苹果悄悄推出新款MacStudio!它配备M3Ultra和M4Max两种芯片。
M3Ultra版本拥有32核CPU、80核GPU,还有高达512GB的统一内存。
厂家表示,它可以运行超过6000亿参数的LLM,在家就能体验DeepSeekR1的满血性能!这引起了不少关注?有人问,现在AI大模型这么火,买MacStudio比单独买GPU划算吗?它在AI任务里的表现,比其他顶配PC强吗?最近,许多国外用户收到新设备后就开始做评测了。
硅谷咨询公司CreativeStrategies的技术分析师MaxWeinbach抢先体验了256GB版MacStudio。
他测试了QwQ32B、Llama8B和Gemma29B等模型,并分享了不同设备上的评测数据。

YouTube博主DaveLee也用512GB的MacStudio跑起了DeepSeekR1!MacStudio在AI领域的表现实际怎样呢?咱们直接看结果!MaxWeinbach觉得,NvidiaRTX5090在GPU基准测试和一些AI任务上表现亮眼,但苹果芯片用起来更舒服,也更稳定。
他推荐开发者用MacStudio(M3Ultra)做桌面AI开发,租NvidiaH100服务器处理大量计算任务!DaveLee发现,macOS默认限制了VRAM分配,得手动调高上限才能成功跑DeepSeekR1。
运行这个模型时,整机功耗不到200W!如果用传统的多GPU配置,耗电量至少是M3Ultra的10倍!MaxWeinbach的测试经历是怎样的?他从2020年买了第一台M1MacBookPro后,就成了AppleSilicon的铁杆粉丝,从M1MacBookPro升级到M1Max?再到M3Max!他一直重视内存性能!因为Chrome浏览器很吃内存,而且他认为内存是影响电脑性能的最大瓶颈。
选M3Max的时候,他配了128GB内存。
考虑到Llama.cpp和MLX等AI框架很流行,它们会很快用完所有内存。
但现在,随着AI模型越来越大、自动化工作流程越来越复杂,128GB内存真的不够用。
MacStudio的M3Ultra芯片让他觉得性能提升很大!他认为这是特别适合AI开发者使用的工作站!超强GPU、最高512GB统一内存(LPDDR5x)和819GB/s的超高内存带宽!简直是梦寐以求的装备!MaxWeinbach指出,基本上所有AI开发者都在用Mac。
毫不夸张地说,顶级实验室和开发者的工作环境中,Mac已经成了标准配置?他买了新版MacStudio后,迫不及待地配置了M3Ultra芯片、32核CPU、80核GPU、256GB统一内存(其中192GB可用作VRAM)和4TBSSD!MaxWeinbach坦言,M3Ultra是他用过最快的电脑,甚至比他的顶配游戏PC(Inteli913900K+RTX5090+64GBDDR5+2TBNVMeSSD)厉害!为了验证这一点,他用M3Ultra、M3Max和他的游戏PC做了GeekbenchAI基准测试。
结果如何?我们接着往下看!在讨论M3UltraMacStudio运行LLM的表现前,先说说LLM为什么特别吃内存。
LLM主要有两个部分占内存,其中一些可以优化!一个是模型本身的大小。

LLM通常用FP16格式存储,每个参数占2字节。
计算方法是:参数数量×2=模型大小(GB为单位)。
比如,Llama3.18B(80亿参数)大约需要16GB内存。
DeepSeekR1用FP8格式,6850亿参数大约需要685GB内存。
阿里巴巴的QwQ32B不相上下,它采用BF16,完整模型大约64GB。

LLM运行时,如果把模型量化到4-bit,所需内存可以减少一半甚至四分之一,主要看模型本身。
8B参数模型量化后大约占4GB!DeepSeekR1仍然需要350GB内存。
还有更极端的1.5-bit或2-bit量化方式,但这通常会导致模型质量下降!没啥用!DeepSeekR1即使2-bit量化后也需要250GB内存。
即使是最小版本的DeepSeekR1也需要180GB内存,但这还不是全部!另一个吃内存的因素是上下文窗口,也就是LLM处理信息的记忆范围。
简单来说,就是模型一次能处理多少文本!这决定了它理解上下文的能力,大多数模型的上下文窗口已经扩展到128Ktokens,但通常32K就足够了。

