有了以上这些模型对象和基础能力模块,我们需要领域服务(DomainServie)层作为“上帝之手”帮我们编排具体的业务逻辑;本章对领域服务有更细的三层划分,第一层是实体操作服务(BaseUpdateDomainService),用于收敛操作实体/聚合的真实变更行为;第二层是业务流程服务(BaseBizDomainService),用于收敛基础的有业务语义的行为;第三层是用例领域服务(UserCaseDomainService),用于映射具体的业务需求用例场景。
1.1 领域模型对象
实体
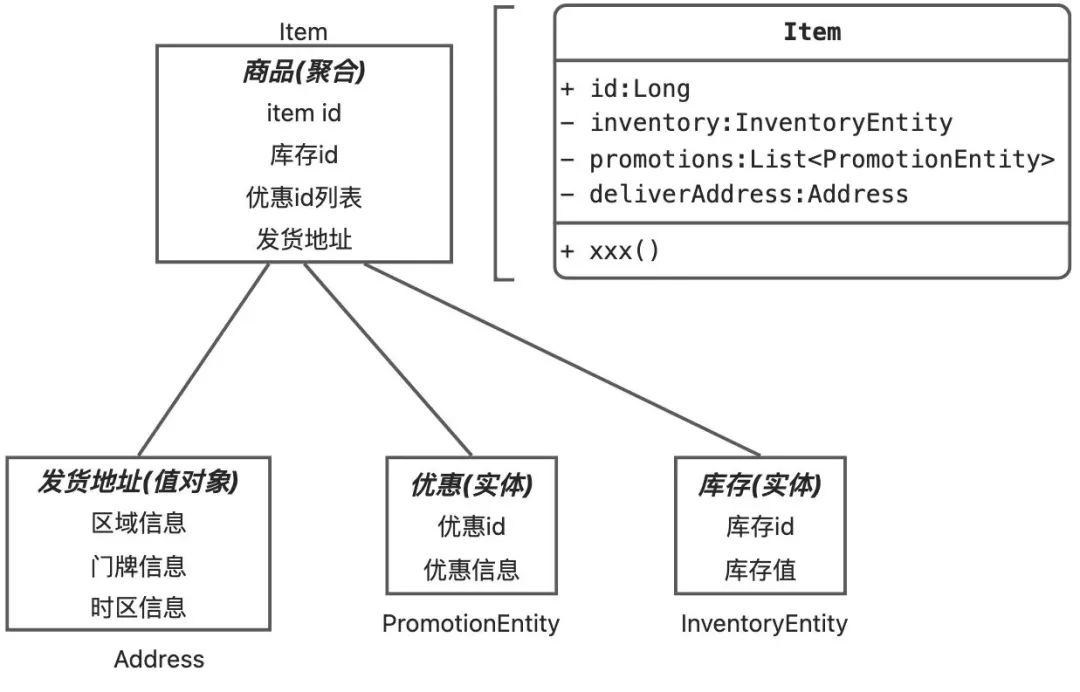
由标识定义,而不依赖它的所有属性和职责,并在整个生命周期中有连续性。这句话在初看的时候非常晦涩,简单来说,就是一个标识没变的对象,在其他自身属性发生变化后,它依然是它,那么它就是实体;以上图为例,一个商品的商品id没变,即使它的标题改了,图片改了,优惠信息变了,它发生了翻天覆地的变化,但它依然是它,它有唯一的标识来表明它还是它,只是一些属性发生了变化;通过这种方式来识别实体的目的,是因为领域中的关键对象,通常并不由它们的属性定义,而是由可见的/不可见的标识来定义,且有完整的生命周期,在这个周期内它如何变化,它都依然是它;通过这种方式识别出实体这种领域关键对象,也是领域驱动设计和数据驱动设计最大的差别,数据驱动设计是先识别出我们需要哪些数据表,然后将这些数据表映射为对象模型;而领域驱动设计是先通过业务模型识别出实体,再将实体映射为所需要的数据表。
值对象
用于描述领域的某个方面而本身没有唯一标识的对象。被实例化后用来表示一些设计元素,对于这些设计元素,我们只关心它们是什么,而不关心它们是谁。如上图举个例子,一个商品实体的发货地址Address对象有区域信息、门牌信息、时区信息这几个属性,其中的门牌号从111修改成222后,它就已经不再是修改前的那个它了,因为门牌号222并不等于门牌号111的地址。即它是没有生命周期的,它的equals方法由它的属性值决定(实体的equals方法由唯一标识决定);
聚合
聚合是一组实体和值对象的组合;内部包含一个聚合根,和由聚合根关联起来的实体和值对象;以上图为例,有商品、优惠、库存这三个实体和地址这一个值对象,对于一个商品而言,完整的商品信息需要包含优惠、库存、地址这些信息,那么在商品模型中,商品就是聚合根,其内部通过优惠id关联它的优惠信息,通过库存id关联商品的库存信息;聚合将这组关联关系建立,对外提供统一的操作,比如需要删除某个商品,那么这个聚合的内部可以在一个事务(或分布式事务)中,对库存进行清空,对优惠进行清理,最终对商品进行删除。
1.2 查询/构造能力
仓库
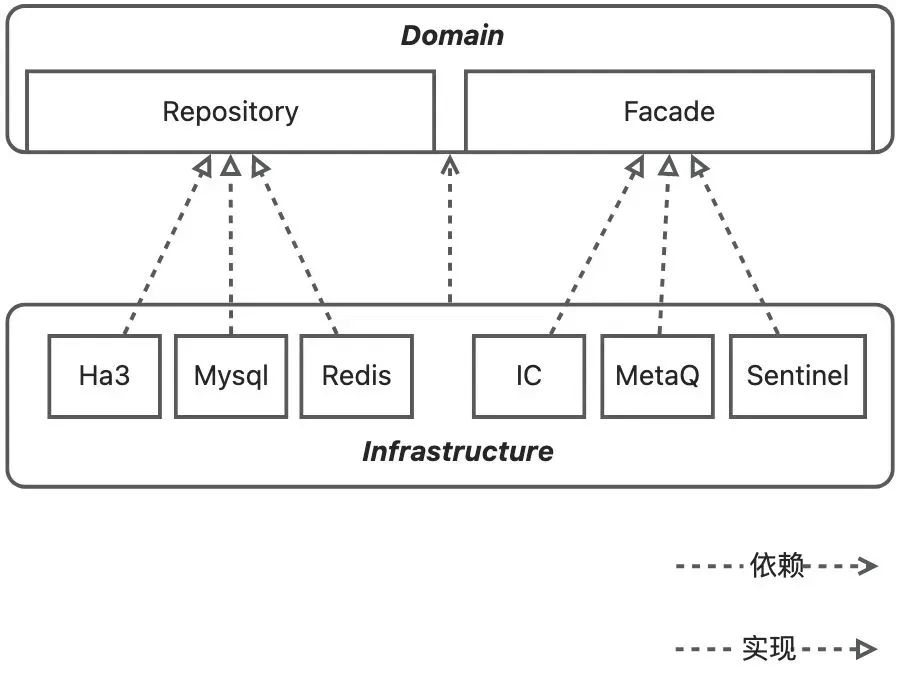
