都说DIY已死,其实说的是在“摩尔定律”作用下硬件提升已经达不到玩家预期,再加上各大半导体厂商们转战数据中心等B端业务无暇顾及玩家,DIY市场已经很久没有令人耳目一新的新鲜玩意了,时下流行的RTX40、RX7000系列显卡也已经是一年前将近两年的产物了。
而正当玩家们被RTX50系列显卡屡次跳票而折磨的热情殆尽,英特尔却突然发布了锐炫(Arc)系列独显的第二代——Arc B系列显卡,而我们也拿到了目前第一批解禁的Arc B580主流甜品显卡,据英特尔称这可是抢占主要出货量2000元价位段的强力选手,看看英特尔经过沉淀,交出的答卷是否会让玩家们满意。

当然,单就一块显卡自然不会让我们如此感兴趣,毕竟在当下,DLSS、FSR、AI等“黑科技”的加持,在体验上可比纯光栅堆料来得更让玩家满意,毕竟买硬件的钱已经花了,附送的黑科技那可是纯送的。
所以英特尔作为新时代独显的后起之秀,自然深谙此道,随Arc B580一同公开的还有新的Xe2架构以及XeSS-SR、XeSS-FG以及XeLL等新技术,这篇评测我们也会对这些“新事物”来一个测试,看看表现如何。
Xe2新架构——不断优化迭代的显卡生命力
首先不得不先介绍一下Arc B580搭载的新核心——Xe2,对于上一代Xe-HPG核心而言,这一带Xe2核心主要在矢量引擎效率、光追单元迭代、更广泛的算力覆盖进行更新。

在Xe2核心规格方面,升级的重点围绕资源分配调度上,比起强行拔高单元数量,在我们看来,英特尔选择将传统的XVE矢量计算单元进行整合,在总宽不变的情况下“合二为一”,以减少频繁调度带来的性能和功耗开销,同时也为后续迭代升级提供了更宽泛的冗余。
在这一代上,矢量单元由A系列的每核心16个优化为8个,而宽度翻倍达到512bit,XMX计算单元同样“合二为一”,每核心配给8个,同样位宽翻倍为2048bit,除此之外,在每核心独享的L1缓存方面,也由上一代Xe-HPG的192KB升级为256KB。

“拆开”XVE引擎能够发现,这一带除了支持单指令并发16数据流的SIMD16之外,还支持扩展至SIMD32,灵活的数据流处理能够适配更多奇形怪状的任务,相比上一代而言更加灵活。
而灵活的还有XVE引擎对多种不同精度的支持,目前的XVE已经能够支持诸如INT2、INT4、INT8、FP16、BF16、TF32甚至FP64等精度需求,这在AI应用五花八门的消费端极为灵活。

光追单元同样也是此次Xe2升级的重点,不仅用于遍历光线的管道数量增加至三条,用于碰撞检测的Box intersectio增加至总共18条,而用于检测光线与像素相交的Triange intersectio升级至2条,BVH缓存也提高两倍达到16KB,可见英特尔在这代的光线追踪上下足了猛料。

Arc B580上搭载的这块名为BMG-21的SoC除了Xe2以及新光追单元外,其余组件相比上代Xe-HPG而言变化并不大,具体配置规格各位可以看图了解。

在经过以上升级后,英特尔宣称37款游戏的平均代际提升达到夸张的70%以上,同时每瓦性能也相应提升50%,可见对于架构优化对于Xe核心的潜力挖掘十分到位。

XeSS2——游戏“黑科技”如何达成三足鼎立?
以往我们在谈论XeSS这个功能时,往往指代的是针对英特尔Xe系列独显、核显的超分辨率加持,但玩家们都知道,目前市场上另外两家显卡巨头Nvidia和AMD都有着集超分辨率、帧生成、低延迟组成的一整套游戏组合拳,但现在,XeSS2的推出正式补齐了英特尔显卡的这个短板。
XeSS2技术包含以往的XeSS超分辨率(现称XeSS-SR)、XeSS-FG帧生成,以及XeLL低延迟,在这一整套的技术加持下,能够实现不输友商的游戏帧率、延迟加成。

这里我们着重讲解一番XeSS-FG技术,与Nvidia相似的是,英特尔的XeSS-FG同样借用了AI的能力,借助Xe2核心内的XMX单元对每帧数据进行AI分析,并输出生成帧与原始帧进行混合,达成极尽丝滑的游戏体验。

在结合XeSS-SR超分辨率以及XeSS-FG帧生成后,不少游戏都能实现最高达3.9倍的性能提升,显然根据以往的经验来看,玩家们能用两千元显卡实现接近旗舰或次旗舰卡的性能,对于产品力而言是一种巨大的提升,相信XeSS2的出现会成为Arc B580征战市场的核心卖点。

