duckdb 是 python 中高性能分析型数据库,它里面有一套很神秘的"关系" 和 表达式函数。今天我们来盘一盘。
事情源自于一位小伙伴,它给了我一个使用 duckdb 的例子代码:
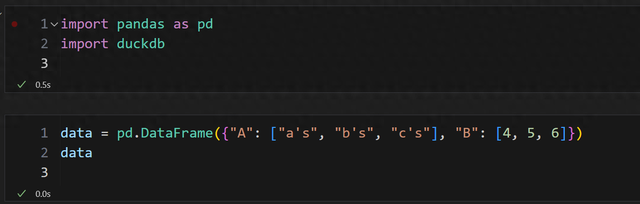
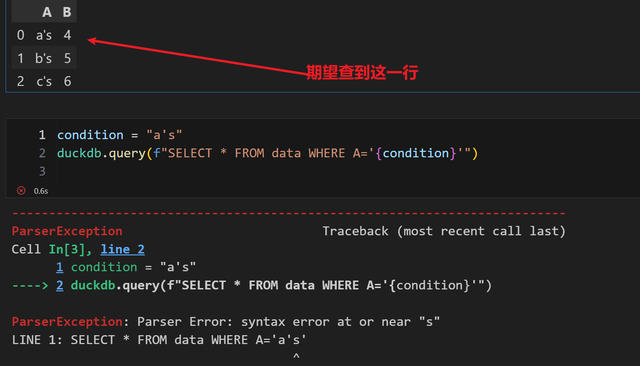
为什么执行会报错?很显然,单引号的问题,如果里面换成两个就可以表达一个单引号
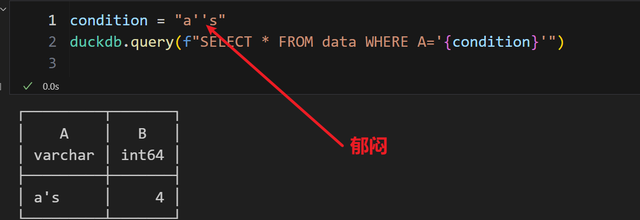
我明明就希望查询的是一个单引号的内容,却要这么写,多麻烦。
这一切的问题,全是把 sql 当作普通的文本拼接导致。
解决方法有许多。第一种是所有数据库引擎都有提供的参数化查询:
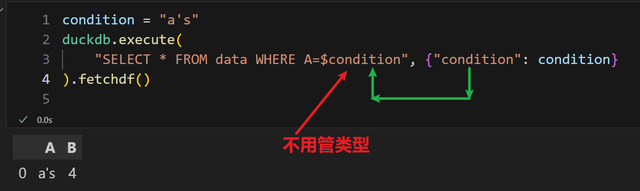 行1:注意查询内容里面只需要原文编写即可
行1:注意查询内容里面只需要原文编写即可参数化查询的好处在于,它会自行判断数据类型,类似文本需要双引号包围的问题,我们不需要操心。
不过,在 duckdb 中,使用 execute 才能使用参数化,并且要额外调用 fetch 相关方法才能得到结果。
但我更喜欢使用 query 方法,那怎么办?
duckdb 有自身实现的 sql 解析引擎。平时我们编写的 sql 文本,duckdb 会解析编译成 sql 表达式。而 duckdb 在 python 端公开了这些表达式的接口。
像这里的例子,在 sql 表达中,其实就是定义了一个常量。
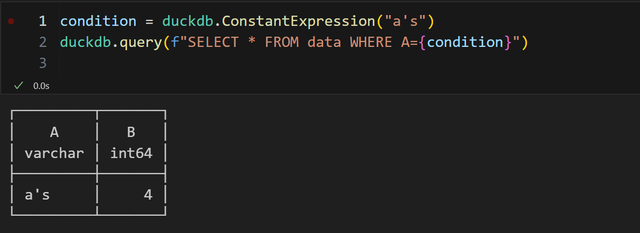 行1:通过 duckdb.ConstantExpression 把内容传进去,就得到一个表达式。
行1:通过 duckdb.ConstantExpression 把内容传进去,就得到一个表达式。其实,这玩意就是前面说到的参数化的操作。
duckdb 还内置了其他逻辑的表达式。比如:

可以看到,这些表达式对象可以覆盖几乎所有的 sql 逻辑。
当你需要动态构建各种表达式的时候,这些都是非常实用的方法。
细心的你可能会发现,query 方法返回的结果,能直接打印数据,但是结果却不是任何有效的数据类型,比如 dataFrame 等。
这就要说到 duckdb 中最有趣的"关系"函数。它可以实现类似 polars 的延迟执行的强大效果
正常使用 duckdb 加载数据,一般是:
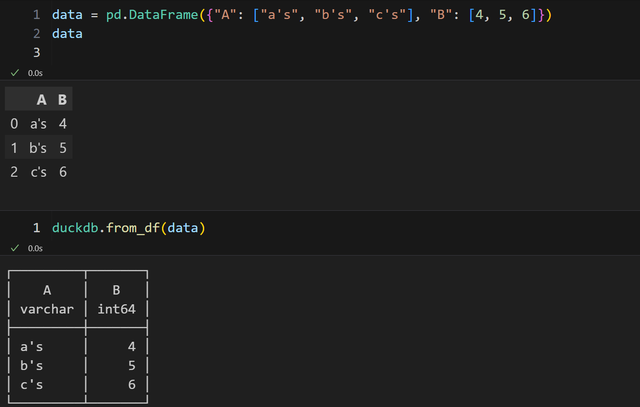
本身提供了许多 from 相关方法
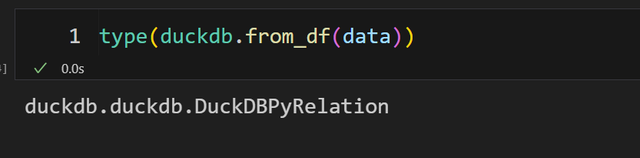
加载之后,得到的是一个叫 DuckDBPyRelation 对象。
我们可以利用它,把一个 sql 查询,拆分成一层层进行构建。比如,
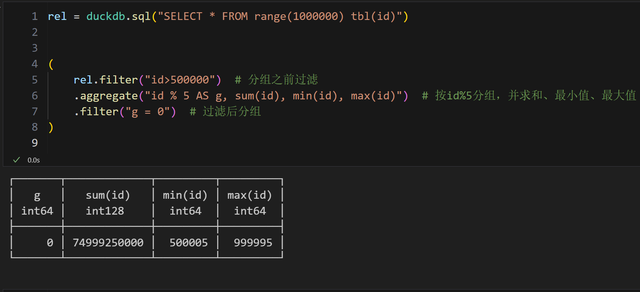
等价于:
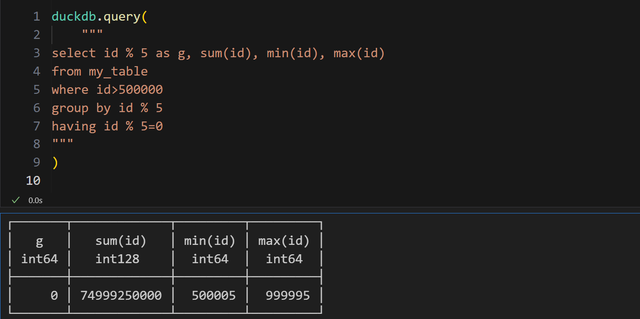
可以看到,其实关系函数构造的查询更加简洁。
当然,普通场景不会使用这种关系函数构造查询。它主要用于用户界面动态构造查询的场景。
那为什么说它是延迟执行呢?
如果我们把上面例子中的每一步都用单独的变量"拿住",但不打印:

不管数据有多少,它们都没有实际执行查询。直到你让某个关系对象输出。
在 jupyter notebook 环境,把关系对象放在单元格最后,则视为打印输出
比如,我们希望输出 g1 结果到 dataframe:
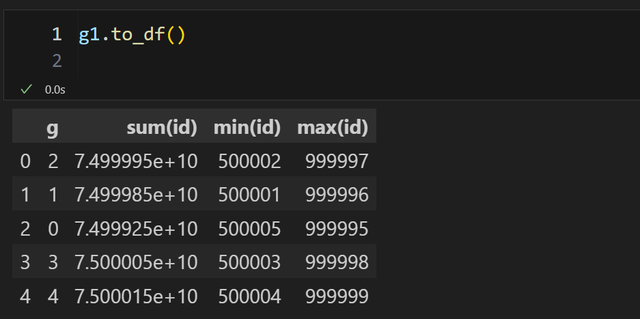
此时才会真正执行关系对象"积累" 下来的逻辑(上面逻辑中的 第一次 filter + 分组计算)
它们类似数据库的虚拟视图
值得一提的是,许多关系方法的参数,都可以传入前面说到的"表达式"对象。它们会经常被组合应用。
不要忘记一键三连。你的点赞、收藏、关注,是我创作的动力。
