
阿里妹导读
本文对比了几种常用缓存的特点,主要介绍了基于Guava的本地缓存和基于Tair的分布式缓存,包含快速入门和深入原理两部分,并在最后提供了使用缓存时需要注意的事项。
一、引言
在现代系统中,缓存作为增速减压的神兵利器被广泛使用,然而,缓存使用不当可能对系统造成严重影响。在大促期间,身边就出现一些由于缓存使用不当产生的后果:
案例一:压测流量脉冲至100%时,此时B端进行了配置变更,缓存失效。大量请求瞬间涌向数据库,且执行了无索引的查询,最终拖垮了数据库。案例二:在使用Tair缓存管理配置信息时,预发布环境进行了错误的配置修改。由于缓存未进行预发布与线上环境的隔离,错误配置直接影响了线上数据。面对上述案例,我认为非常有必要深入学习和理解缓存机制,以确保在实际使用中具备更完善的应对策略,避免类似问题的发生。
本文对比了几种常用缓存的特点,主要介绍了基于Guava的本地缓存和基于Tair的分布式缓存,包含快速入门和深入原理两部分,并在最后提供了使用缓存时需要注意的事项。如果有任何错误或建议,欢迎批评指正~
二、缓存的演进
缓存技术经历了从本地缓存到分布式缓存,再到多级缓存的不断演进。当开发人员发现系统性能瓶颈来自频繁的数据库操作时,通过将数据暂时缓存在本地,能够显著提升响应速度。当请求命中缓存时,可以直接返回结果;如果没有命中,则再进行数据库查询。这种基于本地缓存的优化显著提高了系统的整体性能。在Java项目中,有众多框架提供了强大的本地缓存支持,如Guava Cache、Ehcache和Caffeine Cache等。
随着业务集群的扩展,新的问题也随之出现:当多个节点同时存在时,因本地缓存各自在节点内独立构建,导致各业务节点间的数据一致性难以保证。为了解决这一难题,开发团队提出了集中式缓存的构想,让所有业务节点共享同一份缓存数据,从而高效解决了节点间数据不一致的问题。这一想法催生了分布式缓存的诞生,现如今,业界已经有多种成熟的集中式缓存解决方案,比如集团大规模使用的高速缓存Tair,以及大家熟知的Redis和Memcache等。
将本地缓存改成分布式缓存有效解决了缓存不一致问题和单机容量限制问题。但是,如果在系统中频繁地使用分布式缓存,网络IO交互次数的增加,可能并不能达到性能提成的目的。因此,我们可以将本地缓存与集中式缓存结合起来使用,取长补短,实现效果最大化。如图所示,演示了多级缓存的交互流程:

具体而言:
对于一些变更频率比较高的数据,采用集中式缓存,这样能够确保所有节点在数据变化后实时更新,从而保证数据的一致性。对于一些极少变更的数据(如系统配置项)或者是一些对短期一致性要求不高的数据(如用户昵称、签名等)则采用本地缓存,可以显著降低对远程集中式缓存的网络IO次数,提高系统性能。三、本地缓存
1. 缓存框架对比
Java项目中,几种广泛使用的高性能框架包括Guava Cache、Ehcache、Caffeine Cache等。
Guava:由Google团队开源的Java核心增强库,涵盖集合、并发原语、缓存、IO、反射等多种工具。其性能和稳定性有保障,广泛应用于各类项目中。Caffeine:基于Java 8实现的新一代缓存工具,可视作Guava Cache的升级版。虽然功能上两者相似,但Caffeine在性能表现和命中率上全面超越Guava Cache,卓越的表现令人瞩目。Ehcache:一个纯Java的进程内缓存框架,以其快速和轻量著称。同时,它支持内存和磁盘的二级缓存,让它在功能上更加丰富,且扩展性极强。下表总结了三个框架之间的对比,帮助大家在选择本地缓存解决方案时找到最合适的框架。

目前,我们的公司项目中广泛应用了Guava Cache框架。本文将以Guava Cache为例,进行深入介绍。
2. Guava Cache 快速入手
Step 1 :引入依赖
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>33.4.0-jre</version></dependency>Step 2 :容器创建
使用CacheBuilder及其提供的各种方法构建缓存容器(常见属性方法见附录)。
Cache<String, String> cache = CacheBuilder.newBuilder() .initialCapacity(1000) // 初始容量 .maximumSize(10000L) // 设定最大容量 .expireAfterWrite(30L, TimeUnit.MINUTES) // 设定写入过期时间 .concurrencyLevel(8) // 设置最大并发写操作线程数 .refreshAfterWrite(1L, TimeUnit.MINUTES) // 设定自动刷新数据时间 .recordStats() // 开启缓存执行情况统计 .build(new CacheLoader<String, User>() { @Override public User load(String key) throws Exception { return userDao.getUser(key); } });Step 3 :缓存使用