仓库是可持久化的领域对象和真实物理存储操作之间的媒介,随意的数据库查询会破坏领域对象的封装,所以需要抽象出仓库这种类型,它定义领域对象的获取和持久化方法,具体实现不由领域层感知;至于具体用了什么存储,如何写入和查询,是否使用缓存,这些逻辑统一封装在仓库的实现层,对于后续迁移存储、增删缓存,都可以做到不侵蚀业务领域。
比如整个领域模块需要打包给海外业务使用,在海外我们需要用当地的存储,那么这个迁移对于领域层是没有侵入的,只需要在基础设施层修改仓库的实现即可;
再比如我们的数据库存在性能瓶颈,需要在数据库上增加一层缓存,这个操作对领域也是没有侵入的,只需要在仓库的实现处,增加缓存的读写即可,对业务逻辑无感。
三方能力门面
门面用于封装第三方的能力,设计初衷本质和仓库是一样的,目的都是屏蔽具体的三方能力实现,让稳定的领域层不去依赖无法把控变化方向的第三方;上图中的三个case是比较经典的三个例子:
我们的模型中依赖外部查询获取的商品模型,这个模型中有商品标题、商品图片、店铺名称这几个信息,那么我们需要在Domain层定义一个商品类ItemInfo,包含这几个属性,然后在Domain层定义一个获取ItemInfo对象的服务接口,比如叫ItemFacade,方法是getItemInfo;接下来我们需要在Infrastructure层实现Domain层定义的这个接口,比如具体的实现是依赖Ic的接口,将ItemDO转换为Domain层的ItemInfo;可以发现,这样的设计让Domain对商品信息的获取源是无感的,当我们的能力需要部署到海外,或者IC某一天进行了重大改革,需要对模型进行大改,那么我们只需要重新实现Infrastructrue中ItemFacadeImpl即可。这个思想其实就是依赖倒置的思想,稳定不应该依赖变化,变化应该依赖稳定;因为第三方的变化方向是无法把控的,它的变化不应该侵入到我们的领域知识内部。
我们的领域还依赖一些消息发送、限流等基础功能,也需要在Domain层定义相应能力的Facade,在Infrastructure层实现,目的同上,将metaq替换成notify/swift时,领域层是无感的。
工厂
当创建一个实体对象或聚合的操作很复杂,甚至有很多领域内部的结构需要暴露的时候,就可以用工厂进行封装。一种相对简单粗暴的判断方法是看这个类的构造方法实现是否复杂,并且看着这些逻辑不应该由这个类实现,那么不妨用工厂来构造这个对象吧!
1.3 领域服务
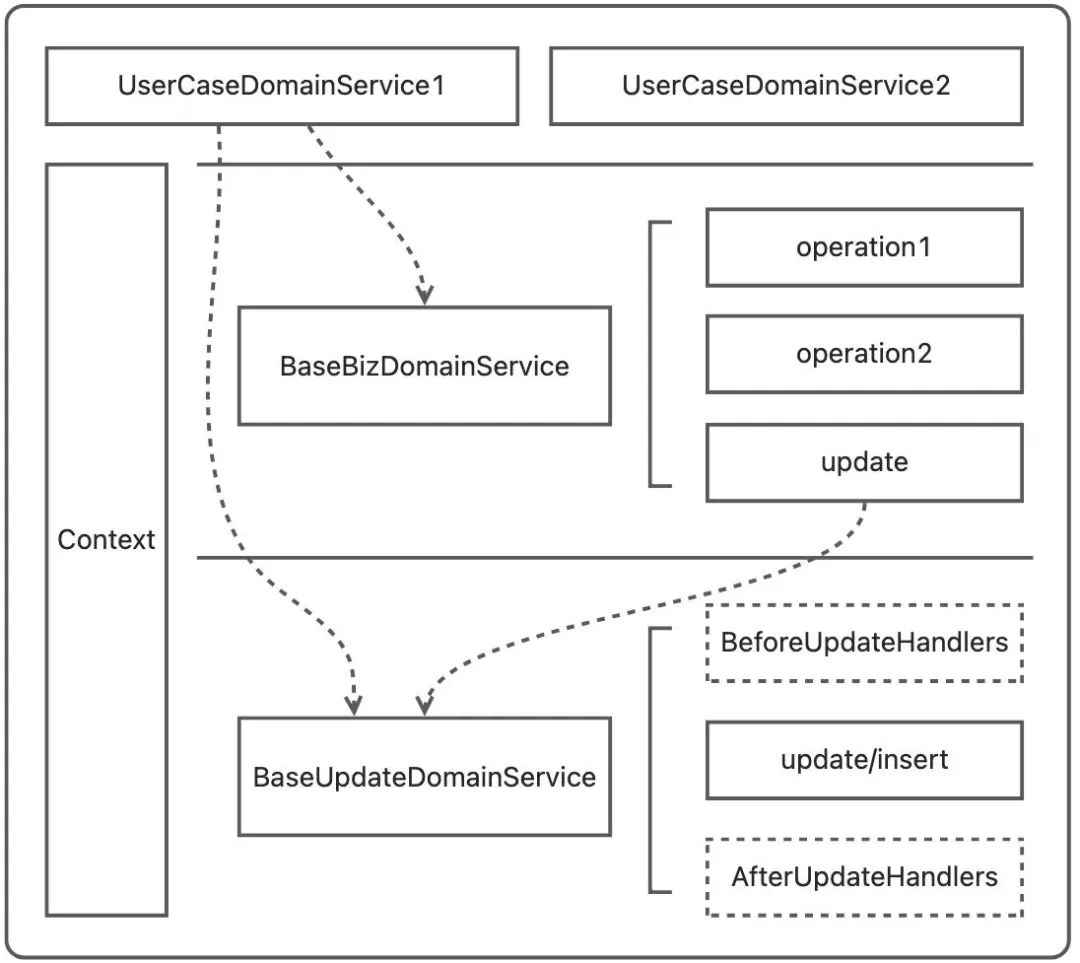
有一些对实体/聚合/值对象进行编排操作的概念并不适合被建模为对象,那么它应该被抽象为领域服务,化作一只上帝之手,做领域对象间流程操作的编排。服务很重要的特征,它的操作应该是无状态的。本文基于开发实践,对领域服务做了三层更细节的划分:
实体操作服务
即图中的BaseUpdateDomainService,是最基础的一类领域服务,用于收口某个实体的真实物理操作,它的流程中一般包含一个核心的update/insert操作,作用在写数据库上,依情况可以增加:
BeforeUpdateHandlers和AfterUpdateHandlers,用于更新前后的一些额外业务操作;
如1.1中的图,我们在内存中操作完某个库存实体对象,需要更新db的时候,可以调用它对应的服务,在这个服务中,我们除了将变更的值更新db,还需要对外发送消息,更新前也需要执行一些校验的回调,那么校验回调可以放在BeforeUpdateHandler中,对外的消息可以放在AfterUpdateHandler中;抽象出这样的一个服务,好处是可以收敛最基础的变更操作,不至于不同的入口对某个对象的更新,还会出现不一样的操作(比如需要发送更新消息,不同的入口操作更新,有的发送消息,有的不发送)。
一般每个实体都需要有一个对应的操作服务(或者模型极其简单可以省略这一层),操作服务可以依赖其他的操作服务,比如1.1中商品模型的更新,是需要依赖库存更新服务和优惠更新服务的。
业务流程服务
这一层的领域服务对应图中的BaseBizDomainService,用于收敛一些通用的业务流程,可以直接对接业务接口或者用于上层的用例编排;比如我们在商家请求、接到第三方消息、具体的某几个用例中,需要先查询ItemFacade,然后进行一些业务逻辑判断,然后根据情况对1.1商品模型中的优惠进行清理,那么就可以将这段逻辑收敛到“XX优惠清理领域服务”中,在多个上层场景需要进行该操作时,直接调用这个领域服务即可。
用例领域服务
这一层对应图中的UserCaseDomainService作为领域服务的最上层,也是最具体的一层,用于实现 定制的/不可复用的 用例场景业务逻辑,只直接对接对外的api。
1.4 包结构实践
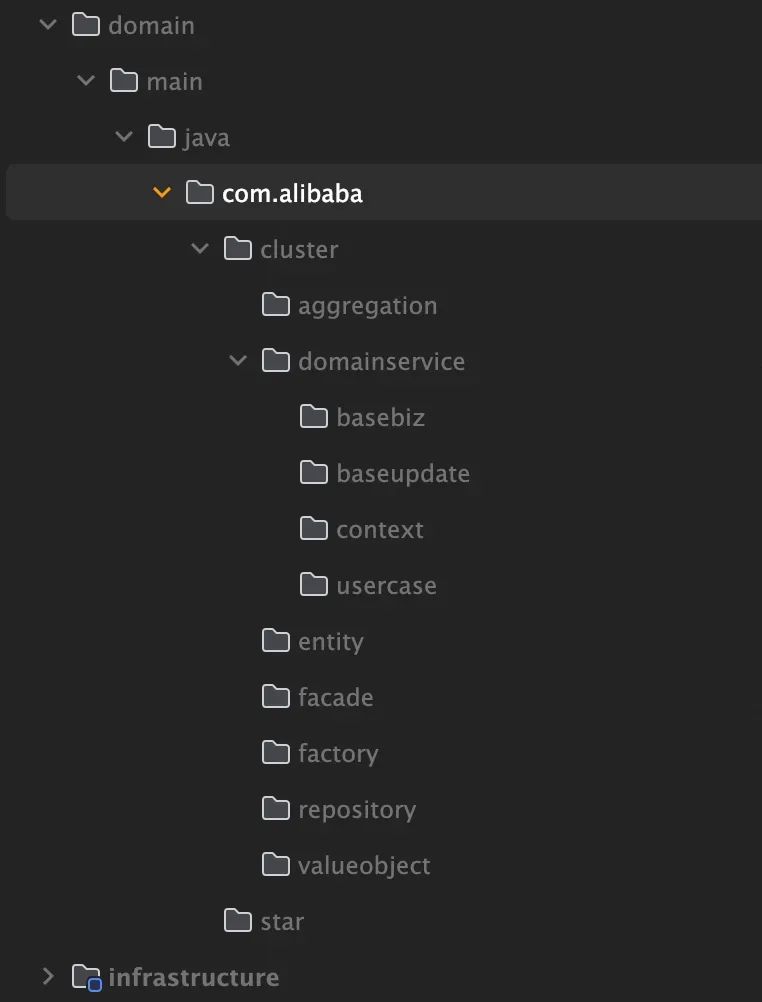
该包结构即描述了上述的所有模块,其中infrastructure模块依赖domain模块;domain模块的pom文件理论上不应该有任何三方依赖(除了一些工具类)。
二、过程驱动的代码范式
领域驱动的代码,重点是抽象领域模型,沉淀领域对象实体,它用模型间的关系以及模型直接的操作来沉淀知识;过程驱动的代码,重点是抽象能力,沉淀函数,并用编排引擎串联执行过程,实现对知识的描述。
在面向对象大张旗鼓的今天,大多数人对面向过程编程嗤之以鼻,但有些场景使用过程驱动的编程思路,反而能更好地描述业务规则以及业务流程,比如前台表达的渲染链路,或是章节一中 比较重的领域服务,使用过程驱动能更好地描述数据处理的过程以及产品用例流程。