XeLL低延迟技术则从传统游戏渲染工作流入手,从系统层面减少每帧数据流转的等待时间,从下图可以看到,在XeLL驱动级别的优化下,每帧工作周期被缩减,尽可能的最快送达显示器,这对不少FPS、动作类玩家而言可是一个必选项。

在英特尔给到的数据中可以看到,在《F1 24》这款游戏中,在单独开启XeLL后能实现45%的延迟降低,尤其是在配合XeSS-FG以及XeSS-SR提升帧数后,能够同时实现帧率的暴涨和延迟的大幅降低,这对电竞微操选手而言显得尤为重要,我们也会在接下来的测试中用自己的测试平台验证这一点。

ARC生态——配套软件打通游戏AI
当然,除了XeSS2这一巨大看点外,英特尔针对日益盛行的AI推出了基于Arc打造的AI软件平台——AI Playground,简而言之,这是一套完整的覆盖RAG知识库问答、端侧LLM以及文生图及图生图的平台,除了进行简单的AI体验,首次支持ComfyUI也是一大亮点,毕竟目前ComfyUI是能够切实可用的高灵活度AI工作平台,以往需要较强的专业知识才能驾驭的平台,这次伴随英特尔的新显卡一同实现了开箱即用。

当然,新显卡新气象,新的显卡控制平台除了实现以往的显示器颜色控制外,还紧跟步伐推出了一整套的显卡技术开关、超频控制、性能监控、游戏情景设置档等完整功能,能让玩家仅靠一个软件就能掌握所有有关图形的控制,可以说到这一步,英特尔的独立显卡在市场中已经具备完整的竞争力。

除我们拿到的Arc B580之外,英特尔还展示了另外一款SKU,Arc B570,在微架构上同样采用Xe2核心,只是相较Arc B580而言缩减了两组Xe核心,频率有所下调,显存位宽相应设置为160bit。

在性价比方面,Arc B580的直接竞争对手为RTX4060以及RX7600,但要论同性能,似乎与RTX40600Ti掰一掰手腕才显得更象样些,毕竟从图中可推断出Arc B580纯光栅性能要比RTX4060Ti好上一些,要知道后者目前全新售价依旧维持在三千元左右,这一千元的差价确实相当离谱。

英特尔家传的“厚到”公版卡设计
回到显卡本体,与以往A系列显卡采用蓝戟制造不同,这块Arc B580则是纯纯的公版显卡,整体设计圆润,没有多余的元素点缀,外壳材质极其细腻,难得的是对于主流甜品卡而言,类肤质的触感显得尤为特别,怪不得自古DIY老炮都喜欢收藏一块各家的公版卡,特殊的设计确实值得收入囊中。

得益于新显卡的架构进步,显卡采用了背板开窗透吹设计,由此可以推断出这块Arc B580对于供电的需求并不高,所以才能采用极小的PCB扩展出豪华的透吹设计,这下更好奇这块显卡的散热表现了。

接口这块,Arc B580搭配三个DP接口及一个HDMI接口,其中除第二个DP接口为支持UHBR13.5标准的54Gbps高速率接口,在外观上有一层金属包边用于保持信号完整性,对于甜品卡而言这个接口过于奢侈,我们猜测是为后续更高规格的旗舰显卡铺垫,HDMI接口则是支持2.1标准。

那么话不多说,进入久违的评测,前文说过,虽然英特尔将Arc B580视为RTX4060以及RX7600的竞争对手,但实际上我们觉得以RTX4060Ti作为性能参照更能表现出这一代Xe2核心的性能,所以我们也是找来一块RTX4060Ti 8G作为陪跑选手。
实测基准
测试平台如下,系统及驱动均更新为测试时最新版本:
主板:ROG STRIX Z790-A GAMING WIFI
CPU:英特尔酷睿i9-14900K
内存:Kingston FURY DDR5 7200 16Gx2
硬盘:Crucial T700 Pro 1TB PCIe5
电源: 长城(GreatWall)巨龙1250DA
显示器:EVNIA 27英寸 4K 160Hz FastIPS
操作系统:Windows 11 Pro 24H2

