

OpenAI还能走多远?

近日ChatGPT迎来了“历史性”的升级。
OpenAI首席执行官奥尔特曼在周二的直播活动中表示,正式推出基于GPT-4o模型的原生图像生成功能——模型直接从文本提示生成图像,不再调用独立的DALL-E文生图模型。

ChatGPT终于没软肋了?
这下OpenAI终于能在一众同行中抬起头了。过去,文生图能力一直是ChatGPT的一大痛点。
ChatGPT于2022年底上线,最初只能进行文字聊天。大约一年后,OpenAI发布第三代图像生成模型DALL-E,并集成到ChatGPT,但两者一直是互相独立的系统。在最初的新鲜感过去后,AI图像生成器“理解提示词能力差”,特别是“无法准确生成图片中的文字”严重阻碍这项功能在教育、职场等领域的应用。
随着今年阿里巴巴、谷歌先后推出能准确生成文字的文生图模型,OpenAI终于补上这个短板。
利用GPT-4o的多模态能力,ChatGPT在图像生成时能更加精确地遵循指示、更精确地渲染图像上的文字,同时支持多轮迭代优化图像时保持角色形象一致。
在周二的演示中,OpenAI展示了新一代ChatGPT的图像功能升级到了何种程度。
ChatGPT已经能够大致准确地按照提示词,生成图像中的文本。在演示中,AI成功按照要求生成一整页的讲话文本,同时没有出现错别字。
奥尔特曼感慨称,能在图像生成功能中完美呈现文字本不应该是那么令人赞叹的事情,但我们却等了这么久。
从官方给出的更多示例来看,不管是生成黑板板书,还是印刷体、展示科学常识的绘图,ChatGPT在生成图像文字领域终于从完全不能用,达到接近商用的程度。
同时,ChatGPT的图像编辑功能,也变得更加有用。
结合GPT-4o的知识库和终于能把字写清楚的能力,ChatGPT也能通过简单的提示词,生成有关相对论的漫画彩图。
GPT4o也可以根据聊天上下文的基础来生成图片和文字,所以生成的一系列图像将具有一致性,这对于设计游戏角色而言相当重要。
OpenAI承认,新的图像生成器也存在一些局限性,例如也会受到模型幻觉影响,同时在密集文字和非拉丁语文字的图像生成方面,也更容易出现问题。
从周二开始,基于GPT4o的图像生成功能向所有免费和付费用户推出,未来几周内开发者将能通过API调用这项功能。
OpenAI失速
产品更新发布后,奥尔特曼随即发了一条推文,讲到“这代表了我们在允许创作自由方面的一个新高水位。正如我们在模型规范中提到的,我们认为将这种知识自由和控制权交到用户手中是正确的做法,但我们将观察其进展并听取社会的意见。我们认为,尊重社会最终会为人工智能设定的广泛界限是正确的,而且随着我们越来越接近人工智能,这种尊重也变得越来越重要。”
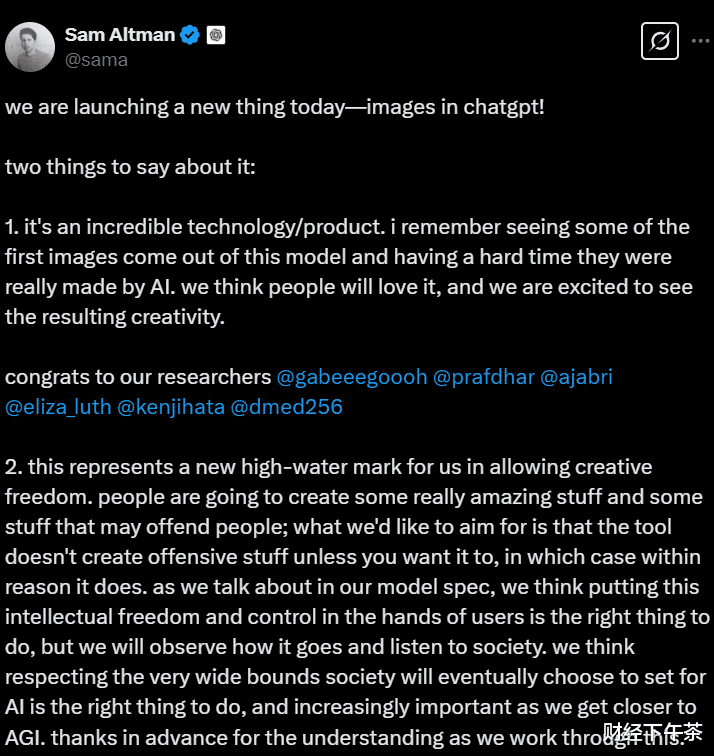
图片来源:社交媒体
尽管奥尔特曼在很努力地给此次更新“上价值”,但从评论区看,用户难言“买账”。
有的用户质疑,这项功能更新和原有的DALL-E有何区别,还有的用户艾特Grok,想让Grok证明下它比ChatGPT更优秀。