客户端运行LLM常用llama.cpp框架,它会一次性加载完整的上下文窗口缓存和模型,比如QwQ32B本身只有19GB,加载后却占了51GB内存!Apple的MLX框架更灵活,只在需要时才把KVCache放进内存里!对于M3Ultra或M4Max这种大内存芯片,这种机制可以支持更高精度的模型,QwQ32B在原生BF16精度下,完整上下文窗口加载后需要超过180GB内存!一个32B的模型,光运行就可能占180GB内存!这些大模型有多少内存用多少!未来的趋势是上下文窗口越来越大,所以高内存配置很重要!Qwen和Grok3的上下文窗口已经扩展到100万tokens,Grok3未来还计划开源。
虽然模型大小受限,但更大的上下文窗口对实际应用更重要!这意味着需要大量内存!想同时跑大模型和超大上下文窗口?512GB内存起步!甚至更高!MacStudio还可以通过Thunderbolt5连接多台设备,利用苹果的高速通道进行分布式计算,实现1TB+的共享内存。
这个话题以后再聊。
虽然可以在手机或笔记本上跑LLM,但想在生产环境中流畅使用、做模型评估,就必须有足够大的GPU内存。
目前,MacStudio(M3Ultra)是目前较好的选择之一。
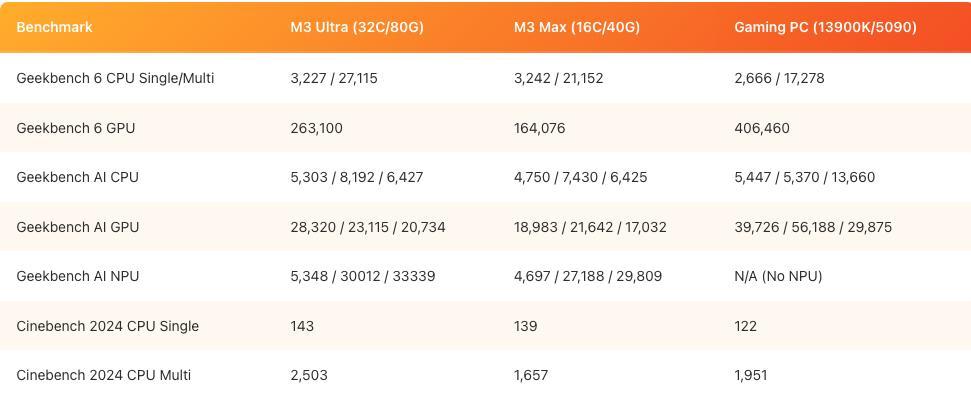
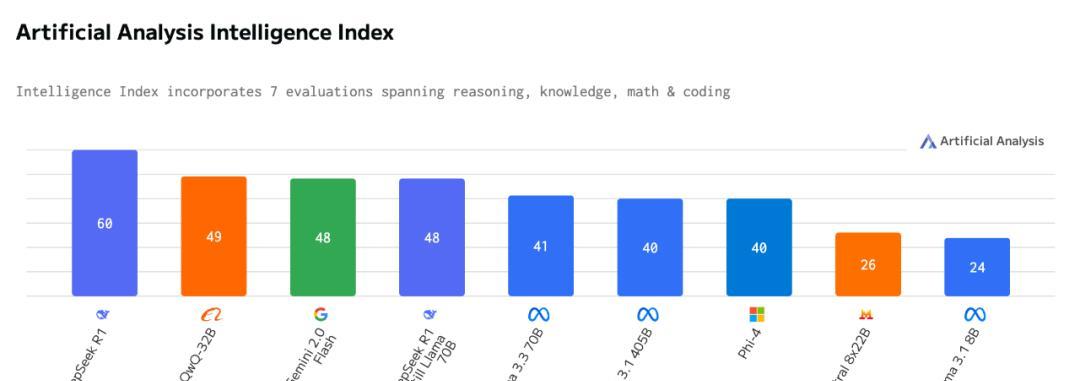
当然,直接买H100或AMDInstinctGPU,运行速度确实更快,但价格至少是MacStudio的6-80倍!而且多数人最终会在云端部署模型,所以不划算!训练大模型又是另外一回事了!ExoLabs实验室正在开发基于AppleSilicon的LLM训练集群,他们更专业,未来可能会分享更多关于训练所需内存的细节!结论很简单:内存越大,体验越好!关键在于MacStudio的LLM运行表现几乎是所有桌面设备里最好的!相比其他PC,配备统一内存的MacStudio能更快地运行更强的模型,支持更大的上下文窗口。
这得益于AppleSilicon的硬件优势和Apple的MLX框架,MLX不仅能让模型高效运行,还不用提前把KV缓存放进内存里,还能快速生成内容。
当然,这次测试不是绝对公平的比较。
英伟达的Blackwell架构在数据中心和消费级AI应用上非常给力。
这次测试的重点是评估AI工作站上的LLM实际性能,结果仅供参考!所有测试都在128KToken的上下文窗口下运行。

