作者:赵洪鑫 复旦大学医学博士 北京洪宇科技有限公司 CEO
今天上线睿智统计机器人的“影响因素分析”模块,对比了一下市场上的同类产品,这款应该是最先进最方便最漂亮的,不怕挑战。
软件地址:www.b-hy.com/ai
主要特点:
根据上传的科研数据,简单点击设置后,自动完成单因素和多因素的分析
支持线性回归、Logistic回归、Cox回归、Poisson/负二项回归
自动合并单因素和多因素分析结果
支持人工纳入多因素变量、逐步回归纳入多因素变量
自动生成影响因素森林图
自动批量生成生存曲线
生成投稿格式的word统计表
首先务必按照下面的格式准备数据(网站上可下载,下载后在此基础上修改):
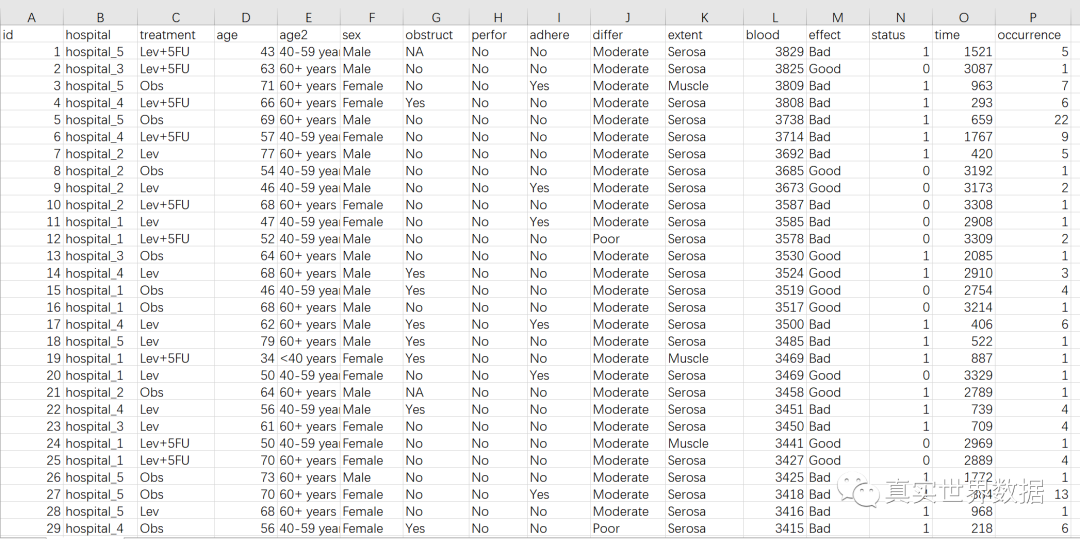
本样例数据的规则:
一个患者一行(这是准备数据最重要的前提)。
每个患者准备两大类数据,影响因素变量和结局变量,影响因素和结局分别都可以有多个变量。