设置缓存// 1. put 往缓存中添加key-value键值对cache.put("key1", "value1");// 2. putAll 批量往缓存中添加key-value键值对Map<String, String> bulkData = new HashMap<>();bulkData.put("key2", "Value2");bulkData.put("key3", "Value3");cache.putAll(bulkData);获取缓存// 1. get 查询指定key对应的value值,如果缓存中没匹配,则基于给定的Callable逻辑去获取数据回填缓存中并返回String value1 = cache.get("key1", new Callable<String>() { @Override public String call() throws Exception { // 模拟从数据库或其他数据源获取数据 return "Value from Callable for key1"; }});// 2. getIfPresent 如果缓存中存在指定的key,返回对应的value,否则返回nullString value2 = cache.getIfPresent("key2");// 3. getAllPresent 针对传入的key列表,返回缓存中存在的对应value值列表List<String> keys = Arrays.asList("key1", "key2", "key3");Map<String, String> presentValues = cache.getAllPresent(keys);删除缓存 //1. invalidate - 从缓存中删除指定的记录cache.invalidate("key1");// 2. invalidateAll - 从缓存中批量删除指定记录,如果无参数,则清空所有缓存cache.invalidateAll(Arrays.asList("key2", "key3"));其他方法// 1. size 获取缓存容器中的总记录数Long size = cache.size();// 2. stats 获取缓存容器当前的统计数据CacheStats stats = cache.stats();// 3. asMap 将缓存中的数据转换为ConcurrentHashMap格式返回Map<String, String> cacheMap = cache.asMap();// 4. cleanUp - 清理所有的已过期的数据cache.cleanUp();3. Guava Cache 源码解析
3.1 缓存数据结构Guava Cache 的核心类 LocalCache 采用了与 ConcurrentHashMap 类似的数据结构,都是由多个相对独立的 segment 组成。且各segment相对独立,互不影响,所以能支持并行操作。segment 继承自 ReentrantLock,有效地减少了锁的粒度,从而提升了并发性能。每个 segment 包含一个哈希表和五个队列。
对于每一个segment放大如下:

这五个队列分别是:key和value的引用队列、读队列、写队列、访问队列以及最近使用队列。
缓存数据存储在table中,其类型为AtomicReferenceArray。该数组中的每个元素都是一个ReferenceEntry,每个entry包含了key及其hash值、value,以及指向下一个entry的指针。
3.2 get 方法源码当缓存过期时,为了防止大量的线程同时请求数据源加载数据并生成缓存项,造成 “缓存击穿” ,Guava在加载过程中实现了并发控制。当多个线程请求一个不存在或过期的缓存项时,只有一个线程会执行load方法。而其他线程则会根据构建时设置的expireAfterWrite 或expireAfterAccess 属性采取不同的处理策略。具体而言:
如果设置了expireAfterWrite 或expireAfterAccess ,其他线程将被阻塞,直到缓存项生成完毕。如果选择了refreshAfterWrite ,其他线程将不会被阻塞,而是直接返回旧的缓存值。下面代码为 get 方法的入口,通过 hash 值获取相应的段(segment ),然后从该段中提取具体的值。
LocalCache#get
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException { int hash = hash(checkNotNull(key)); // 根据 hash 获取对应的 segment 然后从 segment 获取具体值 return segmentFor(hash).get(key, hash, loader);}get方法的具体执行流程主要分为三步:
第一步:根据expireAfterAccess和expireAfterWrite判断值否过期,若未设置或者未过期,返回非空value。第二步:若value不为空,根据refreshAfterWrite设置的参数,判断否需要异步刷新。如果判断到loading中就会返回旧值。第三步:如果之前没有写入过数据或者数据已经过期或者数据不是在加载中,则会调用lockedGetOrLoad。此时会加锁,并根据是否处于加载状态来决定是阻塞等待还是直接获取数据。整体执行流程如下:

对应的get方法代码部分如下:
Segment#get
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException { checkNotNull(key); checkNotNull(loader); try { // count 表示在这个segment中存活的项目个数 if (count != 0) { // 获取segment中的元素, 包含正在load的数据 ReferenceEntry<K, V> e = getEntry(key, hash); if (e != null) { // 获取当前时间,纳秒 long now = map.ticker.read(); // 获取缓存值,判断是否过期,过期删除缓存并返回null V value = getLiveValue(e, now); // 拿到没过期存活的数据 if (value != null) { // 记录访问时间 recordRead(e, now); // 记录缓存命中一次 statsCounter.recordHits(1); // 刷新缓存并返回缓存值 return scheduleRefresh(e, key, hash, value, now, loader); } // 走到这步,说明取出来的值 value == null, 可能是过期了,也有可能正在刷新 ValueReference<K, V> valueReference = e.getValueReference(); // 如果此时value正在loading,那么此时等待刷新结果 if (valueReference.isLoading()) { return waitForLoadingValue(e, key, valueReference); } } } // 走到这说明值为null或者过期,需要加锁进行加载 return lockedGetOrLoad(key, hash, loader); } catch (ExecutionException ee) { Throwable cause = ee.getCause(); if (cause instanceof Error) { throw new ExecutionError((Error) cause); } else if (cause instanceof RuntimeException) { throw new UncheckedExecutionException(cause); } throw ee; } finally { postReadCleanup(); }}getLiveValue 方法用于判断缓存是否过期。如果缓存已过期,则会删除相应的缓存并返回 null;如果缓存未过期,则返回当前的缓存值。
Segment#getLiveValue
V getLiveValue(ReferenceEntry<K, V> entry, long now) { //被GC回收了 if (entry.getKey() == null) { // tryDrainReferenceQueues(); return null; } V value = entry.getValueReference().get(); //被GC回收了 if (value == null) { tryDrainReferenceQueues(); return null; } //判断是否过期 if (map.isExpired(entry, now)) { tryExpireEntries(now); return null; } return value; } //isExpired,判断Entry是否过期 boolean isExpired(ReferenceEntry<K, V> entry, long now) { checkNotNull(entry); //如果配置了expireAfterAccess,用当前时间跟entry的accessTime比较 if (expiresAfterAccess() && (now - entry.getAccessTime() >= expireAfterAccessNanos)) { return true; } //如果配置了expireAfterWrite,用当前时间跟entry的writeTime比较 if (expiresAfterWrite() && (now - entry.getWriteTime() >= expireAfterWriteNanos)) { return true; } return false; }scheduleRefresh 方法会根据 refreshAfterWrite 参数的设置,判断是否需要进行异步刷新。
Segment#scheduleRefresh
