小明最近在和朋友聊天的时候,突然提到了一件他觉得很有趣又有点疑惑的事。
他说:“你听说过DeepSeek-R1吗?
怎么感觉这些大语言模型一会儿一个新名字啊?

我一直搞不懂这背后的故事,为什么这些模型会变成现在这样?”朋友们听完都愣了一下,然后七嘴八舌地开始讨论起来。
听到这些,我决定写一篇关于大语言模型发展历程的文章,从2017年的Transformer到最新的DeepSeek-R1。

我们先回到2017年,那时的自然语言处理技术还没有现在这么厉害。
那个时候,想要让机器理解人类语言并不容易。

早期的很多模型如循环神经网络(RNNs)和长短期记忆网络(LSTMs)虽然有些效果,但在处理长句子和复杂依赖关系时常常表现得很吃力。
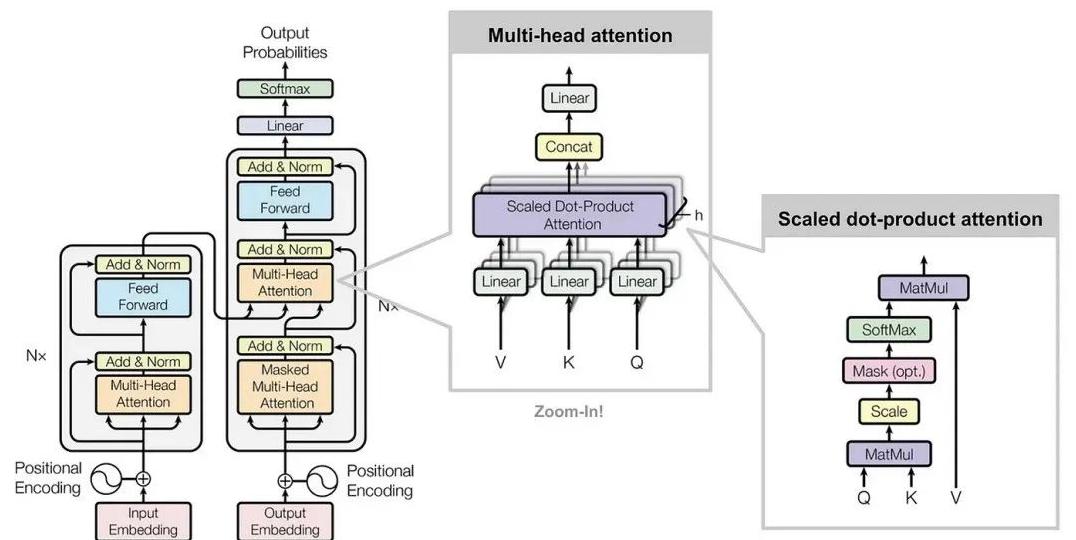
就在这时候,Transformer架构出场了。
Transformer架构是由Vaswani等人提出的,通过一种叫“自注意力机制”的方法,解决了之前模型的一些瓶颈。

这个机制允许模型在处理长句子时,能够有效地捕捉全局和细节信息。
其实简单来说,Transformer可以理解一整篇文章中的“来龙去脉”,不需要像过去那样一个词一个词地处理。
这一创新为之后的大语言模型奠定了坚实的基础。

在2018年到2020年之间,预训练模型迎来了它的“黄金时代”。
其中两个明星模型是BERT和GPT,这两个模型在自然语言处理的不同任务上都取得了令人瞩目的成就。
BERT的全名是“Bidirectional Encoder Representations from Transformers”,顾名思义,它是基于Transformer架构的。
BERT的创新在于它能够双向理解文本。
这是什么意思呢?

也就是说,它可以同时从前往后和从后往前看句子,从两边获取信息。
这让BERT在很多任务上的表现都非常出色,比如问答、文本分类和命名实体识别。
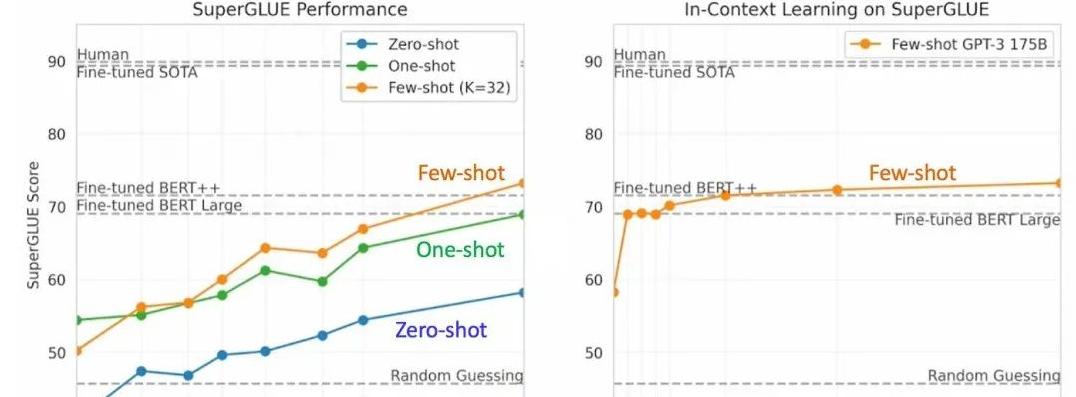
而OpenAI发布的GPT系列,则是另一个重要的突破。

