周末DeepSeek扔出了王炸——首次披露了成本利润率等关键数据。
DeepSeek用226台H800服务器,日赚409万,而成本是63万元——每天租用GPU的花费是8.7万美元(假设每小时2美元)。在收入上,如果所有用户按最高定价(R1模型)付费,一天能赚56.2万美元,成本利润率高达545%。

当然,实际收入没这么多,因为只有部分服务实现了商业化,但这个已经足够震撼!基本免费的DeepSeek就开始赚钱了,而世界最贵的OpenAI却在巨额亏损。
这个利润率直接把行业天花板捅了个窟窿。更猛的是,他们推出的“DeepSeek一体机”一夜爆火,朋友圈刷屏、企业疯抢。

这意味什么?带来了什么影响与冲击?
首先,这意味着算力可以像水电气网一样,成为国内的基础设施。
过去几年来,虽然从地方政府到运营商,都买了大量的卡作为基础设施,但并没有像水电气一样,实现“拧开龙头就有”的作用。
而AI大模型实现了,因为DeepSeek的利润神话,靠的是极致的技术优化:大规模跨节点专家并行,计算通信重叠、GPU 分配均衡的计算负载、通信负载,把AI模型拆成多个“专家”,分散到不同GPU上处理,通过算法让每块GPU的“工作量”平均分配,避免有的累死、有的闲死——白天业务忙的时候,就把所有节点都用来做推理服务;晚上业务少了,就减少推理节点,把这些节点拿去做研究和训练。
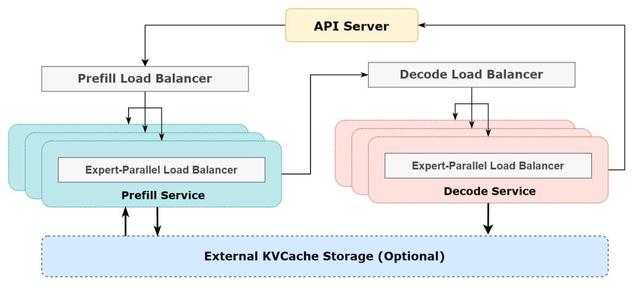
Token是消耗算力的代表,是用户看得见的水电气,而Token成本本身的透明+token成本可以通过市场竞争和技术进步实现成本预期的大幅下降,在此环节之下的形态都打通了。
这带来的第二个影响就是DeepSeek一体机卖疯了。
各地方开始采购算力一体机,中石化、三大运营商纷纷入场,用一体机分析石油数据、优化通信网络,利好华为昇腾、国产GPU芯片等。
一体机是专为人工智能大模型应用和部署而设计的集成计算设备,可以把一体机看做是一台电脑、手机一样的机器,企业/个人买回来可以直接开箱即用,帮助企业和个人进行 AI 应用需求的一台设备。
对于中小企业来说,传统AI部署要买服务器、雇工程师,现在一体机直接打包搞定,夜间折扣价低至25%,小公司也能用上顶级AI。
这对刚刚发布最贵大模型ChatGPT4.5的OpenAI造成很大冲击。OpenAI的模型收费一直挺贵的,刚发布的GPT-4.5,API调用价格高得离谱,每100万tokens输入就要75美元,API价格暴涨30倍,和DeepSeek的正常价格比起来,贵了280倍。
到2027年,一体机市场规模将超5000亿,DeepSeek或将拿下这块蛋糕的大头。
其三,云计算大厂或成最受益方向。
DeepSeek的这种低成本模型降低了企业私有化部署的门槛,政务、金融等行业客户更倾向于通过云计算厂商的混合云解决方案实现模型本地化部署。
DeepSeek的高效模型运行依赖H800 GPU集群,而云计算大厂(如阿里云、腾讯云、华为云)通常提供GPU算力租赁服务。随着DeepSeek模型商业化落地加速,下游企业为部署AI应用将加大对云计算资源的采购,推动算力租赁市场规模扩大。例如,中国联通的“联通云”已适配DeepSeek-R1模型,提供私有化与公有化场景支持。
其四:硬件降本还会持续,对英伟达又是一记重拳
如前所述,这种模型部署方案就是把AI模型拆成多个“专家”,就像有钱人要么雇一个全科医生,要么就弄一个超大规模医院,让不同专科医生给各种人看病。
这意味着硬件上的降本还会继续,2023年1月ChatGPT刚出来,API调用的价格是0.014美元100个token,Deepseek不断优化,现在价格是0.000055美元100个token。降低了255倍。