V scheduleRefresh( ReferenceEntry<K, V> entry, K key, int hash, V oldValue, long now, CacheLoader<? super K, V> loader) { if ( // 配置了刷新策略 refreshAfterWrite map.refreshes() // 到刷新时间了 && (now - entry.getWriteTime() > map.refreshNanos) // 没在 loading && !entry.getValueReference().isLoading()) { // 开始刷新 V newValue = refresh(key, hash, loader, true); if (newValue != null) { return newValue; } } return oldValue;}如果之前没有写入过数据 || 数据已经过期 || 数据不是在加载中,则会调用lockedGetOrLoad 方法。
Segment#lockedGetOrLoad
V lockedGetOrLoad(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException { ReferenceEntry<K, V> e; ValueReference<K, V> valueReference = null; LoadingValueReference<K, V> loadingValueReference = null; boolean createNewEntry = true; // 要对 segment 写操作 ,先加锁 lock(); try { long now = map.ticker.read(); preWriteCleanup(now); // 这里基本就是 HashMap 的代码,如果没有 segment 的数组下标冲突了就拉一个链表 int newCount = this.count - 1; AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table; int index = hash & (table.length() - 1); ReferenceEntry<K, V> first = table.get(index); for (e = first; e != null; e = e.getNext()) { K entryKey = e.getKey(); if (e.getHash() == hash && entryKey != null && map.keyEquivalence.equivalent(key, entryKey)) { valueReference = e.getValueReference(); //如果value在加载中则不需要重复创建entry if (valueReference.isLoading()) { createNewEntry = false; } else { V value = valueReference.get(); // 如果缓存项为 null 数据已经被删除,通知对应的 queue if (value == null) { enqueueNotification( entryKey, hash, value, valueReference.getWeight(), RemovalCause.COLLECTED); // 这个是 double check 如果缓存项过期 数据没被删除,通知对应的 queue } else if (map.isExpired(e, now)) { // This is a duplicate check, as preWriteCleanup already purged expired // entries, but let's accommodate an incorrect expiration queue. enqueueNotification( entryKey, hash, value, valueReference.getWeight(), RemovalCause.EXPIRED); // 再次看到的时候这个位置有值了直接返回 } else { recordLockedRead(e, now); statsCounter.recordHits(1); return value; } // immediately reuse invalid entries writeQueue.remove(e); accessQueue.remove(e); this.count = newCount; // write-volatile } break; } } // 没有 loading ,创建一个 loading 节点 if (createNewEntry) { loadingValueReference = new LoadingValueReference<>(); if (e == null) { e = newEntry(key, hash, first); e.setValueReference(loadingValueReference); table.set(index, e); } else { e.setValueReference(loadingValueReference); } } } finally { unlock(); postWriteCleanup(); } //同步加载数据。 