
你有没有觉得,最近AI圈儿的新名词和技术突破,简直比翻书还快?
今天Transformer,明天Attention,后天又是啥新架构,听得人云里雾里。
有人甚至开始怀疑,这些所谓的“革命性突破”,是不是只是科学家们玩的文字游戏,普通人根本用不上?
别急着下结论。
这不,DeepSeek又带着新东西来了!
这次他们搞了个新的注意力架构,名字有点拗口,叫NSA。
更劲爆的是,DeepSeek的创始人梁文锋,这次也亲自挂名了!
这可不常见,大佬亲自下场,看来这NSA确实有点东西。
Attention不行了?
要说这NSA,就得先说说Attention(注意力机制)。
这玩意儿,咱们可以简单理解成AI的“眼睛”。

AI要处理信息,总得知道哪些信息是重要的,哪些是无关紧要的吧?
Attention就是帮AI把目光聚焦在关键信息上。
但是,传统的Attention有个问题,就是太“笨”了。
它就像一个啥都想看清楚的家伙,恨不得把所有信息都扫描一遍。
这在处理短文本的时候还好,但如果面对长篇大论,比如一篇文章、一本小说,或者一段代码,那计算量就大了去了,效率也变得很低。
想象一下,你让一个孩子背诵《道德经》,他要是每个字都仔仔细细地研究,那得背到猴年马月?
但如果他能抓住老子思想的核心,理解其中的精髓,背起来是不是就快多了?
所以,问题就来了,传统的Attention机制,在面对越来越长的“文本”时,已经有点力不从心了。
这也就催生了各种各样的“优化版”Attention,比如稀疏注意力、长程注意力等等。
DeepSeek这次搞的NSA,也是为了解决这个问题。
DeepSeek放大招!

那么,DeepSeek的NSA到底有什么特别之处呢?
简单来说,它主要做了两件事:
第一,硬件对齐。
啥意思呢?
就是让算法更好地适应硬件的特性。
你可以把算法想象成一个软件,硬件想象成一台电脑。
如果软件和硬件不匹配,那电脑运行起来肯定会卡顿。
DeepSeek的NSA,就是为了让AI的“眼睛”和“大脑”更好地协同工作。
第二,训练感知。
传统的稀疏注意力,往往只关注推理阶段的效率,忽略了训练阶段。
这就好比你只想着怎么提高考试成绩,却不重视平时的学习。
DeepSeek的NSA,则是在训练的时候就考虑到稀疏性,让AI在学习的过程中就学会“抓重点”。

具体来说,NSA是怎么做的呢?
它把信息分成了不同的层级,有点像金字塔。
最底层是细粒度的信息,就像一篇文章里的每个字;中间层是粗粒度的信息,就像每个段落;最顶层则是更高级的抽象概念,比如文章的主题。
NSA通过不同的“注意力路径”,来处理这些不同层级的信息。
这听起来有点复杂,咱们可以举个例子。
假设你要阅读一份财务报表,传统的Attention机制可能会让你逐行逐列地分析,眼睛都看花了。
而NSA则会先帮你快速扫描一遍,找出关键的财务指标,然后再重点分析这些指标相关的细节。
这样一来,效率是不是就大大提高了?
更关键的是,DeepSeek还对NSA进行了专门的硬件优化。
他们使用了一种叫做Triton的工具,可以更好地利用GPU的计算能力。
这就好比给AI的“眼睛”装上了涡轮增压,让它看得更快、更清晰。
NSA凭啥这么快?
说实话,现在AI圈儿里各种各样的“加速”技术,简直让人眼花缭乱。
但很多时候,这些技术都只是理论上的加速,实际应用效果并不理想。
DeepSeek的NSA,真的能像他们说的那样,实现“FlashAttention级别的加速”吗?
要回答这个问题,咱们得先了解一下FlashAttention。
这是一种非常流行的注意力加速技术,它通过优化内存访问,来减少计算时间。
你可以把FlashAttention想象成一个高效的快递员,它能以最快的速度把信息送到AI的“大脑”里。
DeepSeek的NSA,在某些方面,确实借鉴了FlashAttention的思想。
比如,他们也使用了分块式的内存访问模式,减少了冗余的数据传输。
但NSA也有自己的创新之处。
比如,他们针对稀疏注意力的特点,设计了专门的内核,可以更好地利用GPU的计算资源。
那么,NSA到底比FlashAttention快多少呢?