如图所示,hospital, treatment, age, age2, sex, obstruct, prfor, adhear, differ, extent 为影响因素(自变量),而blood, effect, status, time, occurrence在本例中是结局变量。
影响因素变量有两种,连续性变量(值是连续数据,它可以在变量值所属区间内任意进行取值,如年龄[岁]、血糖值、人的身高、智商等)以及分类变量(是说明事物类别的一个名称,其取值是分类数据。如”性别”就是一个分类变量,其变量值为”男”或”女”;“行业”也是一个分类变量,其变量值可以为”零售业”、“旅游业”、“汽车制造 业”等),在本例中 age是连续性变量(numeric), 其他的是分类变量(factor)。age单位为”岁”时为连续变量,而age2为年龄段分组,这时候为分类变量。
以上概念很重要,后面有一个页面专门设置连续变量和分类变量。
结局变量在本工具中分为几类:
连续型结局变量
如本例中的blood(某血液检测指标)
二分类结局变量
如本例中的effect(疗效)为二分类变量(Good,Bad)
生存型结局变量
需要用两个变量组合来表示,如本例中的status和time。
status代表患者在研究结束时的状态,在本工具中只能取0和1两个数字,不要用字符文本,否则会出错。0 代表没观察到事件发生(如没死或者失访),1 代表观察到了事件发生(如已经死亡且录入了死亡日期)。
time代表从开始日期(开始日期的定义由你的研究目的决定,如随机对照研究往往取随机化入组的那一天为开始日期,而观察性研究可以取首次诊断日期或首次治疗日期等等根据研究目的而定)到结局日期的时间差。当status=1时,结局日期为发生事件(如死亡)的日期,当status=0时,结局日期为最后一次活着的日期(如研究结束日,或随后一次随访日)。
总之,time是一个数值型变量,您需要填入患者从开始到死亡或者随后一次随访时,一共活着的天数。如time为56,status为1时代表患者从开始到死亡活了56天;当time为56,status为0时代表患者没观察到死亡,从开始到最后一次随访,活了56天。
