
RLHF(Reinforcement Learning from Human Feedback) 是一种 结合强化学习与人类反馈 的机器学习方法,通过将人类的偏好或评分作为“奖励信号”,指导模型优化其行为或生成内容,使其更符合人类意图。其核心是 “人类在回环中提供反馈”,从而弥补监督学习数据标注成本高、覆盖场景有限的不足。
一、关键术语解释
术语
解释
奖励模型(Reward Model)
通过人类反馈训练的模型,将模型生成的输出映射为奖励值,用于指导强化学习优化。
策略优化(Policy Optimization)
使用强化学习算法(如PPO)更新模型参数,最大化期望奖励。
近端策略优化(PPO)
一种稳定高效的强化学习算法,通过限制策略更新幅度避免性能下降。
偏好标签(Preference Label)
人类对多个模型输出的排序或评分,用于训练奖励模型。
二、背景与核心原理
1. 背景

问题背景:
监督学习的局限性:依赖大量人工标注数据,成本高且难以覆盖所有场景。
生成内容的不确定性:模型可能生成符合语法但不符合人类价值观或意图的内容(如幻觉问题)。
解决方案:
RLHF的突破:OpenAI在2017年提出RLHF框架,2022年应用于InstructGPT/ChatGPT,显著提升生成内容的实用性。
应用领域:对话系统、文本生成、游戏AI(如AlphaStar)、伦理对齐等。
2. 核心原理
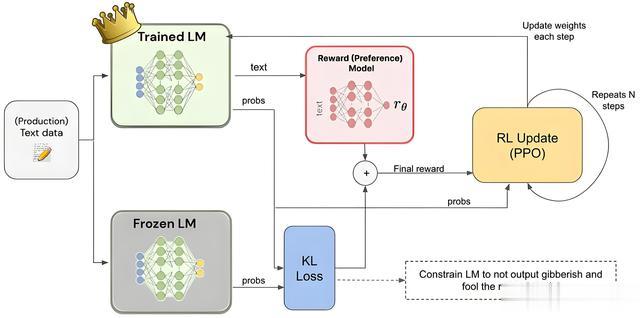
流程:
预训练语言模型(Pre-training):使用大规模文本数据训练基础语言模型(如GPT)。
奖励模型训练(Reward Model Training):
收集人类对模型输出的偏好(如“输出A比输出B更好”)。
训练奖励模型,将输出映射为奖励值。
策略优化(Policy Optimization):
使用PPO等算法,最大化模型生成高奖励输出的概率。
数学表示:
奖励函数:
R(s,a)表示在状态 s下采取行动 a 的奖励值。
目标函数:

三、核心技术与方法

1. 核心技术
(1) 奖励模型训练

数据收集:
偏好标签:人类对模型生成的多个输出进行排序(如“输出A > B > C”)。
示例:用户对“生成笑话”任务的输出进行评分。
模型架构:
使用对比学习框架,如 Pairwise Comparison 或 Multi-Choice Classification。
示例代码(PyTorch):
# 奖励模型:对比两个输出的优劣class RewardModel(nn.Module): def __init__(self, model_name): super().__init__() self.model = AutoModelForSequenceClassification.from_pretrained(model_name) def forward(self, input_ids, attention_mask): outputs = self.model(input_ids, attention_mask) return outputs.logits(2) 策略优化(PPO算法)

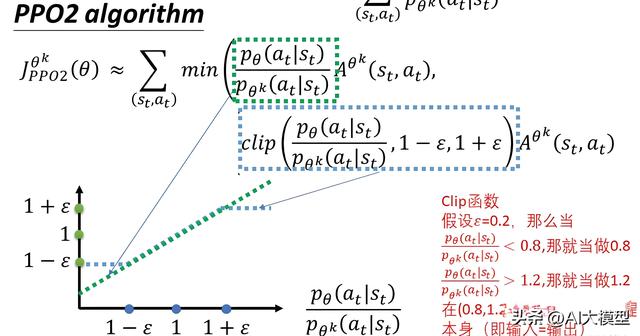
算法流程:
模型生成候选输出。
奖励模型评估输出,得到奖励值。
更新策略以最大化奖励,同时限制策略更新幅度(clip函数)。
PPO 核心公式:

(3) 与监督学习的对比
指标
RLHF
监督学习
数据需求
人类偏好标签(成本低)
大量标注数据(成本高)
覆盖场景
动态适应新场景(如伦理)
依赖历史数据覆盖
生成多样性
高(通过奖励引导)
低(固定标签约束)
模型对齐性
高(人类偏好驱动)
中(依赖标注质量)
四、预训练步骤详解

1. 典型流程
步骤
描述
示例
预训练语言模型
加载预训练模型(如GPT-3)作为初始策略。
使用Hugging Face的transformers库加载模型。
收集人类反馈
通过众包或内部团队收集模型输出的偏好标签(如“输出A比B好”)。
对1000个对话生成输出进行排序。
训练奖励模型
使用对比学习框架(如Pairwise)训练奖励模型。
输入为对话历史+生成回复,输出为奖励值。
策略优化(PPO)
使用PPO算法,最大化奖励模型给出的奖励值。
每次迭代生成1000条回复,更新模型参数。
评估与迭代
通过人类评分或自动指标(如BLEU、ROUGE)评估生成质量,持续优化。
在测试集上收集用户满意度评分。
2. 详细步骤与示例
2.1 监督微调(SFT)

目标
让模型学习人类编写的高质量回答,生成符合指令的初步输出。
关键步骤
1. 数据准备:
数据集:
收集或生成 (prompt, answer) 对的数据集,例如对话、问答对、指令与响应等。
示例数据格式:
[ { "prompt": "如何制作一杯拿铁咖啡?", "answer": "步骤1:蒸牛奶...步骤2:萃取浓缩咖啡..." }, ...]数据要求:
数据需覆盖目标任务的典型场景(如客服、代码生成、文本摘要等)。
答案需由人类编写,确保准确性和自然性。
模型加载与微调:
模型选择:使用预训练模型(如GPT-3、BERT、LLaMA等)。
代码实现(基于Hugging Face的transformers库):
from transformers import AutoTokenizer, AutoModelForCausalLM, Trainer, TrainingArguments# 加载模型和分词器model_name = "facebook/opt-350m"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name)# 数据预处理def preprocess_function(examples): inputs = tokenizer(examples["prompt"], truncation=True, padding=True) labels = tokenizer(examples["answer"], truncation=True, padding=True).input_ids inputs["labels"] = labels return inputs# 训练配置training_args = TrainingArguments( output_dir="./sft_model", per_device_train_batch_size=4, num_train_epochs=3, logging_steps=10)# 启动训练trainer = Trainer( model=model, args=training_args, train_dataset=train_dataset.map(preprocess_function, batched=True),)trainer.train()输出:
SFT模型:
初步具备生成符合指令的文本能力,但可能仍存在偏差或非人类偏好内容。
2.2 奖励模型训练(RM)

目标
训练一个模型,将模型生成的输出映射为奖励值,用于指导后续强化学习。
关键步骤
数据收集:
生成候选回复:使用SFT模型对同一prompt生成多个回复(如4-9个)。
人类偏好排序:让标注员对这些回复进行排序(如“回复A > 回复B > 回复C”)。
示例数据格式:
[ { "prompt": "如何制作拿铁咖啡?", "responses": [ "步骤1...", "步骤2...", ... ], "rank": [3, 1, 2] # 对应三个回复的排序 }, ...]数据要求:
每个prompt需生成至少3个回复,确保多样性。
排序需由人类完成,或使用预训练模型(如ChatGPT)辅助生成标签。
模型架构调整:
将SFT模型的输出层替换为 回归层,输出单个奖励分数。
代码示例(PyTorch):
class RewardModel(nn.Module): def __init__(self, base_model): super().__init__() self.base = base_model # 移除原始输出层(如语言模型头) self.base.lm_head = nn.Linear(base_model.config.hidden_size, 1) # 回归层 def forward(self, input_ids, attention_mask): outputs = self.base(input_ids, attention_mask) return outputs.logits.squeeze(-1)训练奖励模型:
损失函数:使用 对比损失(Contrastive Loss) 或 排序损失(RankNet Loss)。
代码示例(训练对比损失):
criterion = nn.MarginRankingLoss(margin=0.5)optimizer = torch.optim.Adam(rm.parameters(), lr=1e-5)for epoch in range(epochs): for batch in dataloader: # 假设输入为成对的回复 input_ids1, mask1 = batch["input_ids1"], batch["attention_mask1"] input_ids2, mask2 = batch["input_ids2"], batch["attention_mask2"] labels = batch["labels"] # 1表示第一个回复更好 reward1 = rm(input_ids1, mask1) reward2 = rm(input_ids2, mask2) loss = criterion(reward1, reward2, labels) loss.backward() optimizer.step()输出:
奖励模型(RM):可评估任意文本的奖励值,用于后续强化学习。
3. 基于PPO的强化学习微调