if (createNewEntry) { try { synchronized (e) { return loadSync(key, hash, loadingValueReference, loader); } } finally { statsCounter.recordMisses(1); } } else { // The entry already exists. Wait for loading. return waitForLoadingValue(e, key, valueReference); }}通过分析get的流程图和源码,我们可以了解到在执行get时,会先检查缓存是否过期,然后再判断是否需要执行refresh。如果缓存已过期,系统将优先调用load方法,此时会阻塞其他线程。相反,当缓存未过期但时间超过refresh设定时,系统将异步执行reload,同时返回旧值。因此,推荐的配置是将refresh设置为小于expire。这样的设置不仅可以确保在长时间未访问缓存后获取到最新的值,还能避免因refresh返回旧值而导致的数据不一致问题。
3.3 put 方法源码put的操作相对简单。在执行put操作时,Guava首先会计算出key的hash值,随后根据该hash值确定数据应写入哪个Segment。接着,系统会对选定的Segment进行加锁,以确保安全地执行写入操作。
@Overridepublic V put(K key, V value) { // ... 省略部分逻辑 int hash = hash(key); return segmentFor(hash).put(key, hash, value, false);}@NullableV put(K key, int hash, V value, boolean onlyIfAbsent) { lock(); try { // ... 省略具体逻辑 } finally { unlock(); postWriteCleanup(); }}四、分布式缓存
1. 缓存选型对比
目前三种比较成熟的分布式缓存对比如下:
特性 / 框架
Tair
Redis
Memcached
数据结构支持
基于 Redis,支持其所有数据结构,并扩展了更多功能
支持多种数据结构,如字符串、哈希、列表、集合、有序集合等
仅支持简单的键值对存储
持久化
支持持久化,确保数据安全性
支持 RDB 和 AOF 持久化
不支持持久化
高可用性
内建高可用性机制,提供自动故障转移和数据备份
支持主从复制、哨兵和集群模式
通过客户端实现简单复制
分布式支持
原生支持分布式架构,易于大规模扩展
通过 Cluster 模式实现分布式
通常依赖客户端进行分片,分布式支持较为基础
性能
性能与 Redis 相当,同时提供更多优化和企业级特性
单线程模型性能出色,适合复杂操作
高性能,适用于简单的缓存读取和写入
扩展性
支持大规模水平扩展,适应企业级业务增长需求
水平扩展有限,需通过集群管理进行扩展
易于水平扩展,适合大规模分布式缓存需求
社区支持
社区较小,但由阿里巴巴维护,提供企业级支持
拥有广泛的社区和丰富的文档资源
社区活跃,资源丰富
优点
采用分布式集群架构,具备自动容灾及故障迁移能力,对存储层做了抽象,底层方便切换不同的存储引擎,采用一致性哈希算法将key分散在Q个桶中,并将桶放到不同的dataserver上,保证数据平衡,tair高可用比较强,容灾性比redis强,支持多种集群结构,支持跨机房数据分布
非常丰富的数据结构而且都是原子性操作、高速读写、支持事务,支持aof、rdb两种持久化机制,拥有丰富特性,订阅发布 Pub / Sub 功能、Key 过期策略、事务、支持多个 DB、计数、支持集群和数据备份
简洁,灵活,多线程非阻塞io效率高,所有支持多种语言api,且在并发下用cas保证一致性
缺点
文档不全,社区不活跃,单节点上性能没有redis高,不能对key实现模糊查询,单条数据不能太大key建议1k以下,value不能超过1M,建议10k以下
3.0以前不支持集群,单线程无法充分利用多核服务器CPU,事务支持较弱,rdb每次都是写全量数据,成本高,aof追加导致log特别大
结构单一,数据在内存重启会丢失,数据大小受内存限制
本文以公司广泛使用的高性能、高扩展、高可靠Tair为例展开介绍。
2. Tair 快速入手
以MDB/LDB为例展开介绍,Tair接入大概需要四步。
Step 1 :申请Tair实例
申请地址:http://tiddo.alibaba-inc.com/saas-tair/#/InstanceGroupList

需要重点关注的参数:
ConfigID:用来唯一表示一个Tair集群,一般存放在diamond中。configID方式Tair已经不推荐使用,因为采用configID方式初始化时,由于线上线下集群往往不同,需要维护线上线下不同的配置项。UserName:新版配置,表示一个实例组,所有环境的同一用户空间使用username方式,线上线下统一Step 2 :引入依赖
<dependency> <groupId>com.taobao.tair</groupId> <artifactId>tair-mc-client</artifactId> <version>4.4.12</version></dependency>JAR包说明:MDB&LDB JAVA客户端有2个包,tair-mc-client和tair-client。tair-client是MDB&LDB客户端和服务端服务交互的核心库,tair-mc-client依赖tair-client,引入Diamond中间件,通过Diamond上的集群配置,决定客户端链接具体哪个MDB/LDB集群。因此,tair-mc-client是具有容灾功能的客户端。
官方强制要求用户直接依赖tair-mc-client,而不要直接依赖tair-client库。
Step 3 :初始化
MultiClusterTairManager mcTairManager = new MultiClusterTairManager();mcTairManager.setUserName("申请到的实例组名称");mcTairManager.setDynamicConfig(true); // mcTairManager.setTimeout(500); // 单位为 ms,默认 2000 msmcTairManager.init();Step 4 :缓存使用
// get方法// namespace,申请时分配的namespace,// key大小不超过1kResult<DataEntry> result = tairManager.get(NAME_SPACE, key);// put方法,写入数据,设置版本号和过期时间// 当version为0时,表示强制更新。// 当version为非0时,则判断服务端的version和客户端传入的version是否一致,不一致则返回 ResultCode code = tairManager.put(NAME_SPACE, key, value, 0, expireTime);// delete方法,删除本集群指定key。// 目前不支持批量删除keyResultCode code = tairManager.delete(NAME_SPACE, key);3. Tair 原理解析
3.1 整体架构Tair共有四个模块,包括三个必选模块:client、configserver和dataserver。一个可选模块:invalidserver。
 configServer :注册中心,感知存储dataserver节点通过维护和dataserver心跳来获知集群中存活节点的信息根据存活节点的信息来构建数据在集群中的分布表提供数据分布表的查询服务调度dataserver之间的数据迁移、复制dataServer:数据存储节点提供存储引擎接受client的put/get/remove等操作执行数据迁移,复制等插件:在接受请求的时候处理一些自定义功能访问统计client:客户端调用在应用端提供访问Tair集群的接口更新并缓存数据分布表和invalidserver地址等LocalCache,避免过热数据访问影响tair集群服务流控invalidServer:控制同一组内数据一致性接收来自client的invalid/hide等请求后,对属于同一组的集群(双机房独立集群部署方式)做delete/hide操作,保证同一组集群的一致集群断网之后的,脏数据清理。访问统计3.2 底层存储引擎对比
configServer :注册中心,感知存储dataserver节点通过维护和dataserver心跳来获知集群中存活节点的信息根据存活节点的信息来构建数据在集群中的分布表提供数据分布表的查询服务调度dataserver之间的数据迁移、复制dataServer:数据存储节点提供存储引擎接受client的put/get/remove等操作执行数据迁移,复制等插件:在接受请求的时候处理一些自定义功能访问统计client:客户端调用在应用端提供访问Tair集群的接口更新并缓存数据分布表和invalidserver地址等LocalCache,避免过热数据访问影响tair集群服务流控invalidServer:控制同一组内数据一致性接收来自client的invalid/hide等请求后,对属于同一组的集群(双机房独立集群部署方式)做delete/hide操作,保证同一组集群的一致集群断网之后的,脏数据清理。访问统计3.2 底层存储引擎对比注意,由于MDB&LDB是由Tair团队研发并维护多年,集团用户通常将MDB&LDB称为Tair。由于现在MDB&LDB已经不在Tair团队,因此不再挂Tair品牌名称。仅称为MDB&LDB。Tair表示对外的云原生内存数据库Tair,也就是Redis企业版。不过,为了方便介绍,本文仍然将三者放在一起对比:
从性能上来说,MDB > LDB > RDB,但是相应的从数据可靠性来说MDB < LDB < RDB。所以MDB的使用场景一般要有兜底的方案,比如查不到mdb缓存数据时通过查询其他数据源可以获取。
特性 / 框架
MDB
LDB
RDB
产品特性
Memcache,Tair 1.0产品,Tair最早的一款产品,专注于内存型KV极速缓存。
levelDB,Tair 1.0产品,Tair第二款产品,专注于持久化型KV高速缓存。
Tair 3.0产品,同时服务集团内部和公有云用户,全面支持业务上云。
支持数据结构
Key-Value
Key-Value
String,List,Zset,Hmap,Set等复杂数据结构。
优点
高读写性能,适用容量小,读写QPS高(万级别)的缓存场景。
LDB 适用于确实有持久化需求,读写QPS较高(万级别)的应用场景。
有丰富的数据结构,支持Redis原生的数据结构,也支持自研的高级数据结构。
缺点
类似于Memcache,由于是内存型产品,因此无法保证数据的安全性,
LDB目前线上使用的SSD机型成本较高
不适合大吞吐场景,即缓存Key不应过大,
分布式支持较为基础
应用场景
可接受数据丢失场景,比如经典缓存场景,临时可丢失数据场景。
持久化KV场景,比如黑白名单,离线数据在线化等
应用场景覆盖新零售,游戏,教育,文化产品,制造业,交通物流,互联网社交等行业。
管控平台
Tiddo 1.0
Tiddo 1.0
诺曼底
3.3 Tair的数据一致性—Version支持在PUT接口中,有一个version参数,用于解决并发更新同一数据的问题。通常,更新数据的过程是先进行GET获取数据,然后修改后再PUT回系统。如果多个客户端同时获取同一份数据并进行修改,后到达的修改可能会覆盖先保存的内容,从而导致数据丢失。为防止这种情况,设置了version参数。
服务器端的version初始值为0,第一次PUT时version增加至1,后续每次更新时version再加1。每次GET请求时,服务器会返回当前数据的版本,只有当更新接口中传入的version与当前版本相同时,更新才会成功。如果在GET与更新之间数据已被更改,导致版本不一致,更新会失败并返回ResultCode.VERERROR。源码的处理流程如下:

注意:如果应用不关心并发更新的一致性,调用客户端接口时,version必须不传或者传入0。
3.4 Tair的负载均衡tair 的分布采用的是一致性哈希算法,用来解决分布式中的平衡性、分散性和一致性。对于所有的 key,分到 Q 个桶中,桶是负载均衡和数据迁移的基本单位。config server 根据一定的策略把每个桶指派到不同的 data server 上,因为数据按照 key 做 hash 算法,所以可以认为每个桶中的数据基本是平衡的,保证了桶分布的均衡性, 就保证了数据分布的均衡性。
具体说,首先计算 Hash(key),然后通过一些运算,比如取模运算,得到 key 所对应的 bucket,然后再去 config server 查找该 bucket 对应的 data server,再与相应的 data server 进行通信。也就是说,config server 维护了一张由 bucket 映射到 data server 的对照表。如:

这里共 6 个 bucket,由两台机器负责,每台机器负责 3 个 bucket。客户端将 key hash 后,对 6 取模,找到负责的数据节点,然后和其直接通信。表的大小(行数)通常会远大于集群的节点数,这和 consistent hash 中的虚拟节点很相似。假设我们加入了一台新的机器: 192.168.10.3,tair 会自动调整对照表,将部分 bucket 交由新的节点负责,比如新的表很可能类似下表:
 3.5 热点散列策略
3.5 热点散列策略由于Tair访问方式是客户端对请求的Key进行类一致性 Hash 计算后,再通过数据路由表查表定位到某台DataServer(数据节点服务器)进行读写的,所以对相同Key的读写请求必然固定映射到相同的DataServer上,如图。
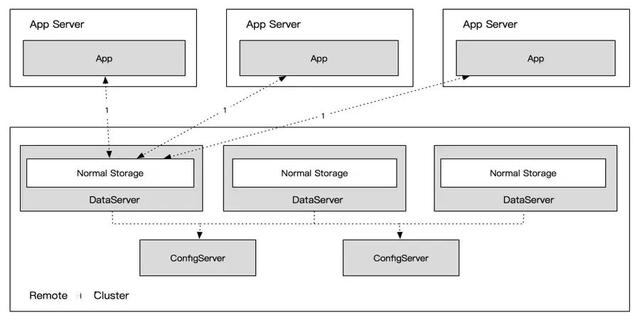
此时DataServer单节点的读写性能便成了单Key的读写性能瓶颈,且无法通过简单的水平扩展来解决。针对此问题,解决方案分为三部分:热点识别、读热点方案和写热点方案。
热点识别
DataServer收到客户端的请求后,每个处理请求的工作线程(Worker Thread)用来统计热点的数据结构都是ThreadLocal的数据结构,完全无锁化设计。热点获取使用精心设计的多级加权LRU链和HashMap组合的数据结构,在保证服务端请求处理效率的前提进行请求的全统计。
读热点方案
在DataServer中,设立了一个HotZone,用于存储热点数据。在客户端初始化时,会获取散列的机器配置信息,并随机选择一台DataServer作为固定的热点数据读写HotZone。当数据被识别为热点时,客户端会优先从HotZone进行读取;如果读取失败,则会按照原有路由方式访问源DataServer。与此同时,系统会通过异步方式将新数据更新到HotZone,从而实现HotZone与源DataServer之间的二级缓存。