准备数据时,time填入一个非负的整数,status填入0或1,time和status都不能为空,每个患者都必须填入数字。time或status不确定(缺失)时,该患者最好不要放入本数据库。
计数型结局变量
计数型的结局变量为一个非负的整数,如本例中occurrence,是急性发作次数,无法取负数,也不可能取小数。
分数型结局变量
当结局变量为一个分数,如发病率、患病率、受精率等,结局包含一个分子和一个分母。如要研究全国各地疾病患病率的影响因素时,按照每个地区一行来准备数据,分子和分母设置成两个变量(列),如分子为患病人数,分母为地区人口数。
准备数据的规则是:分子和分母都是非负整数,不允许填入负数,也不允许填入小数,分子的数值不能大于分母。
进入下面的网页开始使用工具:
http://www.b-hy.com/ai
上传和导入数据
然后进入“导入数据”页面,上传文件,然后务必要点击“import data” 按钮
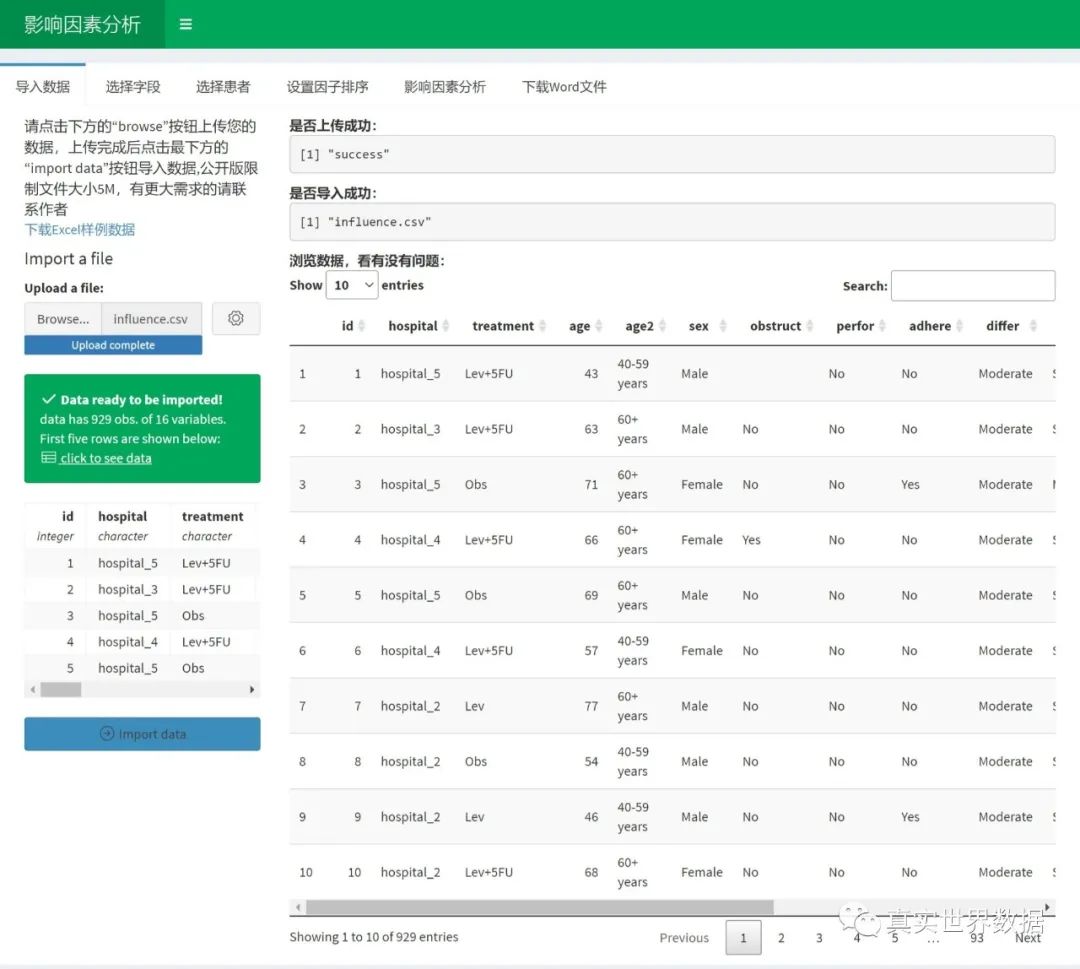
数据导入之后,可以对字段做一些修改和调整:

这一步非常重要,不能跳过连续性变量,都设置为numeric, 分类变量,设置成factor。 字段名称可以改成最终统计表里的名称,比如 age 可以改成 Age, 首字母大写等等。如果很多连续性变量被设置成了character或factor, 后续统计分析会出现系统崩溃的情况。另外,代表生存状态的变量如status,必须设置为numeric, 取值0或1,否则后续生存分析会系统崩溃。然后在这个页面,哪怕你什么也没修改,也务必要点击”Apply Changes” 按钮,才能进入下一个页面,否则进行不下去。
然后进入“选择患者” 页面:
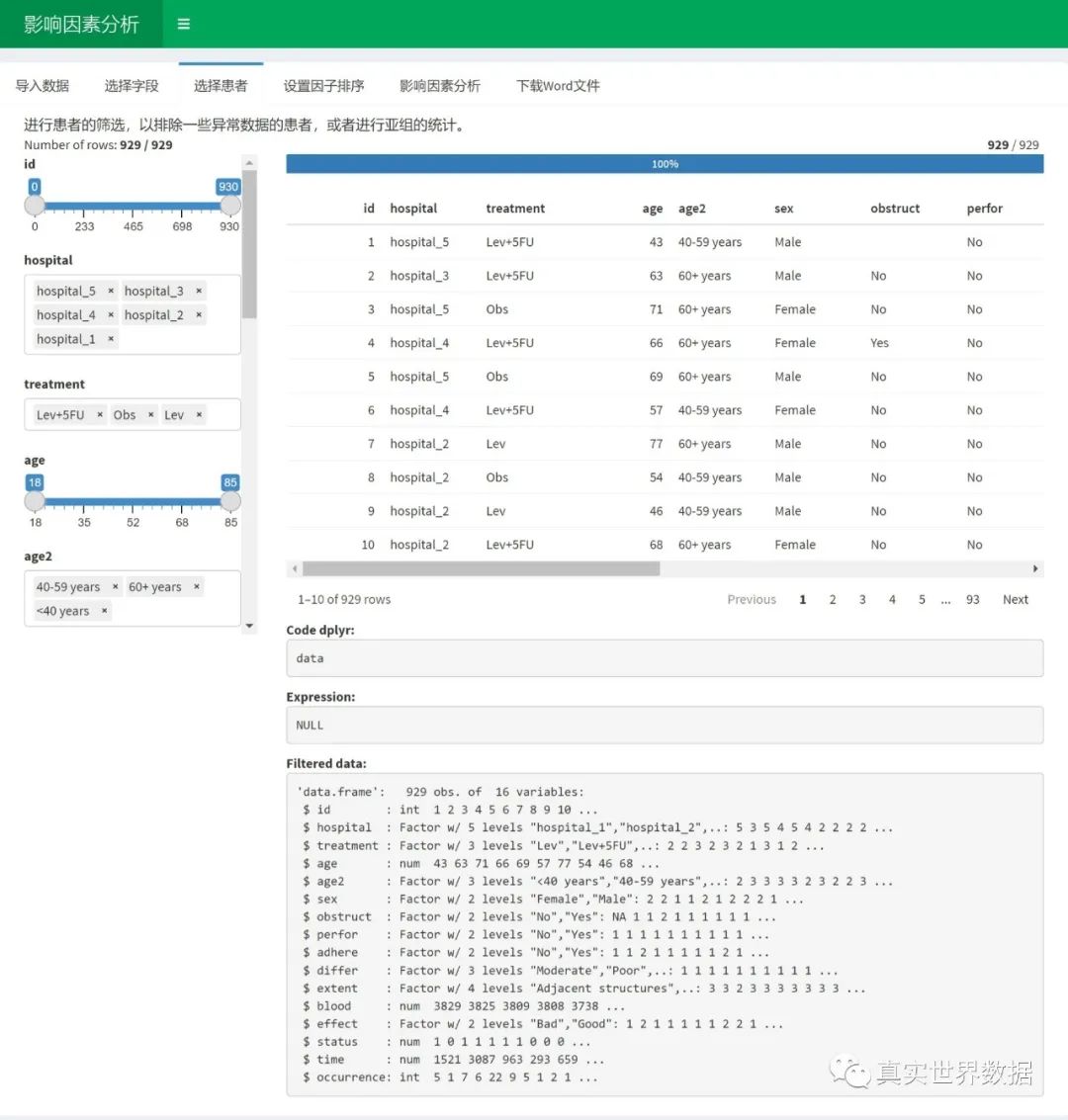
如果要选取一部分患者做亚组分析的话,在这个页面做选择和调整。
设置因子排序
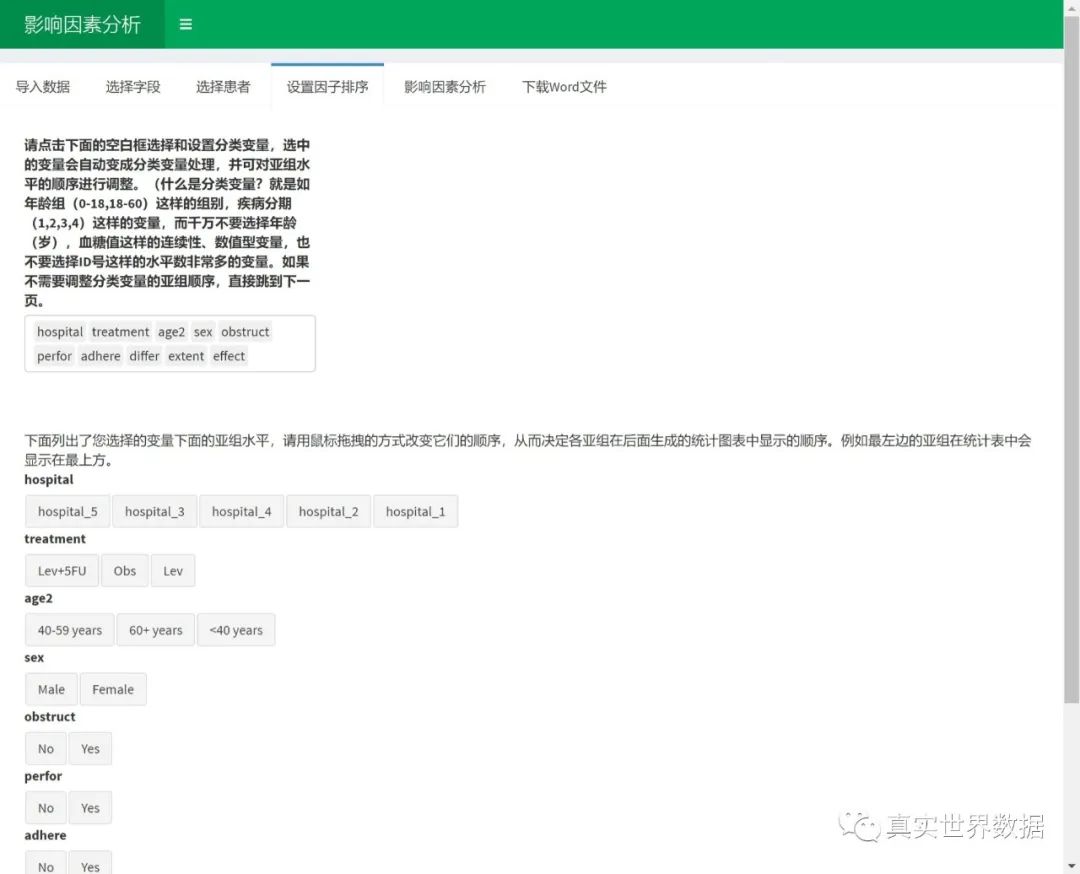
然后进入下一个页面“设置因子排序”:
点击空白框选择变量,被选择的变量会强制变成分类变量,因此这里千万不要选连续性变量,或者ID号码等水平数极多的变量,不然后续会系统崩溃。
