
作者:赵洪鑫 复旦大学医学博士 北京洪宇科技有限公司CEO
这是一个全自动做倾向性评分匹配(PSM)的工具。
大家可能会问,SPSS不就可以做PSM,还开发这个工具有啥意义?主要在于几点:
1)瞬间自动生成匹配前后基线特征表和love plot。
2)可以边看匹配后的结果表格边调匹配参数,实时调整结果,所见即所得。
3)自动生成Word报告,论文里需要的图表一分钟给您全部准备好。
4)集成数据管理工具、缺失数据处理工具,生成匹配后的数据下载做进一步分析。
所谓倾向性评分匹配,用粗俗的话说来就是在非随机对照研究中,因为没有随机分配患者,所以观察组和对照组基线特征有差异,俗称基线不平衡。会使得读者质疑你的疗效分析结果。所以我们只好牺牲一些样本量,从对照组中选择一部分和观察组基线差异较小的患者,来进一步分析疗效(有时候为了效果,观察组也要牺牲掉一部分样本)。
从对照组里选择哪些患者,才能缩小和观察组的差异呢?交给计算机自动处理就行,自己不用操这个心了。
进入下面这个网站,选择倾向性评分匹配工具来进行:www.b-hy.com/ai
第一步,根据提示先下载样例excel,准备您的数据:

应该包括ID号,代表组别的变量如group, 以及需要调整和匹配的协变量如age, gender, smoke, diagnose,program等。应当注意的是,代表组别的变量, 下面只能包含两个组,如"Treatment" ,"Control", 或者GroupA GroupB等。不能包含两个以上组。三组的PSM本工具暂不提供,会重新研发一个工具。
将准备好的数据导入系统:

上传之后看一下没有问题,一定要点击最下方的 “import data” 按钮才能下一步。
下一步点击上方的 “选择字段” 标签:

这一步非常重要,关系到PSM的处理方式,不能略过。需要对变量的标签和属性做一些调整,另外设置一下,连续性变量设置为numeric, 分类变量设置成character。 比如stage这个变量,是个数值型,取值我们在右边看到只有1,2,3,4,其实代表的是疾病分期,只是一个分类变量,并不是一个连续变量,这时候我们务必要把字段的属性在New菜单里设置为“character”,后续才能正确处理。
字段名称可以改成最终统计表里的名称,比如 age 可以改成 Age, 首字母大写等等。
然后在这个页面,哪怕你什么也没修改,也务必要点击“Apply Changes” 按钮,才能进入下一个页面,否则进行不下去。
下一步可以点击“选择患者”,如果要选取一部分患者做亚组分析的话,在这个页面做选择和调整。如果没有需要则直接下一步。
下一步点击“处理缺失数据”

这里提供了两种方式处理缺失数据,第一种简单粗暴,只要有任何一个进行PSM的字段有缺失值,就把这个患者直接剔除。第二种是用kNN法填补缺失值。大家可以综合自己的数据缺失程度考虑哪种方法。
缺失值填补仅限于要匹配的协变量。如果分组变量group也缺失,或者ID号也缺失可不要填补哟。还是返回最开头,把您的excel数据重新整理上传,group和ID不容缺失。
下一步点击“进行倾向性评分匹配”:
首先选择代表组别的字段,这个案例里是group, group字段里面包含Treatment 和 Control两个组,在这两个组间进行PSM。千万不要把ID号、age这样的连续性变量设为组别,程序会崩溃。
值得注意的是,本工具基于每组的患者数量,自动把人数多的一组设置为对照组,人数少的一组设置为观察组。优先考虑保留最多的观察组患者。
然后点击变量选择框,按照自己想要的顺序选择需要匹配的变量。
然后选择1:N匹配。N值上限,程序自动认定不会超过两组患者数的比值。
可选的匹配方法现在放出来的主要是optimal, nearest, exact。其中optimal, nearst 可选1:N,nearest可选caliper, 大家可以根据提示,看着生成的图表来调参,以达到满意的结果。
调试策略如下:

在生成的表1中,可以实时看到匹配前后的样本量和SMD值。
尝试改变各种参数使得SMD值低于0.1即可。
可以看着下图调整:
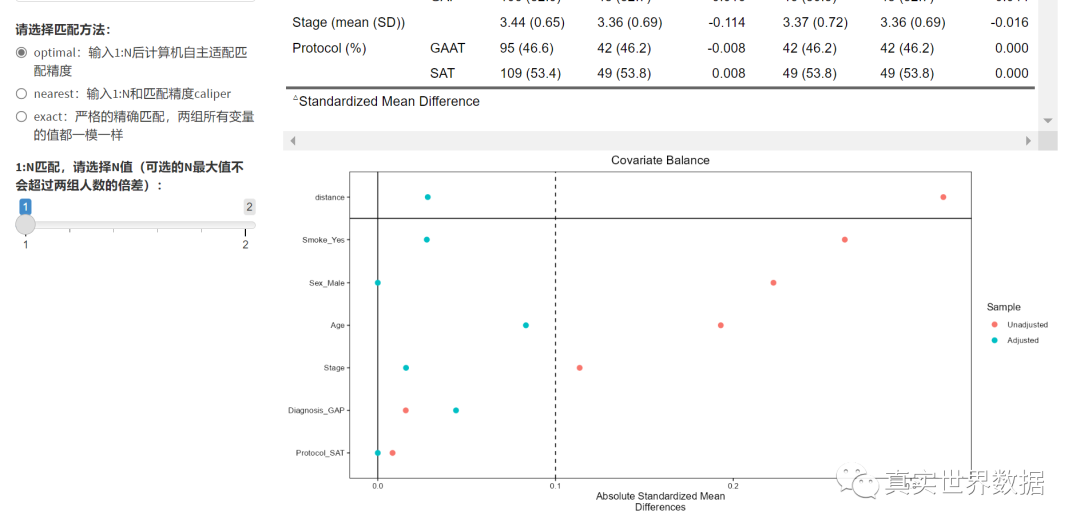
调整参数使得绿色的点全部位于虚线左边就算成功。当然,有个别的点,实在没办法低于0.1也不要紧。科研嘛,还是要考虑科学性和现实性的平衡。
匹配完成后,可以点击“生成各种诊断图”,程序会瞬间生成各式各样的用于诊断PSM的图,按需选用即可。

最后,点击“下载word报告”,先点生成word报告,等一会后再点下载:




这样的话,论文里要求要有的表和图都给您打包好了,您直接贴进论文即可。
最后,点击“下载匹配后数据”,下载excel格式的匹配后数据,就可以用来进一步分析疗效了:

这时候,有人不满意了,什么?匹配完还要我自己导出数据分析?直接帮我自动分析完不行么?好的,下一个版本必须安排!