这种机制有效地将热点数据的查询压力分散到多个HotZone,显著提升了系统的水平扩展能力。

写热点方案
对于写热点,一致性问题使多级缓存方案难以适用。使用本地缓存并异步更新远端数据库时,如果业务机器宕机,则已写数据可能丢失。此外,本地缓存导致某应用机器的更新对其他机器不可见,从而延长数据不一致的时间。因此,写热点采用服务端请求合并的方法(类似Group Commit机制)。
热点Key的写请求由IO线程转发到专门的合并线程,后者在一定时间内合并写请求,然后由定时线程按预设周期提交请求。合并过程中请求结果不返回客户端,待写入成功后再统一返回,避免了一致性问题及假写情况。合并周期可在服务端配置并动态修改。
五、缓存注意事项
多级缓存的运用能够显著提升系统性能和响应速度,但其设计与实现并不是一件简单的事情。在实施过程中,需关注一些关键因素,以确保缓存的有效性和稳定性。其中两个比较关键的问题则为缓存一致性问题和缓存并发性问题。
1. 缓存一致性问题
在多级缓存架构的应用中,数据一致性问题至关重要。由于不同级别的缓存可能存储相同数据的不同副本,数据更新时,必须有效同步各个缓存层。对此,我们需要关注以下两个关键点:
追求最终一致性而非强一致性:在数据库与缓存的读写流程中,推荐的旁路型缓存策略是,首先更新数据库,然后删除相关缓存。这一方法能有效确保数据的最终一致性,并降低极端情况下数据不一致的风险。缓存必须要有过期时间:为缓存设定过期时间不仅可以提高命中率,更是一种有效的兜底策略。当数据库与缓存数据出现不一致时,只有在数据不一致的短时间内,不同的数据状态存在。这一机制也有助于保证最终一致性。2. 缓存并发问题
在高并发场景下,可能会有大量请求绕过缓存,直接访问数据库,造出数据库瘫痪等,例如致缓存雪崩、缓存穿透、缓存击穿等问题。
缓存雪崩
当大量甚至全部的缓存数据在短时间内集体失效,这样会导致大量的请求无法命中缓存而直接流转到了下游模块,导致系统瘫痪,也即缓存雪崩。
解决方案:
从应用架构角度,可以通过限流、降级、熔断等手段来降低影响,也可以通过多级缓存来避免这种灾难。从缓存的角度考虑,可以通过将缓存过期的时间随机打散来有效的避免数据集中失效,或者可以设计延迟失效策略,分散对后端存储的访问压力。缓存击穿
少量缓存失效的时候恰好失效的数据遭遇大并发量的请求,导致这些请求全部涌入数据库中。
解决方案:
为热点数据设置一个过期时间续期的操作,比如每次请求的时候自动将过期时间续期一下。借助分布式锁来防止缓存击穿问题的出现。当缓存不可用时,仅持锁的线程负责从数据库中查询数据并写入缓存中,其余请求重试时先尝试从缓存中获取数据,避免所有的并发请求全部同时打到数据库上。设置热点数据永远不过期,定时去更新最新数据。缓存穿透
大量请求的 key 是不合理的,根本不存在于缓存中,也不存在于数据库中 。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力。如某个黑客故意制造一些非法的 key 发起大量请求,导致大量请求落到数据库,结果数据库上也没有查到对应的数据。
解决方案:
缓存无效 key使用布隆过滤器六、附录
CacheBuilder中常见属性方法
方法
含义说明
newBuilder
构造出一个Builder实例类
initialCapacity
待创建的缓存容器的初始容量大小(记录条数)
maximumSize
指定此缓存容器的最大容量(最大缓存记录条数)
maximumWeight
指定此缓存容器的最大容量(最大比重值),需结合weighter方可体现出效果
weighter
入参为一个函数式接口,用于指定每条存入的缓存数据的权重占比情况。
需要与maximumWeight结合使用
expireAfterWrite
设定过期策略,按照数据写入时间进行计算(非自动失效,需有任意put/replace之类方法才会扫描过期失效数据))
expireAfterAccess
设定过期策略,按照数据最后访问时间来计算(非自动失效,需有任意get/put之类方法才会扫描过期失效数据)
refreshAfterWrite
设定更新策略,数据写入后多久刷新 (异步刷新,非自动失效,需有任意put、replace之类方法才会扫描过期失效数据。但区别是会开一个异步线程进行刷新,刷新过程中访问返回旧数据)
concurrencyLevel
用于控制缓存的并发处理能力,同时支持多少个线程并发写入操作
recordStats
设定开启此容器的数据加载与缓存命中情况统计
引用MBD/LDB文档:https://alidocs.dingtalk.com/i/nodes/N7dx2rn0JbxOaqnACmlYG4YQWMGjLRb3
Tair(Redis企业版)产品文档:https://alidocs.dingtalk.com/i/nodes/Qnp9zOoBVBDEydnQUONBD3qn81DK0g6l
深入理解缓存原理与实战设计:https://juejin.cn/column/7140852038258147358
