在不久的将来,也许你会看到这样的场景:你走在大街上,你的眼镜不再只是一个辅助工具,而是一个可以实时记录和分析周边环境的智能设备。
无论是突然而来的街头表演,还是意外出现在你面前的陌生物体,眼镜都能迅速识别并告诉你它们是什么。
这种情景看似未来,却离我们越来越近,而这背后的秘密就藏在YOLOe的技术中。
YOLO的演变与YOLOe的诞生让我们先回到2015年,当时的计算机视觉技术正处于快速发展的阶段。
YOLO(You Only Look Once)作为一种突破性的物体检测技术问世,迅速在技术圈中掀起了一番热议。
它以其高效的运算能力和较低的延迟性能,将目标检测提升到了一个新的水平。
尽管YOLO在检测预定义类别上表现优异,但在多场景和动态变化的环境中,它往往显得局限,很难像人眼一样自由探测那些未被预设的物体。
这时,YOLOe来了。

它的使命似乎是为了解决YOLO遗留的这些难题。
YOLOe在继承YOLO架构精华的同时,引入了多种创新机制,试图让机器理解世界的方法更接近人类。
它可以在不依赖事先定义的类别库的情况下,将文字或视觉提示转化为可以识别和分割任意物体的能力。
这一特点,使得YOLOe在多变的开放场景中显得非常有竞争力。
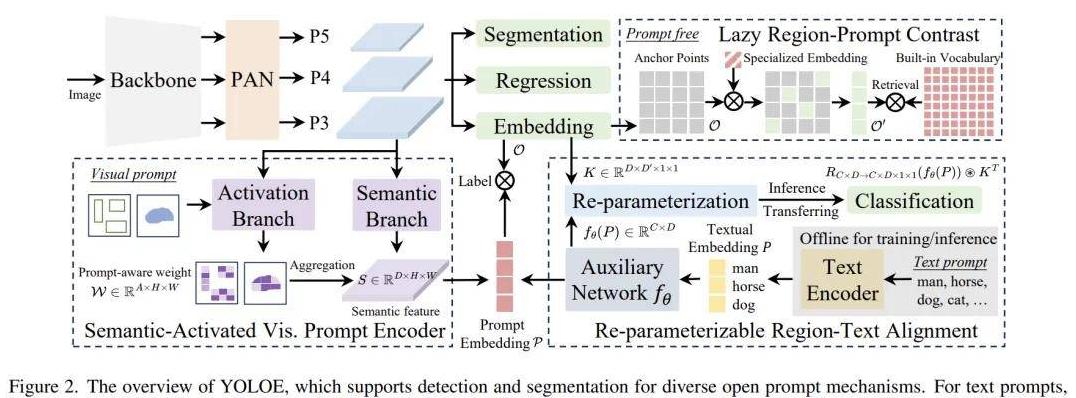
YOLOE的架构与核心技术解析那么,YOLOe到底是如何实现这些功能的呢?
为了对它的核心技术有一个直观的了解,我们需要看一看它的内部架构。
尽管技术细节非常复杂,但其基础理念却相对简单:模仿人眼。
YOLOe的架构中包含了几项重要技术:RepRTA、SAVPE和LRPC。

简单来说,RepRTA负责文本提示,SAVPE用于视觉提示,而LRPC则在无提示的环境中发挥作用。
它们像是一支精英小队,各司其职,共同协作以实现模型的高效识别与分割。
比起复杂的跨模态融合策略,RepRTA通过一个轻量级的辅助网络来对文本进行处理,从而在有限的计算资源下,实现了更为准确的文本与对象对齐。
而SAVPE则通过精巧的分支设计,有效提高了视觉提示的编码效率,避开了以往系统的高运算负担和复杂性。
至于LRPC,它则像是一位骨灰级玩家,基于对词汇的深刻理解,精确找出每个锚点物体的类别定义,使得YOLOe能够在无提示情况下从容应对。
实验成果:YOLOE的性能与优势对比在经过多轮严格的实验测试后,YOLOe的表现让研究团队大为振奋。
基于不同构架的实验数据显示,YOLOe不仅在训练时间上比现有的对手缩短了将近三倍,而且在检测和分割的精确度上也取得了突破性进展。
尤其值得一提的是,在稍微对比劣势的条件下,它依然能够在通用处理速度和实际性能上占据优势。

此外,YOLOe通过完美结合检测与分割功能,使得它在零样本性能的表现更为卓越,而这也恰恰是许多应用场景下的决定性因素。
实际应用场景下的YOLOE可视化分析或许你会好奇,YOLOe的这些技术特性在实际场景中又是如何体现的呢?
通过一个又一个的可视化测试,我们可以看到,YOLOe不仅能在传统的有文本提示的环境下工作良好,还可以在纯视觉提示甚至毫无提示的情况下,准确识别并分割出图像中的物体。
无论是采购环境的顶端摄像头,还是无人机穿越丛林的摄影镜头,YOLOe的能力都在这些场景里得到了淋漓尽致的体现。
通过不同环境和任务的考验,YOLOe证明了它不仅仅是一个理论上的科技成果,而是具备真正突破性意义的技术,这种技术革新也预示了未来视觉技术的发展方向。
在结尾的探讨中,我们不妨思考这样一个问题:随着技术的不断进步,我们的日常生活会在多大程度上被像YOLOe这样的技术所改变和丰富?
无论未来如何发展,我们都已经在见证那个信息不断扩张、技术不断进化、世界不断联动的时代。
也许,我们的未来早已被那些能“看见”一切的技术点亮。