图片来源:社交媒体评论区
尽管不排除网友们在玩梗搞怪,但此次更新,在网络上并未掀起波澜却也是事实。
国内网友直接评价“从领跑变成了跟跑”。

图片来源:东方财富评论区
这确实符合当下很多人对OpenAI的印象。一方面自然是受到了中国大模型快速发展的冲击,让原本在舆论环境中一骑绝尘的OpenAI不再那么具有优势。另一方面,也是OpenAI的发展的确慢下来了。
看看ChatGPT的版本列表:
2022年底,GPT-3.5爆火,大众了解到ChatGPT;
2023年3月14日,GPT-4发布掀起新一波热度;
时隔一年,2024年5月13日,GPT-4o发布,该模型比其前身GPT-4快两倍,而价格仅为其50%。
2025年2月27日,GPT-4.5,媒体却已不再兴奋。
外媒记者凯德·梅茨表示,该模型“标志着一个时代的结束”,并认为其“难以再现GPT-4发布时的热度”。
曾任职于OpenAI的加拿大计算机科学家安德烈·卡帕斯声称,该模型“表现略好”,但具体优势“并不容易明确指出”。
原计划2024年就发布的GPT-5,如今遥遥无期。奥尔特曼,也不再是各大媒体报刊头版头条的常客。
事实上,GPT-5难产的原因,也正是OpenAI疲软的原因。目前,市场普遍认为,GPT-5难产或与以下因素有关:
一是数据缺口巨大。研究机构Epoch研究人员Pablo Villalobos估计,GPT-4是在多达12万亿个token上训练的。他表示,基于Chinchilla缩放定律的原理,如果继续遵循这样扩展轨迹,像GPT-5这样的AI系统将需要60万亿-100万亿token的数据。因此,数据将成为大模型发展的重大瓶颈。
二是训练费用高昂。马斯克估算,GPT-5的训练大概需要3—5万张H100芯片,芯片成本就超过7亿美元。按照市场估算,一次6个月的训练需花费5亿美金训练费用。训练GPT-4的成本超过1亿美元,未来人工智能模型预计将超过10亿美元。
三是算力瓶颈。GPT-5参数量是GPT-4的10倍,需要强大的算力支持。而英伟达新一代GPU芯片GB—200难产,OpenAI只好与博通合作开发新型AI推理芯片。
四是高层人才流失。自2024年初以来,至少有8位高管离开了OpenAI,包括前首席技术官米拉·穆拉提、前首席研究官鲍勃·麦克格卢等,这些高管纷纷离职,直接影响OpenAI的研发进度。
OpenAI仍然是人工智能领域的第一梯队,但领先优势已经不那么明显了。
国内AI厂商马不停蹄
削弱OpenAI声量的,不只是OpenAI自身,还有国内发展迅猛的各大模型厂商。
仅这一周,国产大模型领域就热点频出。
3月24日消息,有媒体报道,蚂蚁集团CTO、平台技术事业群总裁何征宇带领Ling Team团队,利用AI Infra技术,开发了两个百灵系列开源MoE模型Ling-Lite 和 Ling-Plus,前者参数规模168亿,Plus基座模型参数规模高达2900亿。
同时,论文显示,蚂蚁团队在模型预训练阶段使用较低规格的硬件系统,将计算成本降低约20%,达508万元人民币,最终实现与阿里通义Qwen2.5-72B-Instruct 和 DeepSeek-V2.5-1210-Chat相当的性能。
3月25日晚,DeepSeek官方账号正式宣布V3模型完成小版本升级。另据海外专业AI模型评测机构最新排名,新版V3模型现在是得分最高的非推理模型,超过xAI的Grok3和OpenAI的GPT-4.5(preview)。
据中国工信部官方消息,目前,中国已成为全球开源参与者数量排名第二、增长速度最快的国家。另有数据显示,阿里通义开源模型的衍生模型数量已突破10万个,成为全球最大的开源模型族群。
这些都印证了前面网友说的“从领跑变成了跟跑”。
之所以能形成当前的格局,一是因为算力领域的发展不及预期,前面也说了英伟达的GB—200难产。
另一点则在于,当前“一力破万法”的大模型发展道路遇到瓶颈。参数越多越智能、参数越多越好用吗?应该是不绝对的,起码DeepSeek的部分成功,证明在堆算力之外,还有其他的路径可走。
结语
ChatGPT的发展无疑是慢下来了,但这也给了国产大模型迎头赶上的机会。
包括OpenAI在内,几乎所有的AI公司,都还没有真正建立其护城河,距离推出所谓杀手级应用或许也还为时尚早。
这场大模型之战,将如何落下帷幕,让我们拭目以待。
欢迎在评论区留言交流~
免责声明(上下滑动查看全部)
任何在本文出现的信息(包括但不限于个股、评论、预测、图表、指标、理论、任何形式的表述等)均只作为参考,投资人须对任何自主决定的投资行为负责。另,本文中的任何观点、分析及预测不构成对阅读者任何形式的投资建议,亦不对因使用本文内容所引发的直接或间接损失负任何责任。投资有风险,过往业绩不预示未来表现。财经下午茶力求文章所载内容及观点客观公正,但不保证其准确性、完整性、及时性等。本文仅代表作者本人观点。
