
在某个咖啡馆的小角落里,小张和他的编程朋友们正在激烈地讨论一个新话题:为什么32B模型能够击败那些号称最强的AI模型?
这可不仅仅是因为它的外观体积,更是它过去几个月在开源项目中的惊人成长。
大家面前的一份电子文档里,记录的是一项令人瞩目的创新:Hugging Face的最新开放项目Open R1。

不同于以往,这次的突破源自于社区的力量和高质量数据的结合。
Open R1 项目简介与目标如果要说起Open R1项目,那这是个由Hugging Face牵头的开源计划。

最初,只是想为AI开发者提供一个开放的平台,凝聚大家的智慧,去超越现有的模型能力。
眼下,Open R1通过不断的更新与迭代,在数据处理能力、代码生成等方面都迈出了大步。
它不仅限于传统AI模型的框架,而是通过社区的协作不断实现自我的突破。

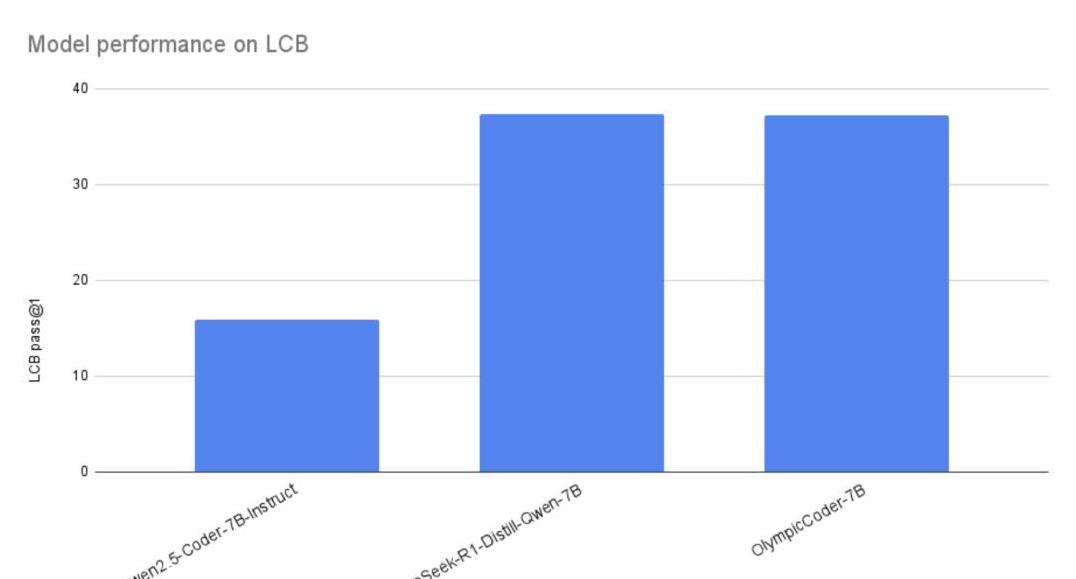
32B模型的另一个名字是OlympicCoder。
作为编程圈的“急先锋”,它在2024年的国际信息学奥林匹克竞赛上大放异彩。

与一些体积庞大的模型相比,OlympicCoder显得更加精简而高效。
在这场比赛中,它的每一步策略都经过了精心挑选,针对每一个子任务进行计算和优化;其灵活且精准的表现赢得了众多开发者的尊重。
这也让它成为业界讨论的话题焦点。

在大会某个角落,另一群人津津乐道的话题是CodeForces-CoTs数据集。
在这个数据集上,Open R1聚集了近10万个高质量样本,这些数据并不只是简单的代码段,而是包含了丰富的思维链。

这些背后的逻辑推理和代码生成试题让一些高级AI模型都难以匹敌,而OlympicCoder通过实践证明,该数据集的重要性不容小觑。
这可能就是为什么当下众多AI研究机构趋之若鹜地投入其中的原因。
深入探讨模型优化策略
不只是拥有高质量的数据集,Open R1项目允许团队使用类似OpenAI的创新策略,来最大化每个提交的得分。
他们利用过去的经验和教训:如何在编程竞赛里有效提交;如何在复杂的竞赛条件下优化时间和资源。
通过逐渐优化提交策略,OlympicCoder在实际应用中更显出其价值。

这种做法可以帮助模型掌握如人工玩家般灵活的竞赛策略。
尾声中,小张终于忍不住对大家说:“看吧,这就是我们一直寻找的方向。
32B模型的成功只是个开始,我们所做的每一步都在为更庞大的人工智能画卷添上重要的一笔。

正如他们所讨论的,在AI的世界里,每一个成功的模型背后,都承载着无数开发者的心血和努力。
而这些都在鼓励每一个怀揣梦想的程序员继续创造,继续探索。
未来,科技不断进步,像32B这样高效而实用的框架,会以更频繁的姿态出现在我们的生活或工作中。
希望这一系列的创新能给大家带去更多灵感与动力,让我们的世界因为这些技术变得更加美好。