选择完毕之后,就可以用鼠标拖拽改变分类变量下面的亚组水平顺序啦!这个很关键,因为排在左边第一位的,在后面影响因素分析里是会作为参照水平的!
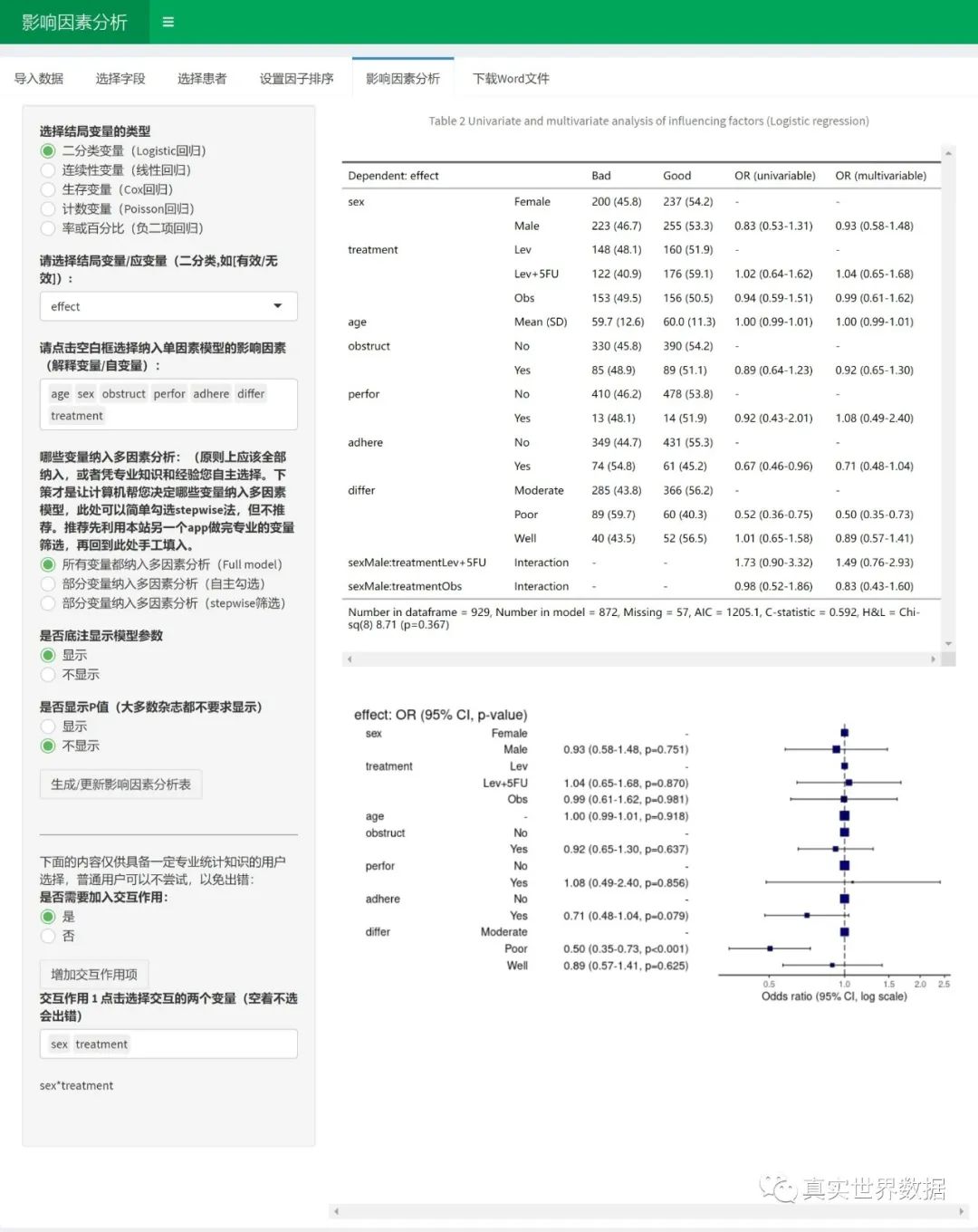
影响因素分析
下一步就是影响因素分析啦:
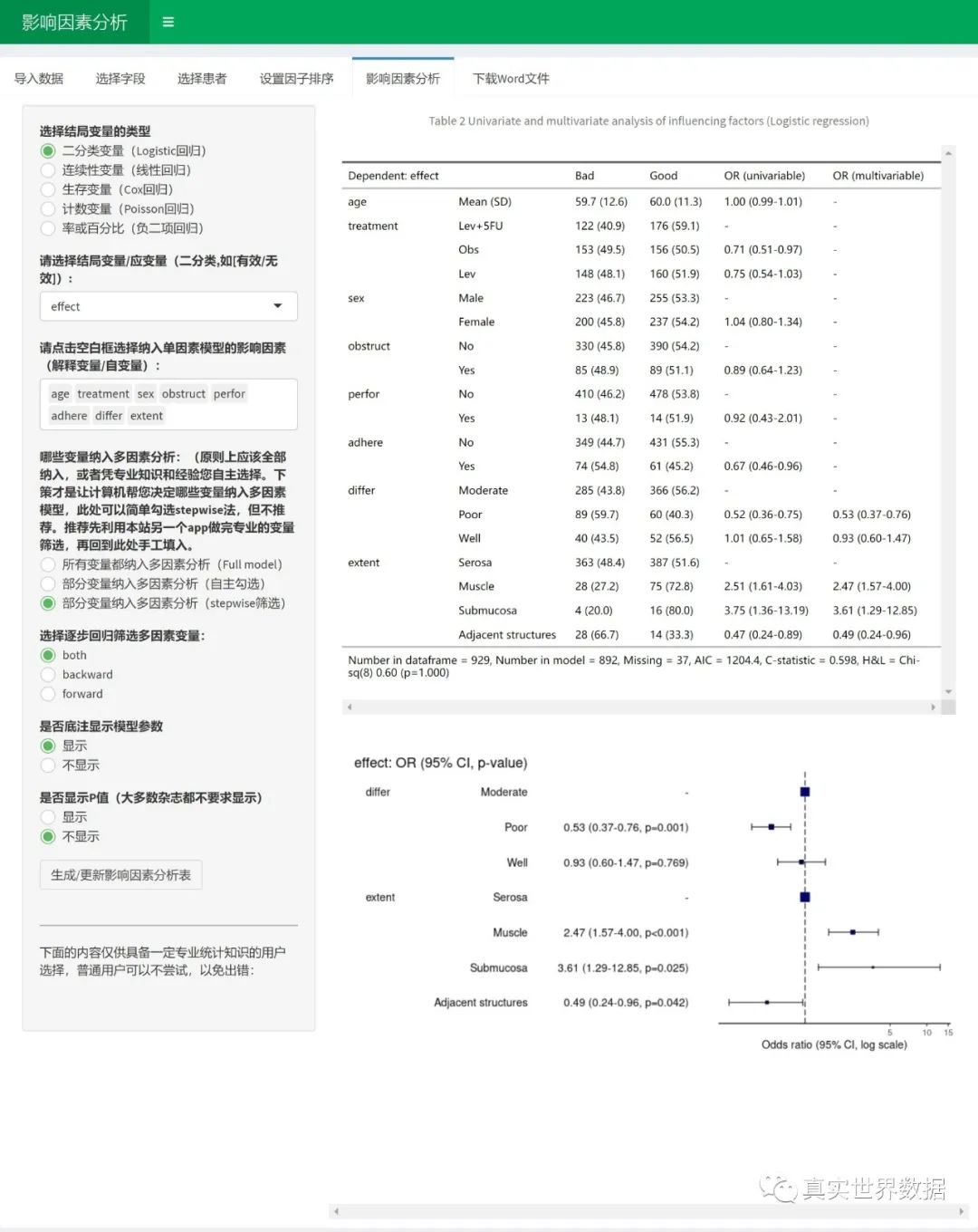
选择结局变量
机器人根据结局变量的类型来选择分析方法。二分类变量,系统会选择logistic回归,如果是连续性变量,系统会选择一般线性回归。如果是生存变量Time和Status的组合,系统会采用Cox回归。如果是计次计数变量,系统会选择Poisson回归,当然如果是率或者百分比,也会采用Poisson/负二项回归。
选择影响因素变量
根据提示选择结局变量和影响因素变量,最后点击”生成/更新影响因素按钮”即可。这里要注意的是,如果上传的数据Excel文件里把连续性变量设置成了字符型,如年龄设置成了字符型,需要在前面”选择字段”功能里改回成numeric,如果按照分类变量放进影响因素分析,会因为分类巨多把服务器卡死。