黄仁勋此前指出,DeepSeek 为 GPU 降本,但下一代模型还离不开我。但是国外科技博主Zephyr则认为,DeepSeek已经将英伟达“击倒”。而且按照DeepSeek目前对算力的超高利用率来看,满足全球的AI需求绰绰有余。

但按照DeepSeek对算力的低性能与成本需求,国产GPU已足够了。众所周知,为了限制中国AI的发展,美国最开始是将英伟达的当红芯片A100、H100这样的芯片禁止了,后来英伟达阉割了成了A800、H800,销售给中国。后来将A800、H800也禁止了,英伟达就阉割出了H20卖给中国。
由于DeepSeek的广泛应用,中国企业对H20的需求大幅增加,根据市场分析,中国AI市场对H20的需求量可能达到315万颗,而英伟达目前的供给能力仅为约131万颗。
根据最新的消息,英伟达的H20芯片并没有完全停产,但其生产计划和销售确实受到了限制。而面对H20可能被禁售的风险,英伟达正在开发新的特供版芯片B20,预计将于2025年第二季度开始出货。
很显然,光指着英伟达卡,要么未来被贸易限制弄死,要么被同行卷死。那么用国产芯片替代H20可能会是大趋势,因为H800/H100按硬件算的毛利率超过90%,换句话说,就芯片硬件成本而言,可以降至现在的10%以内,对应的推理成本也是现在的10%以内。
目前国产芯片的租赁价格比H20还便宜不少,在比如昇腾之类的国产芯片上做类似方案的优化,也能提升使用效率,作为国内率先原生支持FP8计算精度的国产GPU企业,摩尔线程迅速响应,并在短时间内,成功实现对DeepSeek各个开源项目的全面支持。
未来的AISC化,没有中间商(芯片设计公司)赚差价。而未来的这些,应该才是国内做Infra公司的机会所在。
其五、OpenAI面临的冲击越来越大
DeepSeek能盈利,就有资金继续研发,继续推出更有竞争力的产品,545%的利润率,意味着DeepSeek在成本控制和定价策略上已经远远甩开了竞争对手。其V3模型训练成本仅为557.6万美元,远低于行业平均水平。而R1的API定价更是只有OpenAI o3-mini的1/7至1/2。这是向市场扔了一颗“价格炸弹”,让那些还在高价徘徊的AI服务提供商们感到压力山大。

事实上,Deepseek已经把open AI等AI大模型的价格体系冲烂了,目前多个欧洲初创企业已开始从OpenAI的ChatGPT转向此平台,一大批转用DeepSeek的公司已赚麻。
在这种趋势下,OpenAI靠订阅获取收益的梦想即将崩溃,所有人都要面对同一个问题?做大模型,我能做的比deepseek好么? 我的价格能比deepseek低么?
其六、星际之门计划再遭重拳
在这种连锁反应之下,DeepSeek或也将进一步冲击美国星际之门。星际之门的计划未来受阻的可能流产的可能性越来越大,星际之门本质上是用GPU资源收AI门票,在DeepSeek的冲击下,特朗普已启动主权基金计划,要拉拢一批小弟一起投钱,甚至美股七大科技巨头加大了AI算力开支,并优化算法架构,砸钱也要拉开与中国AI的差距。

孙正义近期表示,“星际之门”计划至少每年能生产10倍数量的芯片,该计划将使AI算力每年提升1000倍,几年内将爆发性增长至10亿倍。但空谈算力的背后是焦虑与需要大量资本投入。

资本市场上,幻想deepseek会被成本拖垮不得不开始大规模融资的故事,也被deepseek打脸,但如今来看,被成本拖垮的可能是星际之门堆算力的故事。
这一场国运之争,DeepSeek再度在上面加了筹码,中国已经走出了一条完全不同于美国,但效率极高的人工智能发展路径。用技术降成本,还是堆GUP割韭菜,谁才是AI的未来,答案已经越来越清晰。
作者:王新喜 TMT资深评论人 本文未经许可谢绝转载