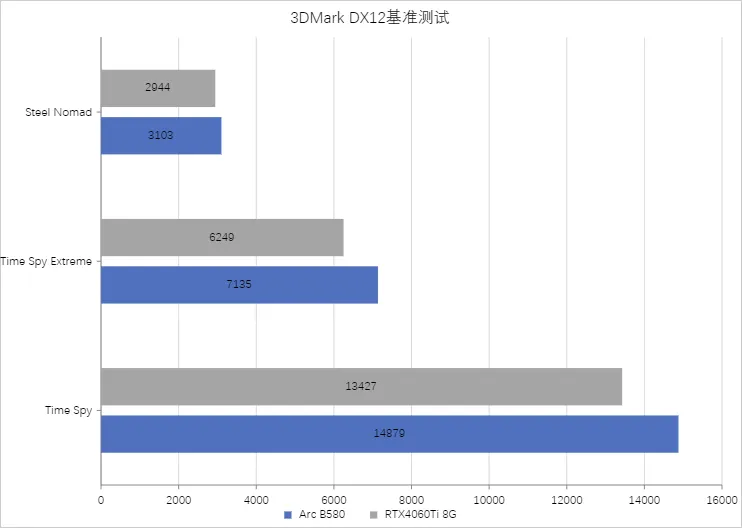
理论基准测试,3DMark DirectX11下,Fire Strike在1080P、2K、4K三种负载下,Arc B580均与小幅度领先RTX4060Ti,果然前文我们的推测并没有失误,Arc B580的直接挑战选手正是RTX4060Ti,而不是相似价位段的RTX4060。

在DirectX12中,Time Spy的表现也符合预期,其中2K分辨率拿下14879分,也是领先了RTX4060Ti一千多分,并且在全新的Steel Nomad测试中,评分也超过RTX4060Ti,由此可以直接下论,Arc B580的纯光栅性能要比RTX4060Ti更加优秀。
由于这次加入了XeSS-FG帧生成,所以同样是用于提升帧率的技术,我们就使用3DMark中的XeSS测试套件以及DLSS测试套件计算出两块显卡的帧数提升比率,比率越大则代表相同原始帧数标准下提升的越大。可以看到,两家的技术水平可以说不相上下,要知道XeSS-FG作为刚刚出炉的新技术,能够比肩友商已经成熟了几年的积累,实属不易。

光线追踪测试使用Port Royal进行,虽然Arc B580大幅度升级了自家的光线追踪单元,但对于雄踞此领域的霸主英伟达而言,仍旧占不得优。不过相差不大,不知道后续英特尔能否通过驱动更新的方式让Arc B580超过RTX4060,我们也会随时关注。

AI部分,这一向是拥有完整CUDA生态的N卡主场,不少基础框架设施都是基于此打造,在这块英特尔可谓是吃尽了苦头,所以Arc B580即便是优化了AI计算,在Procyon AI统一的WindowsML基准中也未能占据上风,不过有意思的是,在基于实际Stable Diffusion生图的基准测试中,Arc B580的效率却要比RTX4060Ti更加优秀,猜测是大显存的作用让Arc B580补齐了这一短板,毕竟面对英伟达的“显存霸权”,不少AI开发者都会选择退而求其次降低效率而减少显存需求,而放在大显存的Arc B580上,恰好能完全发挥核心的计算能力,所以这一环节胜出倒也并不意外。

实际游戏测试我们选取了三类,一是著名的3A大作,如《赛博朋克2077》等,二是最新热门游戏,如《三角洲行动》,三是常青藤网游《永劫无间》之类。
1080P分辨率全最高画质,不开启XeSS/DLSS,不启用光线追踪,可以看到Arc B580在纯光栅比拼下要领先RTX4060Ti,领先幅度不一,领先均在10%到20%之间,但尤其以外的是,在《黑神话:悟空》影视级画质下Arc B580没有发挥出应有实力,显然英特尔显卡团队还未对该游戏进行完美的适配,

2K分辨率下,显卡压力显现,但结果依旧证明Arc B580仍旧领先RTX4060Ti,即便是在3A大作《赛博朋克2077》以及《霍格沃兹之遗》中,领先幅度也能超过10帧以上。

光线追踪游戏测试我们选取效果最明显的《赛博朋克2077》,不单测试帧数,我们还对比了在开启路径追踪情况下,Arc B580和RTX4060Ti的画面表现又有何区别。
在开启路径追踪的情况下,Arc B580无论是1080P还是2K均不能满足畅快游玩的水准,但如此高的压力下即便是旗舰如RTX4090也相当有压力,至少Arc B580还能获得36帧的成绩,已然不错。这里还是推荐玩家们使用2K分辨率开启低档位光追同时保证画质和体验。

画质对比上,即便是在超级画质选项,与路径追踪也不能相提并论,路径光追所带来的光线折射渲染出的氛围感及真实感确实在Arc B580上体现了出来,对比RTX4060Ti的画面来看别无二致,由此可见Arc B580改进升级的光追单元在提升性能的同时,并未对画面体验做出妥协,这已经是完全可用的状态。

XeSS帧生成功能我们使用《F1 24》游戏进行,并且采取了分别叠加测试,看看XeSS2对提升帧数的极限在哪儿。
默认2K最高画质下,《F1 24》为了体现出F1赛车真实的光影折射和后视镜画面,是默认开启光线追踪的,所以最高画质下对显卡的压力极大,导致Arc B580在此只能夺得39帧的成绩,想要畅玩自然需要XeSS的加持,单独开启XeSS-SR超分辨率质量档,帧数维持在59帧,显然距离畅快玩还有一定距离,虽然在开启性能档后能够达到87帧,但画质损失就比较严重了,不过在XeSS2新功能XeSS-FG的共同作用下,超分辨率仅需要开启到质量档就可以137帧运行,帧数提升巨大。