同理,如果把ID号也作为分类变量放进影响因素,服务器也容易卡顿死机。
另外,在分类变量里,有些亚组人数很少,最好把它和其他亚组合并之后再传上来分析,亚组人数太少容易让可信区间特别宽,影响排版。当然,后续我们也会增加一个合并亚组的小工具。
哪些变量入选多因素模型
单因素和多因素分析时同时自动完成的。事先可以规定哪些变量从单因素模型入选多因素模型,可以选择全部都进入,或者部分筛选进入。一般可以全部都纳入多因素。但如果因素太多,十几个几十个,那就要筛选一下变量了,放入模型的变量数不应该超过 样本量N/20。我们的经验是十多个,整体别超过二十个变量。 如果只放部分单因素变量进入多因素,可以点”选项2”,自行选择哪些变量纳入多因素分析,这时候主要是参考历史研究以及研究者的临床经验。另外也可以选逐步回归,点击stepwise,可以选择”both”,然后系统会自动筛选纳入多因素的变量。当然,最好的方法可能是lasso 回归选择变量功能,我们下个版本会把lasso放进去。
交互作用
当选择所有变量都纳入多因素(full model)时,还可以添加交互作用,在最下方。“添加交互作用项”的按钮可以重复点击增加多个交互项。
生成生存曲线
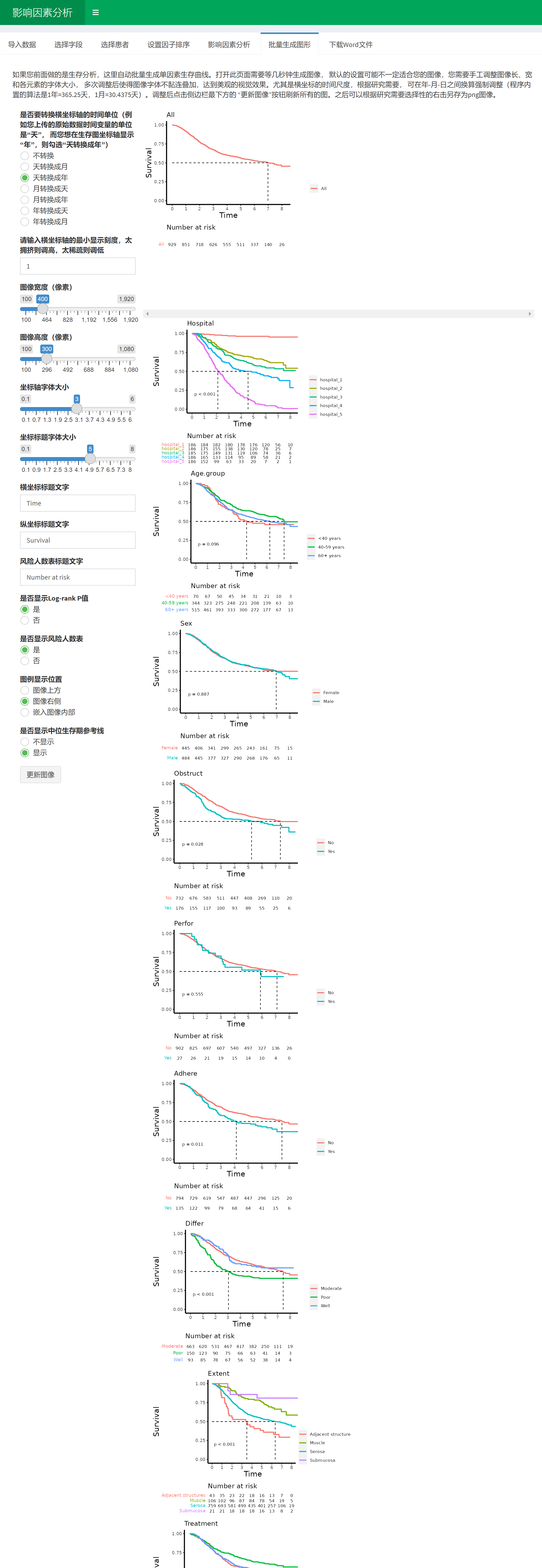
另外,在1.1版本中,如果您选择的是生存结局,用的Cox回归,也可以顺便批量生成生存曲线,当影响因素分析完成后,点击”批量生成图形”,就把所有变量分组的生存曲线瞬间生成了。
下载word文件
最后进入“下载word文件”

另外,后续在2.0版本会给图表增加文字,如统计方法描述,统计结果的配套文字描述在下一个版本会自动生成,大家只要稍作修改就可以直接放进论文中了。
生成文字版的统计报告才是睿智统计机器人的精华,最终会做到半自动生成论文。到时候您只需要撰写Backgroud和Discussion就行了,而Statistical Methodology 和Results部分,计算机会根据研究类型自动生成好。
软件地址www.b-hy.com/ai