根据DeepSeek的实验数据,在处理64k上下文长度的文本时,NSA的前向加速可以达到9倍,反向加速可以达到6倍。
这个数字确实非常惊人。
当然,这只是实验室里的数据,实际应用中可能会有所不同。
但即便打个折扣,NSA的加速效果仍然非常可观。
这意味着,我们可以用更少的计算资源,处理更长的文本,训练更大的模型。
效果真有这么好?
光有速度还不够,AI的最终目标,还是要解决实际问题。
DeepSeek的NSA,在实际应用中表现如何呢?
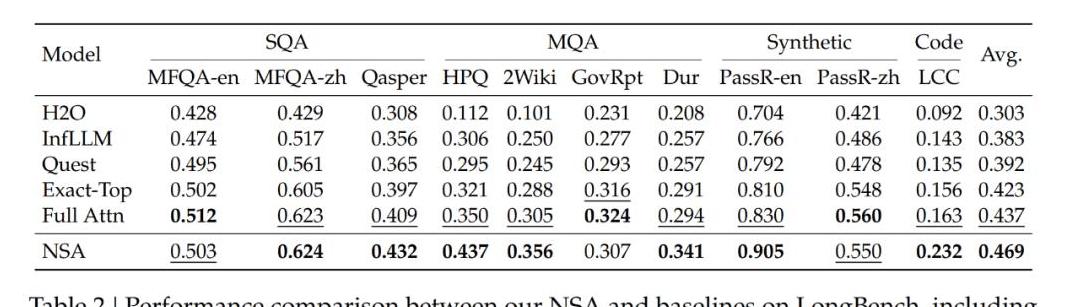
DeepSeek在各种不同的数据集上,对NSA进行了测试。
结果表明,NSA在很多任务上,都超过了传统的Attention机制,甚至超过了一些其他的稀疏注意力方法。
比如,在长文本理解方面,NSA可以在64k的上下文中,准确地找到目标信息。

这对于处理长篇文档、代码库等任务非常重要。
又比如,在思维链推理方面,NSA可以更好地捕捉长距离的逻辑依赖关系,提高AI的推理能力。
这对于解决复杂的数学问题、进行知识推理等任务非常重要。
更重要的是,DeepSeek还发现,通过使用NSA进行预训练,可以让AI更好地适应各种下游任务。
这就好比打好地基,可以盖出更结实的房子。
当然,NSA也并不是完美无缺的。
在一些短文本任务上,NSA的优势并不明显。
这可能是因为,在短文本中,传统的Attention机制已经足够高效,不需要额外的优化。
DeepSeek的NSA,是一种非常有潜力的注意力架构。
它不仅速度快,而且效果好,有望在长文本处理、思维链推理等领域发挥重要作用。
那么,NSA的出现,真的会让注意力机制“变天”吗?
现在下结论还为时尚早。

但可以肯定的是,DeepSeek这次又给AI圈儿带来了一股新的风。
未来,我们或许会看到更多的AI模型,采用NSA或者类似的架构。
而这些新技术的出现,最终将推动AI技术的发展,让AI更好地服务于人类。
所以,下次再听到“Attention”、“Transformer”这些名词的时候,别再觉得云里雾里了。
记住,这些技术,最终都是为了让我们生活更美好。
它们就像我们身边的水电煤一样,虽然我们平时感觉不到它们的存在,但它们却默默地支撑着我们的生活。
而DeepSeek的NSA,或许就是照亮未来的那束光。
它不仅照亮了AI技术的发展方向,也照亮了我们对美好生活的向往。