GPT模型的核心是通过大量数据的训练,学会生成自然的、连贯的文本。
GPT模型从第一个版本开始只有亿级参数,到2019年发布的GPT-2已经有15亿参数,而2020年的GPT-3更是直接飙升到1750亿参数。
这不仅让它在生成文本、回答问题等任务上表现优异,还具备了在无监督学习下处理任务的能力。

时间来到2022年,OpenAI发布了新的版本——ChatGPT。
这一版本不仅继承了GPT-3的大部分能力,还在对话生成和多轮交互上有了明显的提升。

ChatGPT能够更自然地进行对话,这也标志着人工智能在与人类交流方面迈出了重要一步。
不仅如此,2023年到2024年间,多模态模型进入了人们的视野。
所谓多模态模型,就是说它不仅能够理解和生成文本,还能处理图像、音频、视频等不同类型的数据。
比如2023年发布的GPT-4V,它能够同时解释语言和图像,回答基于图片的问题。
这为医疗、教育等领域的应用带来了新的可能性。
DeepSeek-R1:2025年的下一代语言模型
说到DeepSeek-R1,这是2025年初推出的具有高性价比的语言模型。
这个模型一发布,就引起了AI领域的巨大轰动。
DeepSeek-R1不仅能力超群,还能够以较低的成本进行训练和推理,这在过去是不可想象的。
DeepSeek-R1最特别的地方在于它采用了一种称为“专家混合架构”(MoE)的技术。
简单来说,这个架构可以让模型在处理不同任务时调用特定的“专家”,每个专家都擅长处理某一类问题,比如数学、编程等。
这样一来,不仅提高了效率,还极大地降低了成本。
DeepSeek-R1的开源设计也是一大亮点。
开源意味着更多的人和公司能够使用、改进它,推动AI技术的普及和创新。
这与过去一些闭源模型形成了鲜明的对比。
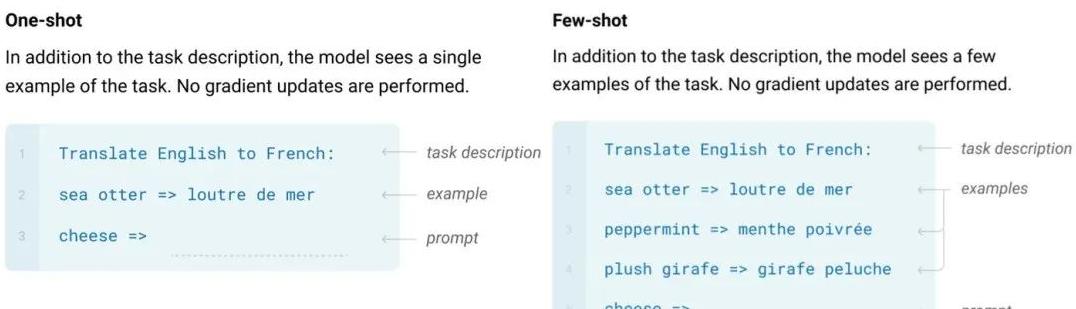
文章到这里,大语言模型的发展脉络已经基本清晰。
从2017年的Transformer,到2018年和2020年的BERT和GPT,再到2022年的ChatGPT和最新的DeepSeek-R1,我们见证了AI技术的不断进化。
结尾的时候,或许我们可以思考这样一个问题:随着技术的快速发展,未来的大语言模型会走向何方?

或许有一天,AI不仅能理解我们的语言,还能真正理解我们的情感和思维。
这个问题不仅关乎技术的发展,更关乎我们对未来生活、工作和人类本身的思考。
未来的大语言模型,或许不仅仅是一个工具,而是我们生活的一部分。

希望这篇文章能带给你一些思考,也让我们一起期待技术给生活带来的新改变。
