人工智能模型可能缺乏准确性,这是不争的事实。 对于开发人员来说,产生幻觉和重复错误信息一直是一个棘手的问题。 由于用例千差万别,因此很难确定与人工智能准确性相关的可量化百分比。 一个研究团队声称,他们现在已经掌握了这些数字。
Tow 数字新闻中心最近研究了八个AI搜索引擎,包括 ChatGPT Search、Perplexity、Perplexity Pro、Gemini、DeepSeek Search、Grok-2 Search、Grok-3 Search 和 Copilot。 他们测试了每种工具的准确性,并记录了工具拒绝回答的频率。
研究人员从 20 家新闻出版社(每家 10 篇)随机选择了 200 篇新闻报道。 他们确保每篇报道在使用文章摘录时都能在Google搜索中返回前三个结果。 然后,他们在每个人工智能搜索工具中执行相同的查询,并根据搜索是否正确引用了 A)文章、B)新闻机构和 C)URL 来评定准确性。
然后,研究人员根据从"完全正确"到"完全不正确"的准确度给每条搜索贴上标签。 从下图中可以看出,除了两个版本的 Perplexity 外,其他人工智能的表现都不理想。 总体而言,人工智能搜索引擎有 60% 的时间是不准确的。 此外,人工智能对这些错误结果的"信心"也强化了这些错误结果。

这项研究之所以引人入胜,是因为它以量化的方式证实了我们几年前就已经知道的事实--LLM是"史上最狡猾的骗子"。 他们以完全权威的口吻报告说,他们所说的都是真的,即使事实并非如此,有时甚至会争辩或在面对质疑时编造其他虚假的断言。
在 2023 年的一篇轶事文章中,Ted Gioia(诚实的经纪人)指出了数十条 ChatGPT 的回复,显示机器人在回复大量询问时自信地"撒谎"。 虽然有些例子是对抗性询问,但许多只是一般性问题。
即使承认自己错了,ChatGPT 也会在承认错误之后提供更多的虚假信息。 LLM 似乎被编程为不惜一切代价回答用户的每一个输入。 研究人员的数据证实了这一假设,并指出 ChatGPT Search 是唯一能回答全部 200 条文章查询的人工智能工具。 不过,它的完全准确率仅为 28%,完全不准确的时间占 57%。
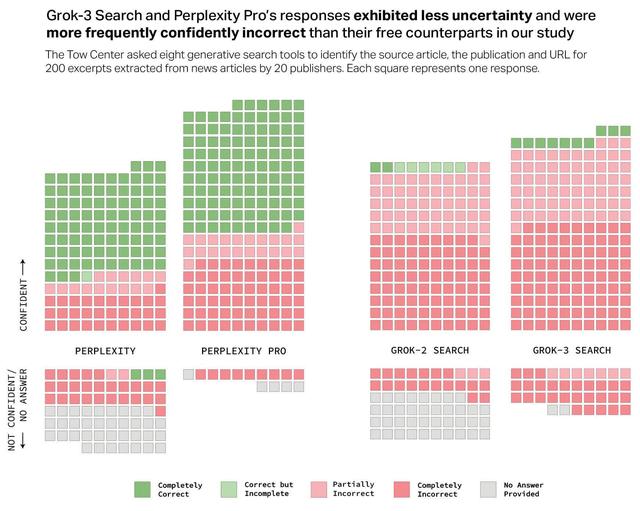
ChatGPT 还不是最差的。 X 的 Grok AI 的两个版本都表现不佳,但Grok-3 Search 的准确率高达 94%。 微软的 Copilot 也没好到哪里去,因为它在 200 次查询中拒绝回答了 104 次。 在剩下的 96 个查询中,只有 16 个"完全正确",14 个"部分正确",66 个"完全错误",因此它的准确率大约为 70%。
可以说,这一切最疯狂的地方在于,制造这些工具的公司对这种缺乏准确性的情况并不透明,同时向公众收取每月 20 到 200 美元的费用。 此外,Perplexity Pro(20 美元/月)和 Grok-3 Search(40 美元/月)比其免费版本(Perplexity 和 Grok-2 Search)回答的查询正确率略高,但错误率也明显更高(上图)。
不过,并非所有人都同意这种说法。 TechRadar 的兰斯-乌拉诺夫(Lance Ulanoff)表示,在尝试了 ChatGPT Search 之后,他可能再也不会使用 Google 了。 他描述说,该工具快速、清晰、准确,界面简洁、无广告。