目标
通过最大化奖励模型输出的奖励值,优化模型生成更符合人类偏好的内容。
关键步骤
算法选择:
使用 近端策略优化(PPO),因其稳定性高且计算效率优于传统策略梯度方法。
训练流程:
生成候选回复:模型根据当前策略生成回复。
计算奖励:使用RM对回复进行评分。
策略更新:通过PPO算法更新模型参数,最大化奖励。
代码实现(基于Hugging Face的trl库):
from trl import PPOTrainer, PPOConfigfrom transformers import AutoTokenizer, AutoModelForCausalLM# 加载SFT模型和RMsft_model = AutoModelForCausalLM.from_pretrained("sft_model")reward_model = RewardModel(sft_model)# PPO配置config = PPOConfig( batch_size=8, learning_rate=1e-5, ppo_epochs=4, clip_range=0.2, seed=42)# 初始化PPOTrainerppo_trainer = PPOTrainer(config, sft_model, tokenizer)# 训练循环for epoch in range(10): # 生成回复 prompts = ["如何制作拿铁咖啡?", ...] responses = ppo_trainer.generate(prompts, max_new_tokens=50) # 获取奖励 rewards = [] for prompt, response in zip(prompts, responses): input_str = f"{prompt} {response}" reward = reward_model( input_ids=tokenizer(input_str, return_tensors="pt").input_ids ) rewards.append(reward) # 更新策略 stats = ppo_trainer.step(prompts, responses, rewards) ppo_trainer.log_stats(stats)关键参数:
参数
说明
clip_range
限制策略更新幅度,通常设为 0.2。
entropy_coefficient
鼓励探索,通常设为 0.01。
num_rollouts
每次迭代生成的样本数,如 128。
输出:
最终模型:生成内容更符合人类偏好,同时保持与原始模型的分布一致性(通过KL散度约束)。
3. 关键注意事项
3.1 数据一致性
跨阶段数据分布一致:
SFT、RM、PPO阶段的数据需来自同一领域或任务,否则可能导致训练不稳定。
例如:若SFT数据是客服对话,后续阶段数据也应为客服场景。
3.2 奖励模型的训练
数据量要求:
奖励模型需足够鲁棒,通常需要 500-1000条排序数据 启动训练。
避免过拟合:
使用交叉验证或数据增强(如随机截断回复)提升泛化性。
3.3 PPO训练
计算资源:
PPO阶段需较大显存(如8-16GB/GPU),建议使用分布式训练(如DeepSpeed)。
监控指标:
跟踪 KL散度 和 奖励值均值,防止模型偏离原始分布或奖励下降。
4. 关键参数与超参数
4.1 监督微调(SFT)
参数
说明
learning_rate
通常为 1e-5 到 5e-5,避免过大的学习率破坏预训练参数。
batch_size
根据显存调整,如 4 到 8。
num_train_epochs
通常 3-5 轮,避免过拟合。
4.2 奖励模型训练(RM)
参数
说明
loss_function
推荐使用 对比损失(如 nn.MarginRankingLoss)。
training_steps
通常 1000-5000 步,直到验证集排序准确率稳定。
4.3 PPO优化
参数
说明
clip_range
限制策略更新幅度,通常 0.2。
entropy_coefficient
鼓励探索,通常 0.01。
num_rollouts
每次迭代生成的样本数,如 128。
5. 工具与库
TRL库:
链接:https://github.com/huggingface/trl
功能:实现PPO、DreamBooth等RLHF算法。
Colossal-AI:
链接:https://github.com/Colossal-AI/ColossalAI
功能:支持大规模模型的高效训练(如ColossalChat开源代码)。
总结
RLHF 通过 SFT-RM-PPO 三阶段流程,将人类偏好融入模型训练,显著提升生成内容的质量与对齐性。实际应用中需注意数据一致性、计算资源分配和监控指标。如需进一步优化,可尝试以下进阶操作:
多阶段迭代:重复PPO阶段,逐步提升奖励值。
自动化反馈:使用预训练模型(如ChatGPT)生成初始排序标签,减少人工成本。
多模态扩展:在图像、视频生成中结合视觉与文本反馈。