当然,XeLL我们也做了单独测试,测试使用英特尔官方的PresentMon进行,在不开启XeLL时Display Latency(从接受操作指令到渲染画面传达至显示器的耗时)需要将近100ms左右,五倍于人类反应时间,这对竞技游戏而言尤其致命,此时即便是FastIPS或者VA显示器都无法弥补。

在驱动中开启XeLL低延迟选项,游戏中不开启XeSS-SR以及XeSS-FG,此时同一画面下Display Latency被压制到70ms左右,当然,由于极高画质带来的渲染压力,Arc B580仍旧需要在约40FPS下保底占用25ms左右渲染画面,那么此时不妨换个思路。

全开XeSS2全部功能,在超分辨率以及帧生成加持下,平均帧137,由此可以看到Arc B580的保底渲染耗时已经降低到8ms左右,再叠加XeLL低延迟优化,此时整体的Display Latency也来到30ms左右,对比初始的100ms左右而言,快了接近四个反应周期,这正是FPS、动作游戏玩家们梦寐以求的。

此外,我们也按照惯例简单实测了Arc B580在视频编解码上的性能表现,测试使用H.264解码,再转为AV1编码,样本使用长度2分8秒的HDR视频,分辨率3840*2160,码率为23Mbps。
在纯软件解码下,128秒的视频需要247秒进行转码,对于高码率推流、在线转码播放中压力显然极大,但在启用Arc B580进行硬件加速后,仅需要66秒即可完成,这对视频工作者而言倒是个不错的选择,并且有着英特尔积累已久的核显加速Buff,软件适配上倒是没有AMD这样抓马。

AI应用方面,我们首先尝试了更脍炙人口的Stable Diffusion整合包,在整合包仓库主线下,可以看到已经支持了IPEX,IPEX全称为Intel Extension for PyTorch,是英特尔针对PyTorch框架进行专门优化的“英特尔版PyTorch”,而基于PyTorch打造的Stable Diffusion正是该框架的用武之地。

得益于12GB大显存的支持,我们不需要针对低显存而刻意降低性能,在进入WebUI后,生成一张512*512大小的Demo,迭代20步仅用时3.3秒,并且显存并未全部占满,可见对于Arc B580而言,玩AI已经没有任何问题。

当然,我们也测试了英特尔提供的AI Playground工具,该工具集成了文生图、图生图、端侧LLM、RAG问答等成熟的AI应用,并且不需要向其他AI工具一般使用命令行部署,而是打包为了应用程序,真正做到开箱即用,极为便捷,并且在官方项目页面上,英特尔也分别推出了针对Lunar Lake、Arrow Lake以及Arc独显的AI Playground工具。

不过值得吐槽的是,英特尔虽然提供了一整套工具以便开箱即用,但AI大模型则需要特殊手段才能获取,如若不是专业人士,那么使用的门槛在这一步会被拉得很高,这里不妨建议英特尔将常用模型创建至国内CDN节点,走完AI大众化的最后一步。这里由于网络环境极差,我们尝试多次均以下载失败告终,遗憾未能第一时间体验到这一工具。

当然,在聊完显卡的各项功能和体验之后,实际上机兼容性又如何?
经过实测Arc B580在满载时功耗维持在190W附近,对于大部分普通玩家而言,搭配一个600W以上的电源就足够使用。
而在机箱的挑选上,双槽显卡配合小幅度越肩,兼容性无疑很高,极限一些的ITX主机也能胜任,且最关键的风道配置上,由于紧凑的PCB设计带来的极大散热接触面和散热效率,核心温度仅68℃,而外在最高温度为55℃,对于一些极限的ITX而言也能适配。

说到兼容性,虽然我们测试使用i9-14900K进行,但实际使用上我们更推荐搭配上两代主流CPU i5-13490F,一是作为上两代处理器,目前随着Arrow Lake面世而价格降到了冰点,二是相比i5-13400F而言,价格相同的同时在单核睿频、缓存等方面有着不小升级,这恰好是游戏所需要的,那么既然选择了2000元价位内最有性价比的Arc B580,为何不选择更有性价比的i5-13490F与其搭配呢?

EF点评:
如果说上一代Arc A系列有着不一样的短板,那么这一代Arc B系列则完全补齐了这些遗憾,全套XeSS2技术的发布、硬件本身规格的提升优化、AI功能的完善,再加上极富诚意的性价比,可谓是盘活了今年萎靡的显卡市场,当然,保持期待,毕竟更高级别的B700系列Arc相信不久之后还会给我们惊喜。