上图能力库中的能力点是我们过程驱动最核心的部分,是我们对能力的抽象,一般一个能力只沉淀一个具体的原子方法,并决策流程是否能执行下去;往上是阶段划分,不同的能力在具体的业务流程中,是处于不同阶段的,这里的阶段划分是指从流程阶段的维度对能力点进行分类并放在不同的包中,让我们的流程更加清晰;再往上是不同场景下我们对能力点的执行链路编排,并对外做统一输出。
2.1 能力点
能力点通常由一个接口定义,入参是执行上下文,出参是流程是否需要继续。
public interface AbilityNode<C extends Context> { /** * 执行一个渲染节点 * @param context 执行上下文 * @return 是否还需要继续往下执行 */ boolean execute(C context);
基于这个接口,我们可以实现非常多原子能力节点。java中,这些能力节点作为bean由spring容器统一管理,运行时取出即用。
在一个业务场景下,我们的能力点往往会非常多,那么我们就需要对他们进行基于业务场景的阶段划分,并分门管理;比如我们在前台投放场的实践中,按照召回、补全、过滤、排序、渲染,划分了五个阶段,每一个能力点被归类到其中一个阶段中进行管理。
2.2 能力编排
有了能力点,我们需要基于编排引擎将这些能力串联起来,用以描述业务规则或是业务流程;这些能力执行的过程有些仅仅是可串行执行的,有些是也可以并行执行的,下面给出一套通用的流程协议以及实现过程:
public abstract class AbilityChain<C extends Context<?>> { @Resource private ThreadPool threadPool; public abstract C initContext(Request request); public Response execute(Request request) { //获取渲染上下文 C ctx; try { ctx = this.initContext(request); if (ctx == null || ctx.getOrder() == null || CollectionUtils.isEmpty(ctx.getOrder().getNodeNames())) { return null; } } catch (Throwable t) { log.error("{} catch an exception when getRenderContext, request={}, e=" , this.getClass().getName(), JSON.toJSONString(requestItem), t); return