游戏PC使用llama.cpp,Mac设备使用MLX。
RTX5090也可以运行更大的模型,但会增加延迟,没必要。
理论上,如果用上Nvidia的优化,RTX5090在Windows上的表现应该比测试结果好得多,但问题还是出在内存上:RTX5090只有32GB,而M3Ultra起步就是96GB,最高512GB!这就是AppleSilicon的优势:省心,买来就能用!MLX是目前最好的框架,苹果和开源社区都在更新它!它能完全发挥AppleSilicon统一内存的优势!RTX5090的AI计算峰值性能确实比M3Ultra的GPU强。
但在单机环境下,CUDA和TensorRT反而成了限制。
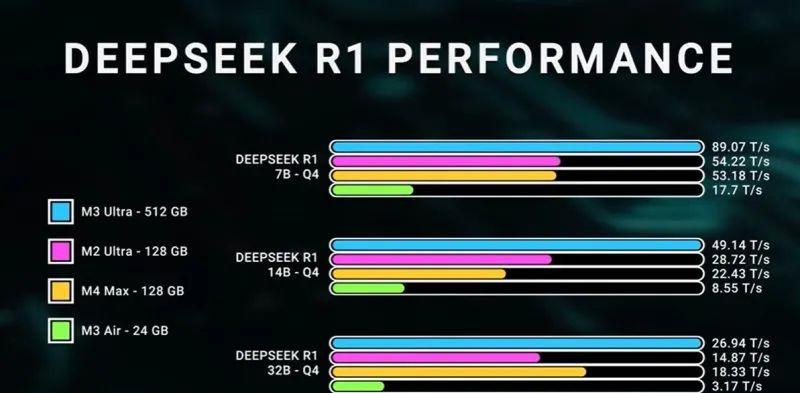
在数据中心里,CUDA和TensorRT是无法取代的!MaxWeinbach觉得,开发者最好用M3UltraMacStudio配合数据中心租用的8张H100服务器!Hopper和Blackwell适合服务器,M3Ultra适合个人工作站!MaxWeinbach表示,虽然对比这些设备很有趣,但实际上,它们都有优点,不能互相取代!YouTube博主DaveLee用512GBMacStudio跑起了DeepSeekR1。
这个6710亿参数的模型占了404GB空间,需要超高带宽内存,通常只能靠GPU的专用显存(VRAM)扛住。
但M3Ultra的统一内存架构把这部分需求放进了系统内存里,低功耗下实现了挺好的效果。
DaveLee做了对比测试。
跑这么大的模型,传统PC方案通常需要多块GPU和超大显存,而M3Ultra单芯片就能高效运行!DaveLee强调,跑小模型时M3Ultra还有空间,但DeepSeekR1必须用512GB内存版本!macOS默认限制了VRAM分配,DaveLee把可用VRAM提升到了448GB才成功跑起来!
最终,DeepSeekR1在M3UltraMacStudio上的效果比想象中好!虽然用的是4-bit量化版本,牺牲了点准确度,但模型保持了完整的6710亿参数,速度为16-18tokens/秒!其他平台需要多块GPU才能达到相同性能!M3Ultra的优势在于能效,整机功耗不到200W!如果用传统的多GPU配置,耗电量至少是M3Ultra的10倍!DaveLee觉得M3Ultra的AI计算能力厉害多了!MaxWeinbach认为,目前市场上根本没有能与MacStudio相提并论的AI工作站!
对此,你怎么看?