null; } try { //执行所有节点 for (List<String> nodes : ctx.getOrder().getNodeNames()) { List<AbilityNode<C>> renderNodes = renderNodeContainer.getAbilityNodes(nodes); boolean isContinue = true; if (renderNodes.size() > 1) { //并发执行多个节点 isContinue = this.concurrentExecute(renderNodes, ctx); } else if (renderNodes.size() == 1){ isContinue = this.serialExecute(renderNodes, ctx); } if (!isContinue) { break; } } return ctx.getResponse(); } catch (Throwable t) { log.error("RenderChain.execute catch an exception, e=", t); return null; } } /** * 并发执行多个node,如果不需要继续进行了则返回false,否则返回true */ private boolean concurrentExecute(List<AbilityNode<C>> nodes, C ctx) { if (CollectionUtils.isEmpty(nodes)) { return true; } long start = System.currentTimeMillis(); Set<Boolean> isContinue = Sets.newConcurrentHashSet(); List<Runnable> nodeFuncList = nodes.stream() .filter(Objects::nonNull) .map(node -> (Runnable)() -> isContinue.add(this.executePerNode(node, ctx))) .collect(Collectors.toList()); linkThreadPool.concurrentExecuteWaitFinish(nodeFuncList); //没有node认为不继续,就是要继续 return !isContinue.contains(false); } /** * 串行执行多个node,如果不需要继续进行了则返回false,否则返回true */ private boolean serialExecute(List<AbilityNode<C>> nodes, C ctx) { if (CollectionUtils.isEmpty(nodes)) { return true; } for (AbilityNode<C> node : nodes) { if (node == null) { continue; } boolean isContinue = this.executePerNode(node, ctx); if (!isContinue) { //不再继续执行了 return false; } } return true; } /** * 执行单个渲染节点 */ private boolean executePerNode(AbilityNode<C> node, C context) { if (node == null || context == null) { return false; } try { boolean isContinue = node.execute(context); if (!isContinue) { context.track("return false, stop render!"); } return isContinue; } catch (Throwable t) { log.error("{} catch an exception, e=", nodeClazz, t); throw t; } }}
其中流程协议为:
[ [ "Ability1" ], [ "Ability3", "Ability4", "Ability6" ], [ "Ability5" ]]
其中Ablitiy3 4 6表示需要并发执行,Ability1、3/4/6、5表示需要串行执行。
2.3 切面
有了能力点和流程编排引擎,基于过程编码的代码骨架就已经有了;但是往往我们还需要一些无法沉淀为能力的逻辑,需要在每个节点(或指定节点)执行前/后进行,这就需要切面的能力;
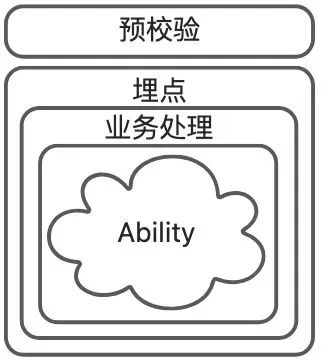
如图,比如流程埋点、预校验就非常适合放到切面这一层实现。下图是我们在实践中,基于切面实现的能力点追踪,可以清晰地看到每个能力点执行的过程以及数据变更情况。

2.4 包结构实践

该包结构即描述了上述的所有模块,chain目录下为多个业务场景流程,围绕着外层的AbilityNode和AbilityChain进行实现,编排出符合业务场景逻辑的流程。
总结
随着业务规模的增长,数据请求和并发访问量增大、静态文件高频变更,企业需要搭建一个高可用和共享存储的网站架构。
